






 文章详细介绍了《诛仙手游》在Unity引擎上的资源压缩策略,包括对Mesh、动画、纹理和音频的压缩方法,以及运行时的性能优化,如LOD、场景流和SRPBatch合批。此外,文章还分享了如何利用UnityPerformanceReporting(UPR)进行自动化性能测试和质量保证。
文章详细介绍了《诛仙手游》在Unity引擎上的资源压缩策略,包括对Mesh、动画、纹理和音频的压缩方法,以及运行时的性能优化,如LOD、场景流和SRPBatch合批。此外,文章还分享了如何利用UnityPerformanceReporting(UPR)进行自动化性能测试和质量保证。

刘彦麟:诛仙手游是一款手绘风 仙侠类 MMO手游,今年已经是上线的第七年。我们每年保证4-5个资料片的内容更新,包括新的效果和新的玩法,也在持续对项目进行性能优化;许多技术接入与优化策略也会更注重稳定性和兼容性,以便能够更好地适配新老用户。2021年,我们进行了一次大的版本升级,希望通过可编程管线进一步提升项目的性能。下面就和大家分享《诛仙手游》中的优化方法和计划思路,包括对UPR的使用,希望我的分享能够给大家带来帮助和启发。
我的介绍包括几个部分:一,我们在Unity提供的压缩方式基础上如何策略性进行资源压缩以及对部分资源进行程序化压缩,进一步降低资源大小;二,诛仙手游已经实现的通用性优化方法;三,我们对Unity Performance Reporting(UPR)的使用。

