









目录
注意事项
注意:本文代码来源《深度学习框架PyTorch:入门与实践》,点击书名跳转到对应GitHub获得完整代码。
作为从TensorFlow转到PyTorch的小白,本文旨在记录该项目主要代码的含义,以及一些Python语句的详细分析,方便自己复习,如果能帮到准备入门PyTorch的同学当然更好。
主要环境配置:博主使用Python3。
读者需要提前准备:RNN相关知识自行学习,推荐李宏毅的课;具有一定的Python基础,比如numpy等。博主仅记录个人认为较关键部分,所以可能需要读者自行查阅部分语句含义。
一、数据介绍
原作者采用tang.npz文件存储数据,简单观察数据是什么:
data = np.load('Path/tang.npz', allow_pickle=True)
data, word2ix, ix2word = data['data'], data['word2ix'].item(), data['ix2word'].item()
数据文件中有三个数据,data的shape为(57580, 125),每一行是长度为125的诗句(原始诗句不足125的前面补空格,超过的截断);
word2ix如下:
{'憁': 0,
'耀': 1,
'枅': 2,
'涉': 3,
'谈': 4,
...
'苞': 997,
'忠': 998,
'筣': 999,
...}
也就是每个汉字对应的编号。
ix2word如下:
{0: '憁',
1: '耀',
2: '枅',
3: '涉',
4: '谈',
...
997: '苞',
998: '忠',
999: '筣',
...}
也就是每个编号对应的汉字。
二、opt对象
这个是main.py的内容,放在开头讲是因为opt贯穿整个项目。
class Config(object):
data_path = 'data/'
pickle_path = 'tang.npz'
author = None
constrain = None
category = 'poet.tang'
lr = 1e-3
weight_decay = 1e-4
use_gpu = False
epoch = 20
batch_size = 128
maxlen = 125
plot_every = 20 # 每20个batch 可视化一次
# use_env = True # 是否使用visdom
env = 'poetry'
max_gen_len = 200 # 生成诗歌的最长长度
debug_file = '/tmp/debugp'
model_path = None
prefix_words = None # 控制生成诗歌的意境
start_words = ''
acrostic = False # 是否为藏头诗
model_prefix = 'checkpoints/tang' # 模型保存路径
opt = Config()
opt中有很多配置,需要使用的时候就通过opt调用。
三、data.py
此文件比较长,但很多是处理json文件的。作者提供的tang.npz就是处理的成品,利用此文件,则只需理解如下代码:
def get_data(opt):
"""
@param opt 配置选项 Config对象
@return word2ix: dict,每个字对应的序号,形如u'月'->100
@return ix2word: dict,每个序号对应的字,形如'100'->u'月'
@return data: numpy数组,每一行是一首诗对应的字的下标
"""
# if os.path.exists(opt.pickle_path):
data = np.load(opt.pickle_path, allow_pickle=True)
data, word2ix, ix2word = data['data'], data['word2ix'].item(), data['ix2word'].item()
return data, word2ix, ix2word
此函数用来导入数据,获得data,word2ix,ix2word。
四、☆model.py
这里是用torch定义模型。
需要先了解embedding:
#coding:utf8
import torch as t
from torch import nn
# 一共12个词,每个词用5维词向量表示
embedding = t.nn.Embedding(12, 5)
