






cut命令
-b:以字节进行切割
-c:以字符切割
-d:指定分割服
-f:搭配-d使用指定显示那个区域

sort:字段排序
-n:使用数字排序
-t:指定分隔符
-k:搭配-t使用,指定排序的区域
-u:去重
-o:排序结果写入文件中而且标准输出
-r:反向排序
-f:忽略大小写

uniq:去重,相邻行才可以去重 搭配sort使用
-c:统计重复的次数
-d:输出重复的行
-i:忽略大小写
-u:只显示唯一的行
-w N:每行的第N个字符之后不再比较
-s N:跳过前面N个字符开始比较

wc:统计文件中的字数 字符数 行数等等等
-L:打印最长行的长度
-l:行数
-c:字节数
-w:字数
-m:字符数

head:显示文件的前几行
-n num:显示前几行

tail:显示文件的最后行,监控日志增长
-n num:显示最后几行
-f:随着文件行数增加,逐行显示增加的行

文本过滤工具
grep:
grep [OPTIONS] PATTERN [FILE…]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE…]
–color=auto 对匹配到的文本进行高亮显示
-E:支持使用扩展正则表达式
-i:忽略大小写
-o:仅仅显示匹配到的字符串本身
-n:显示行号
-v:显示不能被匹配到的行
-A num:后num行
-B num:前num行
-C num:前后num行
正则表达式:由一类特殊的字符以及文本进行编写的模式,这些字符并不代表字面意思,而是代表通配或者
控制的功能
分类:
基本正则表达式
正则表达式元字符:
字符匹配
.:匹配任意单个字符
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单子字符
匹配次数:指定其前面的字符出现多少次
*:匹配前面字符任意次,0,1,多次
.*:匹配任意长度的任意字符
\?:匹配其前面的字符0次或者1次
\+:匹配其前面的字符1次或者多次
\{m\}:匹配其前面的字符m次
\{m,n\}:匹配其前面的字符至少m次,至多n次
\{0,n\}:匹配其前面的字符至多n次
\{m,\}:匹配其前面的字符至少m次
位置锚地
^:行首锚定
$:行尾锚定
^$:空白行 ^[[:space:]]*$
^pattern$:用pattern匹配完整的行
\b 或者 \<:词首锚定
\b 或者 \>:词尾锚定
\<word\>:匹配单词
分组和引用
\(\(\)\)\(\)
\1:从模式的最左侧起,第一个左括号以及与之匹配的右括号之间的内容
\2:从模式的最左侧起,第二个左括号以及与之匹配的右括号之间的内容
\3:从模式的最左侧起,第三个左括号以及与之匹配的右括号之间的内容

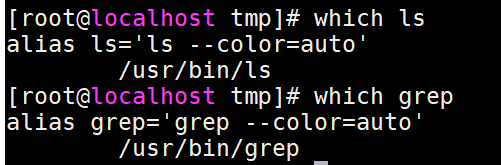
which:查找命令的可执行文件,以及别名,依赖于PATH环境变量
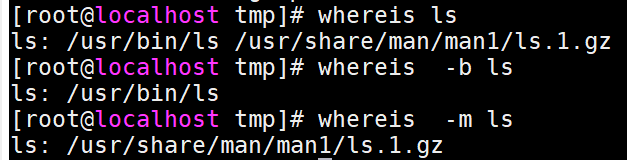
whereis:查找命令的可执行文件,以及命令的man帮助手册
-b:只查找可执行文件
-m:只查找帮助文档
locate:查找系统中的文件,基于数据库查找 yum install mlocate -y
新装之后,需要构建数据库 手工构建数据库 updatedb /var/lib/mlocate/mlocate.db
模糊查找,非实时查找,查找速度快
-b:只匹配基名
-c:统计有多少个符合条件的文件















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