Assets Compression
游戏中最常用、占用内存最大的资源就是Mesh、动作文件、纹理和音频,随着资料片的更新,这些文件数量也在不断增加。诛仙手游会针对具体需求采取策略性方法,保证游戏效果的情况下也会采用程序性方法将资源进一步压缩,减小内存占用空间。
Unity为我们提供了两种方法:资源导入的Mesh Compression,但是这种方法只会影响Mesh在磁盘空间大小。
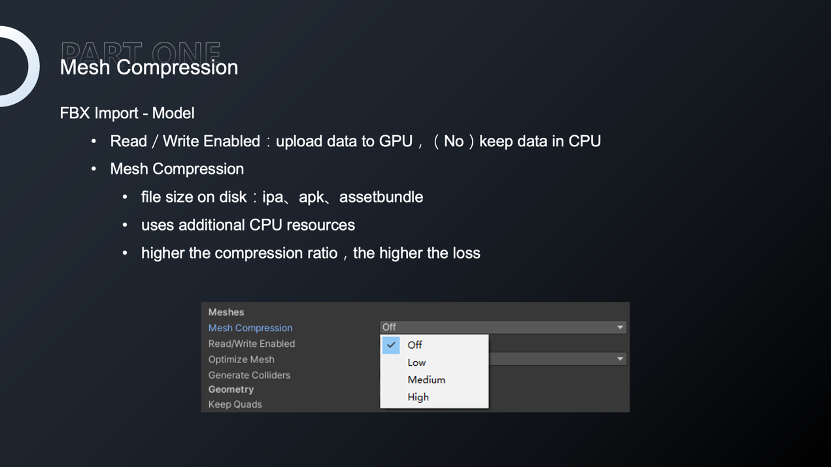
第二个是 playersetting 中的顶点压缩。相对于包体,我们更注重运行时内存,而顶点压缩才会真正影响内存占用。但问题是这些是全局性的压缩策略,对于所有mesh来说,它会采用同一套压缩方法,而不同的模型顶点属性精度要求可能是不同的。
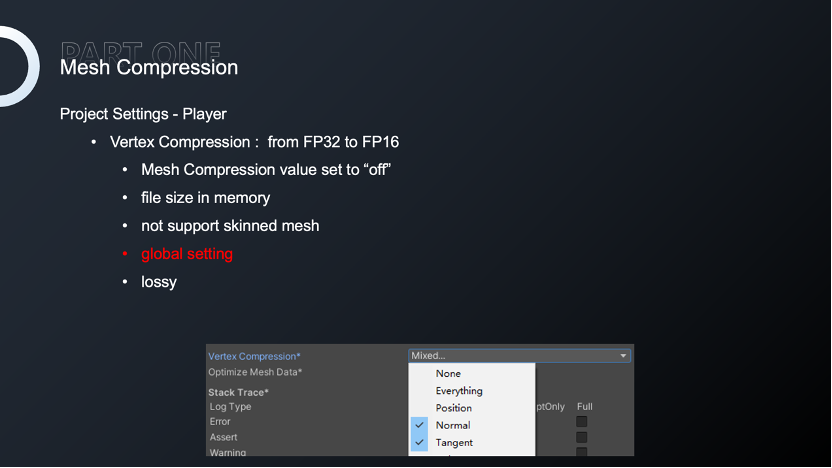
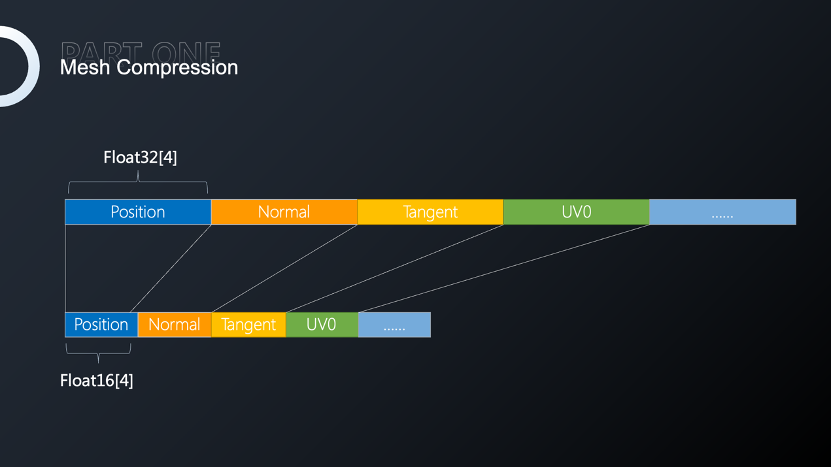
因此,我们对顶点数据的结构进行了重新组合,针对某个或者某类Mesh进行具有特定化的压缩组合,可选择性地将某些顶点属性压缩到16位,达到效果与内存的平衡。