# 定义一个3×4的Tensor,
# 通俗理解为4个句子,每个句子3个词;
# 或者含义为输入序列长度为3,batch_size为4
input = t.arange(0, 12).view(3, 4).long()
input = t.autograd.Variable(input)
output = embedding(input)
print(output.size())
print(embedding.weight.size())
输出为
torch.Size([3, 4, 5])
torch.Size([12, 5])
第一行含义为output的size,序列长度为3,batch_size为4,每个词用5维词向量表示;
第二行含义为embedding的权重(num_words, embedding_dim),这个权重是可以训练的。一共有12个词,本来应该用12维one-hot向量来表示一个词,现在被embedding降维成用5维词向量。这样做的好处有两点:
- 原来的one-hot向量维度取决于词的数量,如果词太多,会造成“维度灾难”。embedding的降维可以适当解决这个问题;
- 原来的one-hot向量,只有一个维度是1,其余维度是0,就导致不同的词向量彼此正交,从而任意两词不相关、任意两词之间距离都一样。新的词向量不是这样,并且包含了更合理的语义信息:
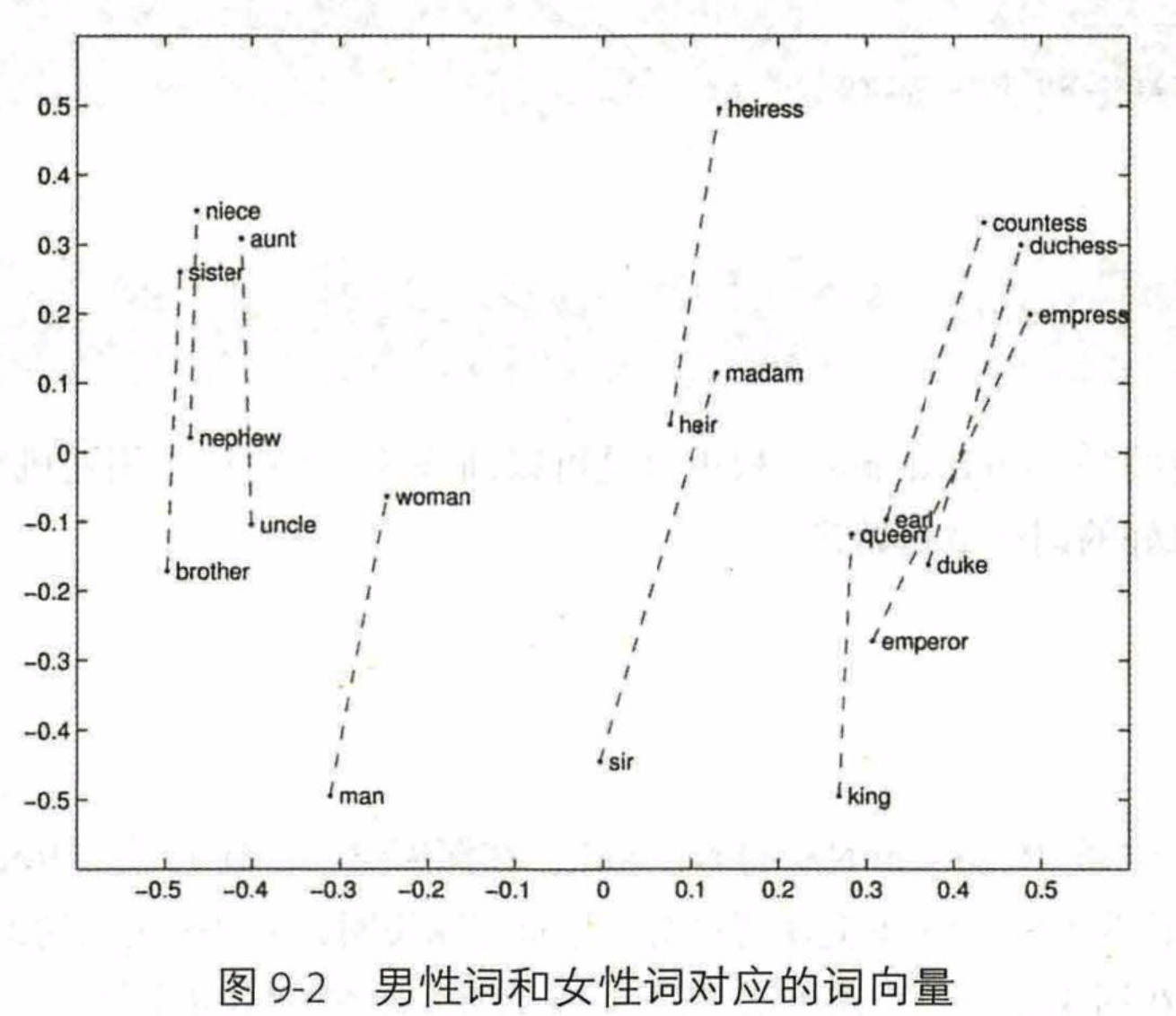
(图源《深度学习框架PyTorch:入门与实践》)上图是用embedding获得的二维词向量的例子,可以发现从有向距离来看,国王-女王≈男人-女人,国王-男人≈女王-女人,即“国王可以看做男性君主,女王可以看做女性君主。国王减男性,只剩下君主的特征;女王减女性,也只剩下君主的特征”,这样一来,足以说明embedding所得的词向量,其具备的特征相较于one-hot词向量的优越性。
回到项目,我们还需要了解LSTM代码,推荐知乎回答理解Pytorch中LSTM的输入输出参数含义,通过此文,你现在了解了torch.nn.LSTM的输入输出参数的size及其含义,我们可以直接摆出model.py的代码:
(通过上述链接,你需要自行学习下列代码中的embedding_dim,hidden_dim,num_layers,h_0,c_0,input,output,hidden的含义,十分简单,博主不赘述)
import torch.nn as nn
class PoetryModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
# super(PoetryModel, self).__init__() # python2是这样的
super().__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2)
# 注意这一层用法在倒数第二行代码那里讲
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
# input为[seq_len, batch_size]
seq_len, batch_size = input.size()
# 如果没有传入hidden,那么就新建
if hidden is None:
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
else:
h_0, c_0 = hidden
# size: (seq_len,batch_size,embedding_dim)
# 特别注意input的size:(seq_len,batch_size)
embeds = self.embeddings(input)
# output size: (seq_len,batch_size,hidden_dim)
output, hidden = self.lstm(embeds, (h_0, c_0))
# output size通过这一层的变化: (seq_len*batch_size,hidden_dim)变为(seq_len*batch_size,vocab_size)
# view作用是将output size从(seq_len,batch_size,hidden_dim)变为(seq_len*batch_size,hidden_dim)
output = self.linear1(output.view(seq_len * batch_size, -1))
