






 超级会员免费看
超级会员免费看
 本文探讨了互联网业务中由于数据量大导致的性能瓶颈,提出了分库分表作为解决方案。介绍了分库分表的背景,如数据库连接限制和性能下降,并详细阐述了垂直切分和水平切分的原理。分库分表引入了分布式事务、跨库查询等问题,可以通过分库分表中间件如Apache ShardingSphere来解决。最后,总结了分库分表的重要性和实施注意事项。
本文探讨了互联网业务中由于数据量大导致的性能瓶颈,提出了分库分表作为解决方案。介绍了分库分表的背景,如数据库连接限制和性能下降,并详细阐述了垂直切分和水平切分的原理。分库分表引入了分布式事务、跨库查询等问题,可以通过分库分表中间件如Apache ShardingSphere来解决。最后,总结了分库分表的重要性和实施注意事项。
“为什么需要分库分表,如何实现”?
文章目录
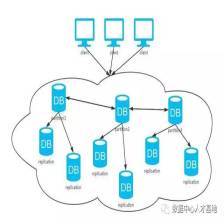
在上一文章中讲到了读写分离,读写分离优化了互联网读多写少场景下的性能问题,考虑一个业务场景,如果读库的数据规模非常大,除了增加多个从库之外,还有其他的手段吗?
方法总比问题多,实现数据库高可用,还有另外一个撒手锏,就是分库分表,分库分表也是面试的常客,今天一起来看一下相关的知识。
分库分表的背景
互联网业务的一个特点就是用户量巨大,BAT等头部公司都是亿级用户,产生的数据规模也飞速增长,传统的单库单表架构不足以支撑业务发展,存在下面的性能瓶颈:
读写的数据量限制
数据库的数据量增大会直接影响读写的性能,比如一次查询操作,扫描 5 万条数据和 500 万条数据,查询速度肯定是不同的。
关于 MySQL 单库和单表的数据量限制,和不同的服务器配置,以及不同结构的数据存储有关,并没有一个确切的数字。这里参考阿里巴巴的《Java 开发手册》中数据库部分的建表规约:
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
基于阿里巴巴的海量业务数据和多年实践&#x

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 4080
4080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