并且,通过球座标系的方式将法线或者切线3个float分量,转换为仰角、方位角两个float,这样可以将法线和切线使用一个float4保存,运行时在顶点着色器中进行解码,更进一步压缩Mesh。
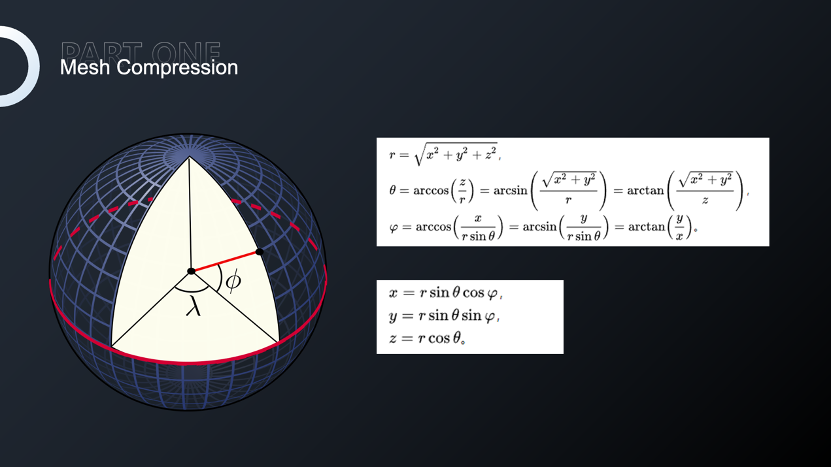
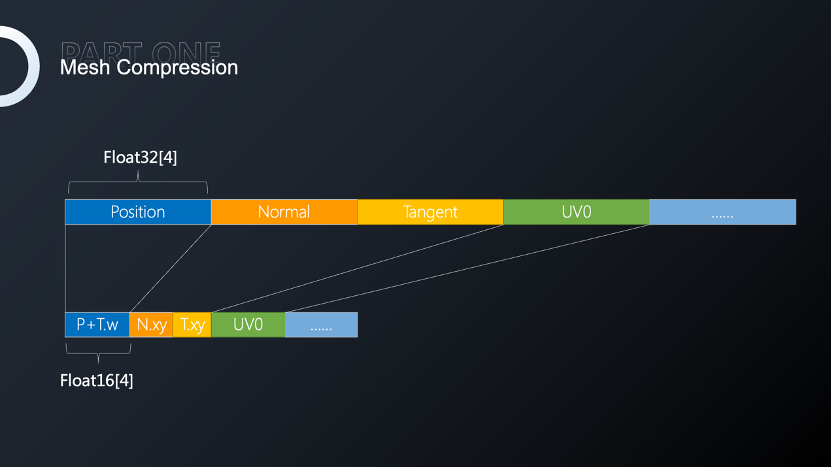
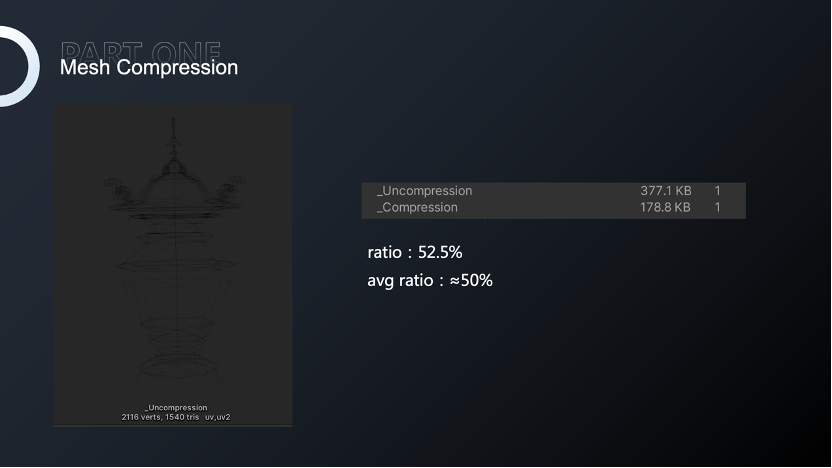
这样的方法,法线和切线压缩之后在解压的效果上几乎是没有变化的。针对这样的顶点模型,完全压缩后的压缩率可以达到52%,而对我们项目中的所有Mesh压缩进行统计,大多数Mesh压缩率基本可以在50%左右浮动。

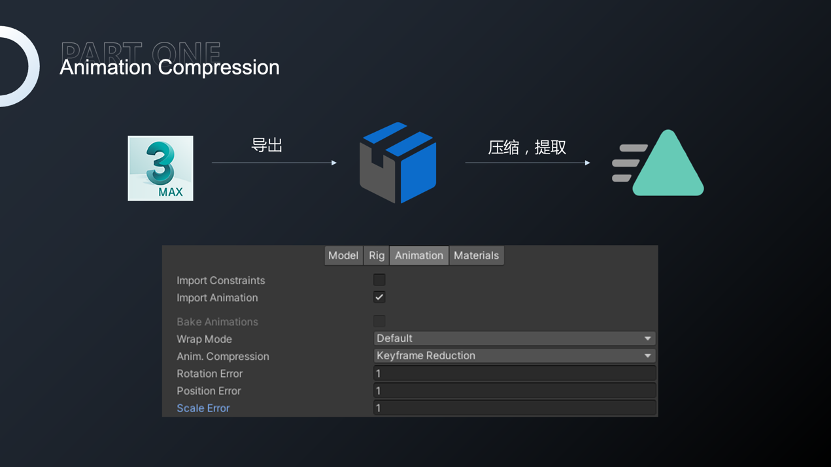
除此之外,我们还会对Animation进一步压缩。相比Mesh,Animation可以针对不同文件采用不同的压缩率,但是针对于不同动作,在相同的骨骼点下,他们所需要的精度是不同的。
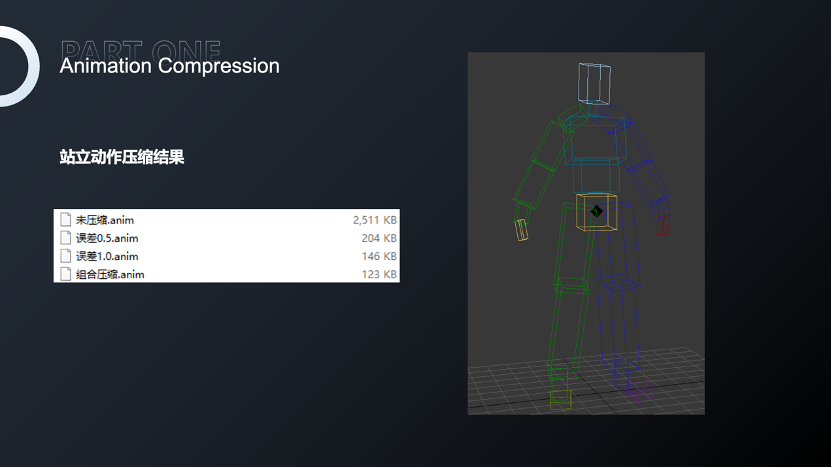