return output, hidden
这样,我们就定义好了一个模型,PyTorch就是这么简单 。
五、utils.py封装可视化操作,略
仅说明这个文件的作用,好像和入门PyTorch没有关系,所以不讲。
六、main.py
先从最重要的训练函数讲起:
了解torch.utils.data.DataLoader()的大致作用:
import torch as t
from tqdm import tqdm # 用来显示进度条的东西
data = np.array([[1,1,1,1],
[2,2,2,2],
[3,3,3,3],
[4,4,4,4],
[5,5,5,5],
[6,6,6,6]])
dataloader = t.utils.data.DataLoader(data,
batch_size=2,
shuffle=False,
num_workers=1)
for i, data_ in enumerate(tqdm(dataloader)):
print(i)
print(data_)
运行结果如下:
100%|██████████| 3/3 [00:00<00:00, 99.15it/s]
0
tensor([[1, 1, 1, 1],
[2, 2, 2, 2]])
1
tensor([[3, 3, 3, 3],
[4, 4, 4, 4]])
2
tensor([[5, 5, 5, 5],
[6, 6, 6, 6]])
分析运行结果,原数据的shape是(6, 4),设置batch_size为2,表示数据被分为3个batch,这样就循环3次,每次输出一个batch。关于上述代码中的tqdm,和enumerate结合起来是用来显示进度条的。
注意torch.nn.CrossEntropyLoss()输入参数的size
在torch.nn.CrossEntropyLoss()(output, target)中,output和target的size是不一样的。output是类别概率分布,而target是类别的值,而不是类别的one-hot编码。
完整的train函数
下面给出完整的train函数,部分语句含义在注释中有讲解:
def train(**kwargs):
# 遍历字典,传参。这里用于设置opt中的变量值
for k, v in kwargs.items():
# setattr(self,k,v)相当于self.k = v。(setattr(object, name, value))
setattr(opt, k, v)
# 如果使用GPU的话
opt.device = t.device('cuda') if opt.use_gpu else t.device('cpu')
device = opt.device
# 这个是utils.py中定义的可视化
vis = Visualizer(env=opt.env)
# 获取数据
# data为(57580, 125)的numpy数组,每首诗超过125丢弃,不足125补空格
data, word2ix, ix2word = get_data(opt)
# 将data转化为tensor
data = t.from_numpy(data)
# 加载数据用的,其中会设置batch_size等重要参数,shuffle意思是打乱数据顺序
dataloader = t.utils.data.DataLoader(data,
batch_size=opt.batch_size,
shuffle=False,
num_workers=1)
# 模型定义
# 参数:vocab_size, embedding_dim, hidden_dim
# 注意它继承了nn.Module
model = PoetryModel(len(word2ix), 128, 256)
optimizer = t.optim.Adam(model.parameters(), lr=opt.lr)
# criterion(output, target),实质上是计算nn.nLLLoss()(nn.logSoftmax()(output),target)
criterion = nn.CrossEntropyLoss()
# 加载模型
if opt.model_path:
model.load_state_dict(t.load(opt.model_path))
# 完成tensor数据向device复制粘贴
model.to(device)
loss_meter = meter.AverageValueMeter()
for epoch in range(opt.epoch):
loss_meter.reset()
# tqdm的作用是进度条,ii和data_的值依旧等于enumerate(dataloader)
for ii, data_ in tqdm.tqdm(enumerate(dataloader)):
# 训练
# 本来data_是[[第一首],[第二首]...];转置后变成了[[所有诗的第一个字][所有诗的第二个字]...]
# data_维度变化:[batch_size, seq_len]变成[seq_len, batch_size],从而符合embedding层输入要求
data_ = data_.long().transpose(1, 0).contiguous()
data_ = data_.to(device)
optimizer.zero_grad()
# s[:-1]等价于s[0:len(s)-1],即除了最后一个元素的切片
# 输入是除了最后一个字的序列;目标是除了第一个字的序列
# 输入和目标的维度都是[seq_len - 1, batch_size]
input_, target = data_[:-1, :], data_[1:, :]
# output维度:[(seq_len-1) * batch_size, vocab_size]
output, _ = model(input_)
# view(-1)是拉直为一维的意思
# 已定义:criterion = nn.CrossEntropyLoss()
# output的size是:[(seq_len-1) * batch_size, vocab_size];
# target.view(-1)的size是:[(seq_len-1) * batch_size],和output的size不一致
# 原因就是nn.CrossEntropyLoss()(output, target)中,output是类别的概率分布,
# 而target是类别值,而不是one-hot编码
loss = criterion(output, target.view(-1))
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
# 可视化
if (1 + ii) % opt.plot_every == 0:
if os.path.exists(opt.debug_file):
ipdb.set_trace()
vis.plot('loss', loss_meter.value()[0])
poetrys = [[ix2word[_word] for _word in data_[:, _iii].tolist()]
for _iii in range(data_.shape[1])][:16]
vis.text('</br>'.join([''.join(poetry) for poetry in poetrys]), win=u'origin_poem')
gen_poetries = []
for word in list(u'春江花月夜凉如水'):
gen_poetry = ''.join(generate(model, word, ix2word, word2ix))
gen_poetries.append(gen_poetry)
vis.text('</br>'.join([''.join(poetry) for poetry in gen_poetries]), win=u'gen_poem')
# 保存模型
t.save(model.state_dict(), '%s_%s.pth' % (opt.model_prefix, epoch))
注释可能之后会按需更新到更多语句。
了解topk()的作用
代码中有一句top_index = output.data[0].topk(1)[1][0].item(),topk顾名思义就是选取最大的k个值,但其没那么简单,所以我们用简单的例子了解topk的用法:
>>> b = t.Tensor([[1, 2], [4, 3]])
tensor([[1., 2.],
[4., 3.]])
>>> b.topk(1)
torch.return_types.topk(
values=tensor([[2.],
[4.]]),
indices=tensor([[1],
[0]]))
上述代码创建了一个Tensor b,如果对其运行topk(1),那么就是选取最大的1个值。具体地,从b的第一行选取最大的值,再从b的第二行选取最大的值,并且还要记录最大值在该行的index。
同理,如果运行topk(2),结果如下:
>>> b.topk(2)
torch.return_types.topk(
values=tensor([[2., 1.],
[4., 3.]]),
indices=tensor([[1, 0],
[0, 1]]))
问题来了,如果我想获得b中第一行最大的值,应该怎么写?尝试:
>>> b.data[0].topk(1)
torch.return_types.topk(
values=tensor([2.]),
indices=tensor([1]))
成功获得了b中第一行的最大值,还有它的index。但是上述显示方式比较复杂,如果我只想要具体的最大值2,或者具体的index 1,应该怎么写呢?尝试:
>>> b.data[0].topk(1)[1]
tensor([1])
于是我们获得了b中第一行最大值在该行的index,但还是不够具体,我不想要中括号[]:
>>> b.data[0].topk(1)[1][0]
tensor(1)
中括号去掉了,但如果只想要数字呢?尝试:
>>> b.data[0].topk(1)[1][0].item()
1
现在,我们通过上述代码,获得了b的第一行的最大值在该行的index的具体值。这句话和上述代码一样绕口0.0
使用模型——生成诗歌
generate函数用来生成诗歌,详情见注释:
def generate(model, start_words, ix2word, word2ix, prefix_words=None):
results = list(start_words)
start_word_len = len(start_words)
# 手动设置第一个词为<START>
# 对于Tensor([1]),对其view(1)和view(1, 1)的size分别为[1]和[1, 1]
# input作为embedding的输入,维度应该是类似于"每句话几个词(seq_len)×几句话(batch)"
# test阶段要做的就是每次输入一个词,然后推断下一个词。所以维度为"1个词×1句话"即可
# 通过word2ix[词]获得词对应的编号。ix2word则相反
input = t.Tensor([word2ix['<START>']]).view(1, 1).long()
if opt.use_gpu: input = input.cuda()
# model.py中定义的类会自动规定,hidden为None的时候,要根据网络的size创建hidden
# 注意hidden包含h_0和c_0
hidden = None
# prefix_words能控制诗歌意境的原因:将其中的词一个个输入LSTM,形成"记忆"
# 并将prefix_words中最后一个词作为上述<START>的替代品
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
# 创建一个新的Tensor
input = input.data.new([word2ix[word]]).view(1, 1)
# max_gen_len控制能够生成的最长诗句
for i in range(opt.max_gen_len):
# output的size:(seq_len*batch_size,vocab_size)
# 在这里应该是(1,vocab_size)
output, hidden = model(input, hidden)
if i < start_word_len:
w = results[i]
input = input.data.new([word2ix[w]]).view(1, 1)
else:
# top_index是这一时序的输出词对应的编号or下标
# item()就是只使用这个Tensor的值
# 注意这是test阶段,output的size为(seq_len, vocab_size)
# 并且input是逐词输入的,所以seq_len应该为1,
# 分析output.data[0]:指的就是第一个序列输出的vocab_size维向量,
# topk(1)指的是获得这个向量中的最大值、对应下标(以下简称"下标")
# topk(1)[0]指的是最大值、topk(1)[1]指的是下标,这俩都是Tensor
# topk(1)[1]的形式是:tensor([下标]),
# 所以用topk(1)[1][0]获得形式:tensor(下标)
# 然后topk(1)[1][0].item()的形式就是:下标
top_index = output.data[0].topk(1)[1][0].item()
# 这一时序的输出,同时也是下一时序的输入
w = ix2word[top_index]
results.append(w)
input = input.data.new([top_index]).view(1, 1)
# 遇到结束符
if w == '<EOP>':
del results[-1]
break
return results
使用模型——生成藏头诗
作者使用gen_acrostic()函数生成藏头诗,有了对generate()函数的讲解,此函数就很容易理解了:
def gen_acrostic(model, start_words, ix2word, word2ix, prefix_words=None):
"""
生成藏头诗
start_words : u'深度学习'
生成类似于:
深木通中岳,青苔半日脂。
度山分地险,逆浪到南巴。
学道兵犹毒,当时燕不移。
习根通古岸,开镜出清羸。
"""
results = []
start_word_len = len(start_words)
input = (t.Tensor([word2ix['<START>']]).view(1, 1).long())