比如一个站立动作。对新玩家来说,创角场景看到的第一个动作就是站立动作,较大的压缩率会使脚步与地面产生较大的位移。我们可以看到Error1.0和0.5,脚步的位移是非常明显的。某些项目为了给新玩家优质的体验,会在创角场景和首登场景给予独立资源保证好的效果,但这样就会额外增加包体大小。《诛仙手游》使用程序化的方式对Animation进行压缩,针对不同肢体采用不同压缩误差,达到效果和性能的平衡。可以看到第四个模型中,经过组合压缩的动作脚步和地面相对位移是非常小的。

针对站立动作的腿部,我们采用非常低的误差;而对其它部位会使用较高误差、较低精度从而达到对整体动作文件大小的平衡,以及对局部动作效果的保证。
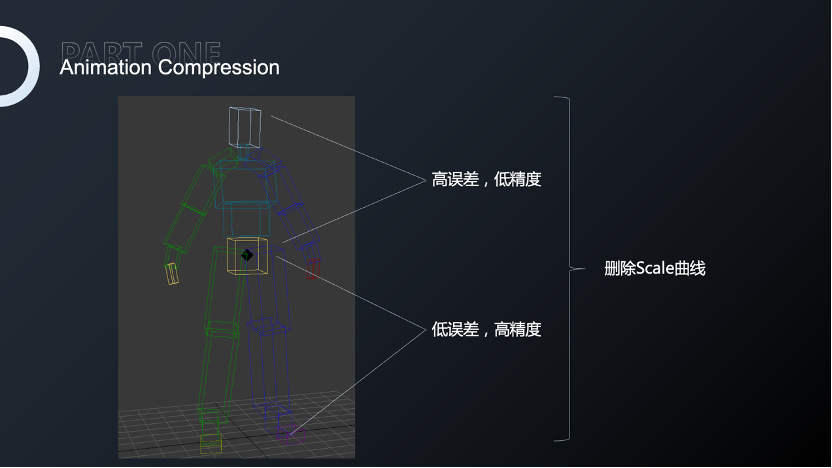
经过这样的处理,腿部组合压缩会有更多的采样点,保证腿部的精度;而手臂在不影响效果的情况下尽可能减少采样点,平衡整体文件的大小。
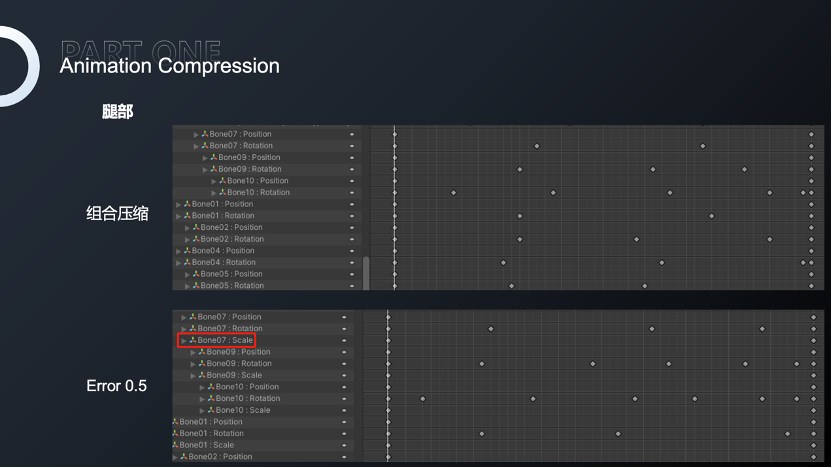
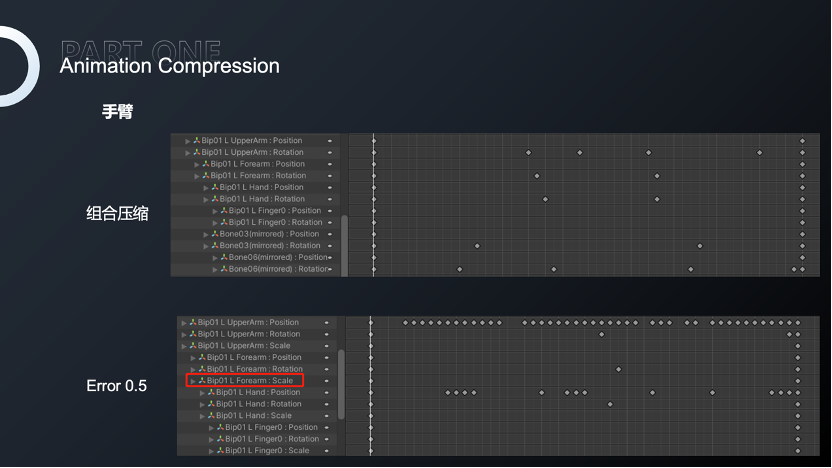
我们可以看到组合压缩曲线会更加拟合原始文件,而Error1.0和0.5曲线相对原始文件误差会非常大。

组合压缩不仅效果可以达到需求,压缩后的文件大小也是非常理想的,动作文件经过组合压缩以后大小甚至比误差1.0还小。
纹理处理主要包含两个方面:一是纹理复用,主要体现在UI,使用九宫格以及1/2 1/4 对称纹理,提高UI上的纹理复用性,降低内存包体的占用;二是压缩格式,更高的压缩率可以使纹理占用更小的空间。