if opt.use_gpu: input = input.cuda()
hidden = None
index = 0 # 用来指示已经生成了多少句藏头诗
pre_word = '<START>'
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
input = (input.data.new([word2ix[word]])).view(1, 1)
for i in range(opt.max_gen_len):
output, hidden = model(input, hidden)
top_index = output.data[0].topk(1)[1][0].item()
w = ix2word[top_index]
if (pre_word in {u'。', u'!', '<START>'}):
# 如果遇到句号,藏头的词送进去生成
if index == start_word_len:
# 生成的诗歌已经包含了全部藏头的词,则结束
break
else:
# 把藏头的词作为输入送入模型
w = start_words[index]
index += 1
input = (input.data.new([word2ix[w]])).view(1, 1)
else:
# 否则,把上一次预测的词作为下一个词输入
input = (input.data.new([word2ix[w]])).view(1, 1)
results.append(w)
pre_word = w
return results
gen()函数
作者还专门写了个gen()函数,用于导入模型、选择生成诗歌还是生成藏头诗等。除了torch.load()的简单介绍外,不详细记录了。
def gen(**kwargs):
"""
提供命令行接口,用以生成相应的诗
"""
for k, v in kwargs.items():
setattr(opt, k, v)
data, word2ix, ix2word = get_data(opt)
model = PoetryModel(len(word2ix), 128, 256)
'''
不同的导入方法
>>> torch.load('tensors.pt')
# Load all tensors onto the CPU
>>> torch.load('tensors.pt', map_location=torch.device('cpu'))
# Load all tensors onto the CPU, using a function
>>> torch.load('tensors.pt', map_location=lambda storage, loc: storage)
# Load all tensors onto GPU 1
>>> torch.load('tensors.pt', map_location=lambda storage, loc: storage.cuda(1))
# Map tensors from GPU 1 to GPU 0
'''
if opt.use_gpu:
# 意思是map_location(s, l)的值为s
map_location = lambda s, l: s
# 载入模型
state_dict = t.load(opt.model_path, map_location=map_location)
else:
state_dict = t.load(opt.model_path)
model.load_state_dict(state_dict)
if opt.use_gpu:
model.cuda()
# python2和python3 字符串兼容
if sys.version_info.major == 3:
if opt.start_words.isprintable():
start_words = opt.start_words
prefix_words = opt.prefix_words if opt.prefix_words else None
else:
start_words = opt.start_words.encode('ascii', 'surrogateescape').decode('utf8')
prefix_words = opt.prefix_words.encode('ascii', 'surrogateescape').decode(
'utf8') if opt.prefix_words else None
else:
start_words = opt.start_words.decode('utf8')
prefix_words = opt.prefix_words.decode('utf8') if opt.prefix_words else None
start_words = start_words.replace(',', u',') \
.replace('.', u'。') \
.replace('?', u'?').replace('<', u'<')
# 这个是选择给定初始词or句子生成诗歌还是生成藏头诗
gen_poetry = gen_acrostic if opt.acrostic else generate
result = gen_poetry(model, start_words, ix2word, word2ix, prefix_words)
# result中的元素用''(无字符)连接的意思,这样可以去掉分隔符
print(''.join(result))
七、展示运行结果(待更)
心疼电脑,等我的散热架到货了再写此部分。当然读者也可以直接看原作者的运行结果,在文首的GitHub链接中。
《炖鹅》
鹅鹅鹅,
铁锅炖大鹅。
白毛要拔净,
红掌端上桌。
鹅:我可能不是人,但你是真的狗

(当然,train完不会是这首)















 1284
1284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