我们在升级之前采用ETC和PVRTC方式对纹理进行压缩,但都有不同程度的损失。ETC对图像中的颜色边缘或梯度渐变等纹理压缩质量是非常低的,PVRTC可以使用高频和低频信号让图片中的颜色变得更清晰,但只有64位中的3位会影响Alpha值,因此半透纹理经过PVRTC压缩质量也是非常不理想的。我们升级的时候就将所有纹理压缩,包括Android和IOS统一调整为ASTC,可以解决ETC和PVRTC这几个痛点。
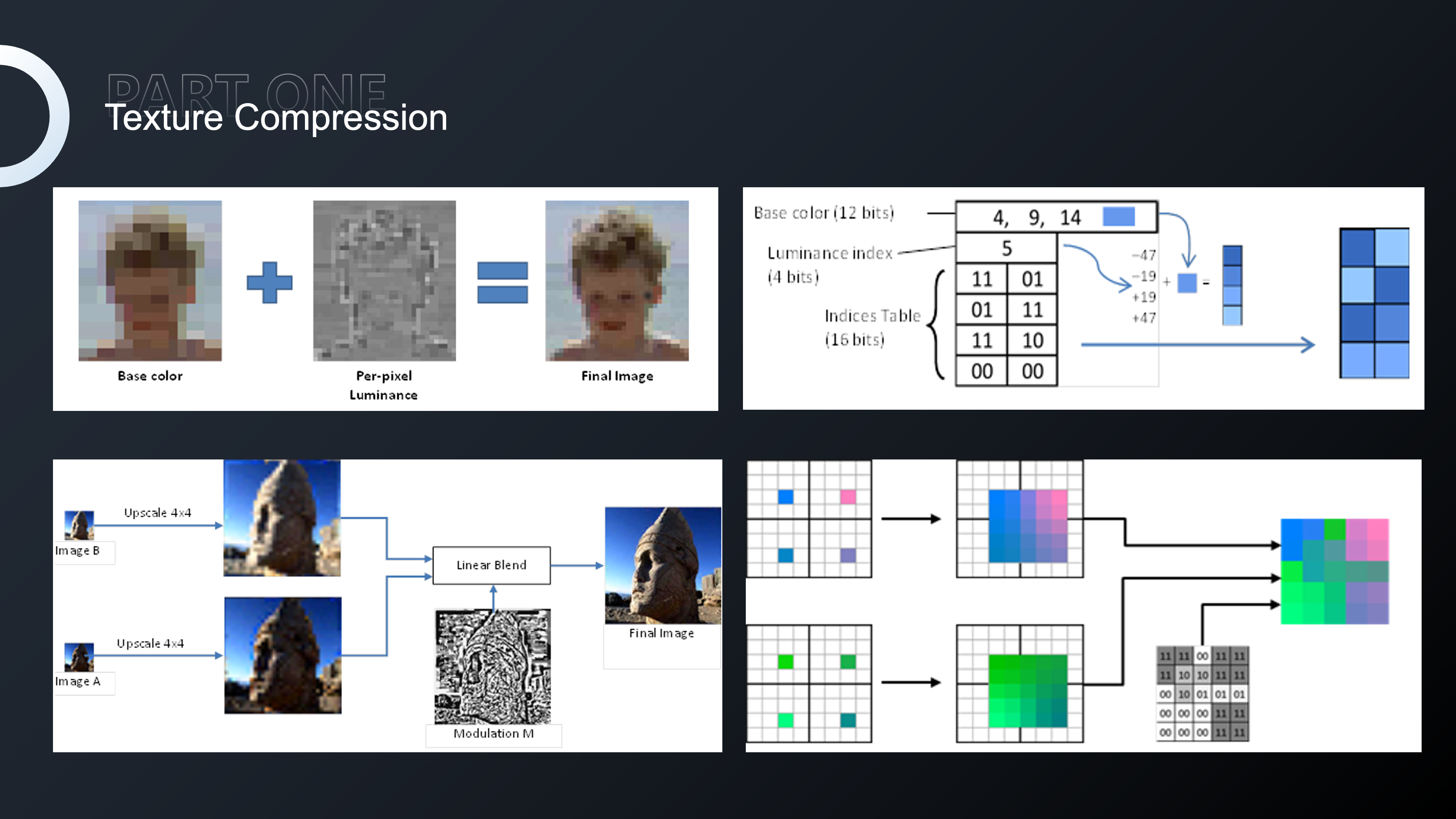
我们将纹理压缩格式设为ASTC 6×6,效果达不到合理质量的时候就会逐步调整压缩格式,保证所有贴图都有一种合适的压缩格式,减少对RGB32的使用。ASGC没有对尺寸的限制,特别对UI设计来说是非常友好的。
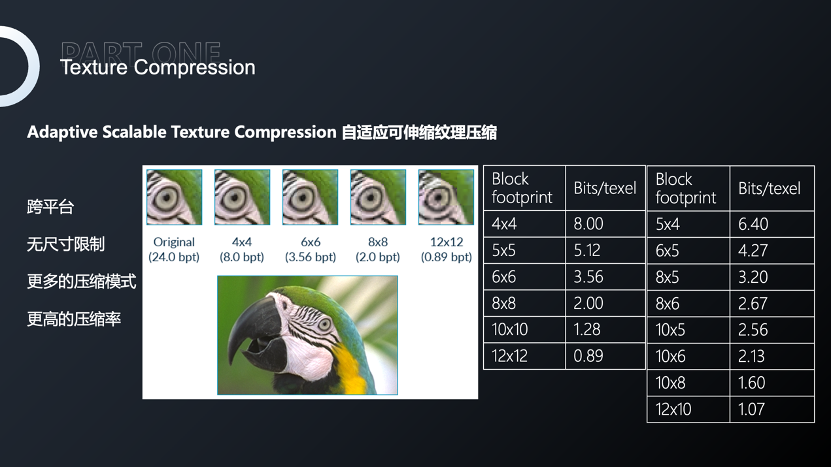
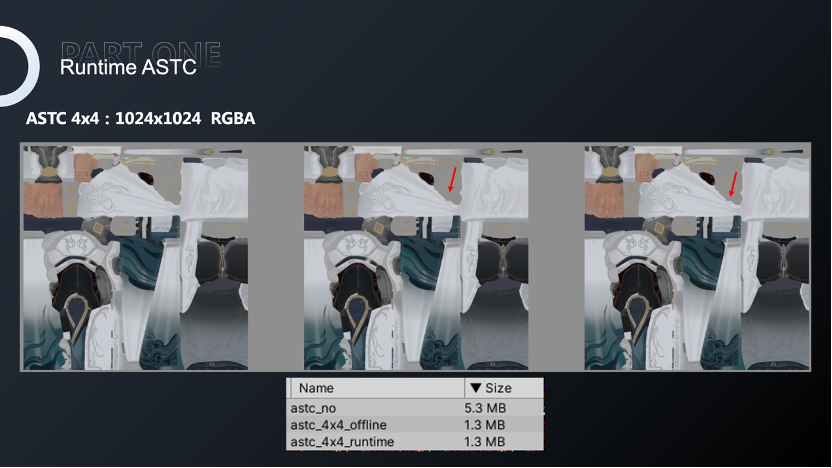
此外,ASTC也是一种开源的算法,因此我们也在尝试对运行时产生的纹理进行实时压缩,进一步减少纹理占用的内存。
最后就是对音频的处理,主要还是策略上的应用,我们会根据音频属性以及大小采用不同的策略加载和使用。

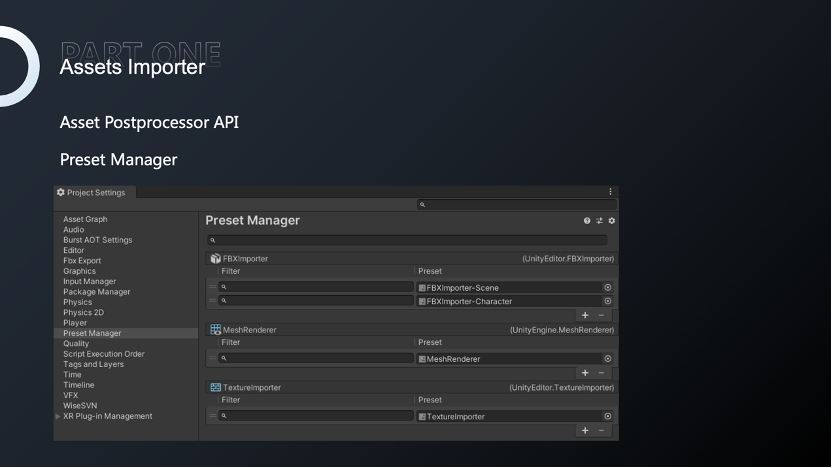
以上这些资源都会为我们进行程序化的处理。我们使用两种方式:
1、Postprocess,用于fbx导入的处理,比如分离 mesh 和材质,mesh压缩等;
2.纹理这样的文件会使用 Preset Manager 的方式进行默认贴图格式的设置,之后的工作中随着需求的不同会逐步调整纹理格式。
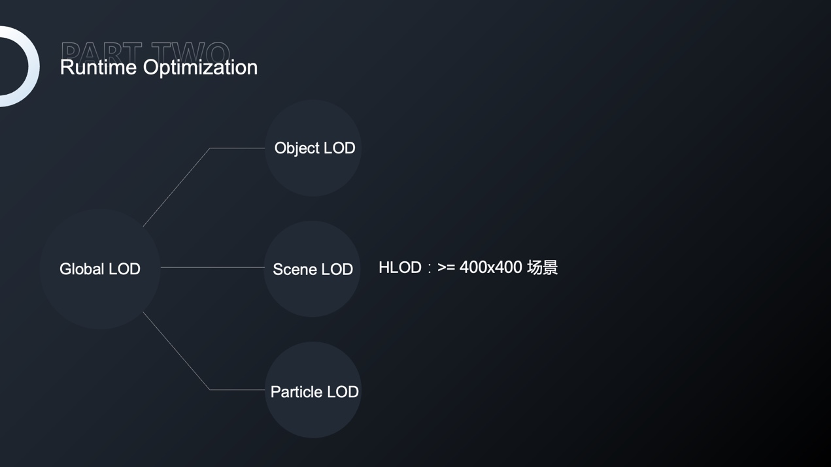
Runtime Optimization
下面再与大家介绍运行时做的比较通用的优化方法。
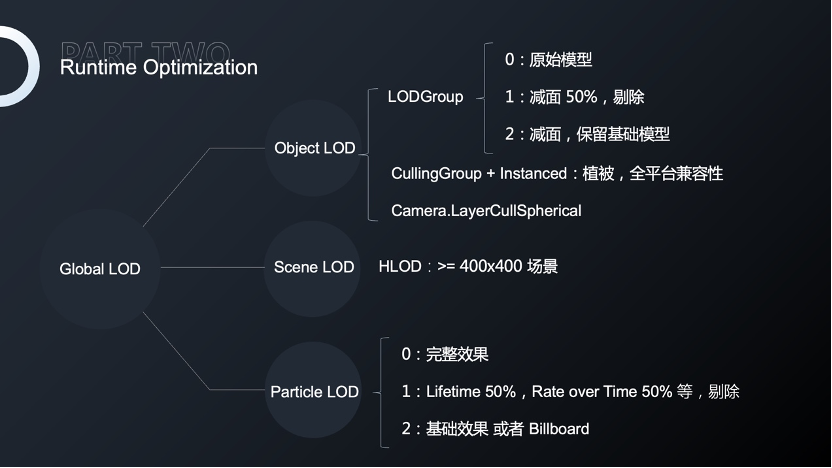
首先是对全局LOD,400×400以上的场景会使用100×100的子场景进行资源管理,然后对子场景进行烘焙,这样会极大的减少drawcall,但同时会增加HLOD所产生的内存。
我们会对复杂场景直接使用LODGroup划分,简单的建筑使用Camera进行直接剔除,特殊物体也会采用特殊处理办法。
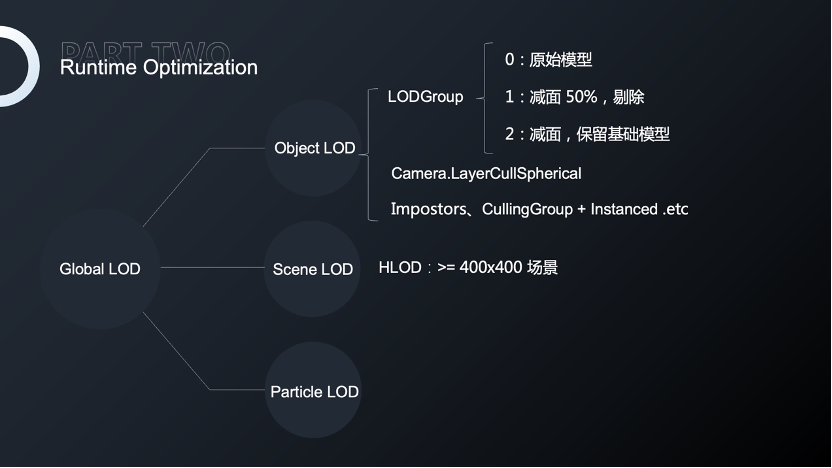
比如,我们会对树木使用Impostor的方式进行预烘焙,虽然Imposter烘焙的纹理相对更大,但从效果来看会比广告板的效果好得多,更加有立体感。

我们会对草地使用Instanced的方式进行绘制,好处在于极大减少drawcall,并且具有较强的兼容性,问题是无法进行剔除,因此使用CullingGroup来弥补无法剔除的缺点,并且不同的CullingGroup等级也有不同的渲染密度。

最后最容易被忽略的就是粒子处理,如果粒子过多会对GPU和CPU产生过多的负载,因此我们会对粒子进行LOD细分,不仅仅是粒子发射器的细分,也会对粒子发射器的属性,包括生命周期、粒子产生的数据进行细分,减小粒子产生的压力。
图中这样的粒子特效,随着LOD的变化,某些粒子发射器会被剔除,某些不会,但粒子属性产生的速率以及生命周期会被明显缩短,然后会在团战等特效集中的场景优化极为明显,保证效果的情况下会进一步降低粒子消耗,优化场景的性能。

LOD的优势在于通过全局划分极大地降低dc和面数,同时也增加内存,特别是LODGroup由于效果和同屏面数的双重需求,我们往往会制作减面后的Mesh达到需求,但对整个场景来说增加Mesh会极大地增加内存。
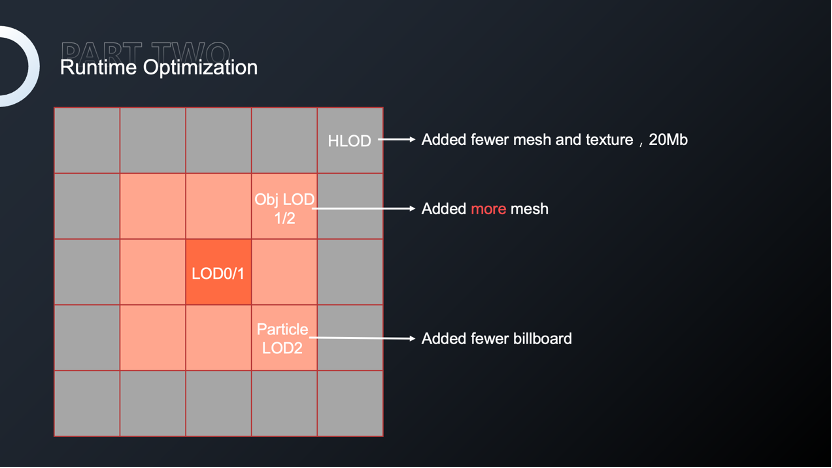
因此,我们使用场景流的方式对资源进行流式加载,分散内存的压力。Unity已经为我们提供对纹理的流式加载,只需要在系统设置中开启串流纹理,根据项目以及某些场景的特定需求设置恰当的参数,然后再开启纹理Mipmap就可以使用串流纹理,运行时系统就会根据视野、距离等参数决定哪一级的Mipmap会被加载,以减少内存占用和性能消耗,并提高加载速度。
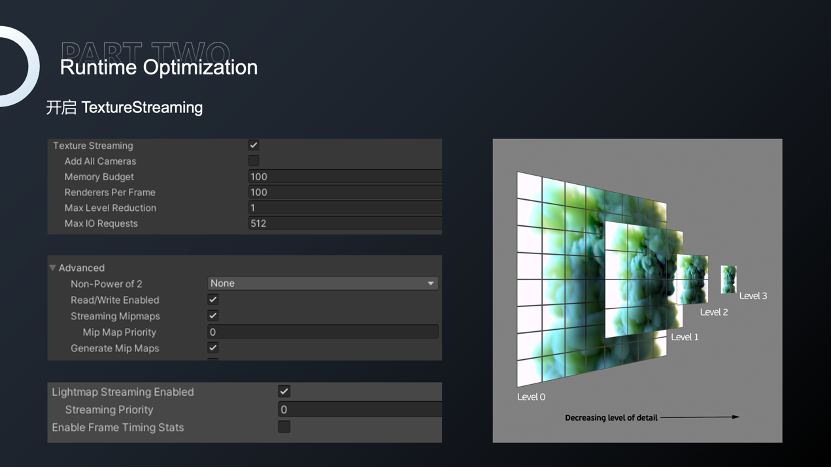

我们对Mesh基本的需求是加载当前可见的Mesh,而不是一次性加载所有Mesh。虽然Unity并未提供这样的功能,但我们可以参考串流纹理实现方式,基于HLOD实现MeshStreaming,平衡LOD增加的内存,更加有效地管理和利用Mesh资源,达到减小内存的目的。
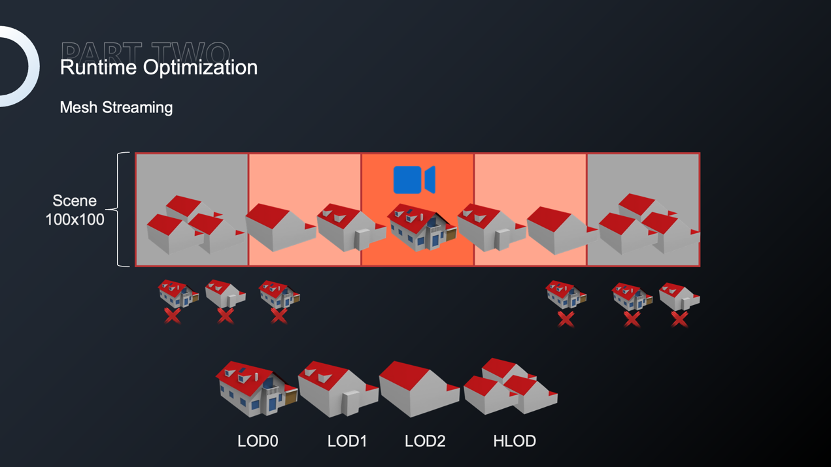
诛仙手游还有一个家园玩法,这是开放给玩家自由建造和摆放家具的独立场景。正是由于这样的高自由度,可能会有大量重复的物件,包括花草和小摆件出现在场景中。玩家更喜欢将这些物体拼装成想要的形状,丰富自己的家园。

由于物体频繁大量出现,我们会使用DOTS进行分簇,然后使用 DrawMeshInstanced 合批绘制。剩余只出现过一次的物体会直接使用SRPBatch的方式进行合批,减少setpass,保证整个场景有较高的渲染效率。
以上就是对场景渲染的优化策略,主要目的在于平衡内存的情况下降低Drawcall和setpass。目前Unity提供了几种场景管理的方式:
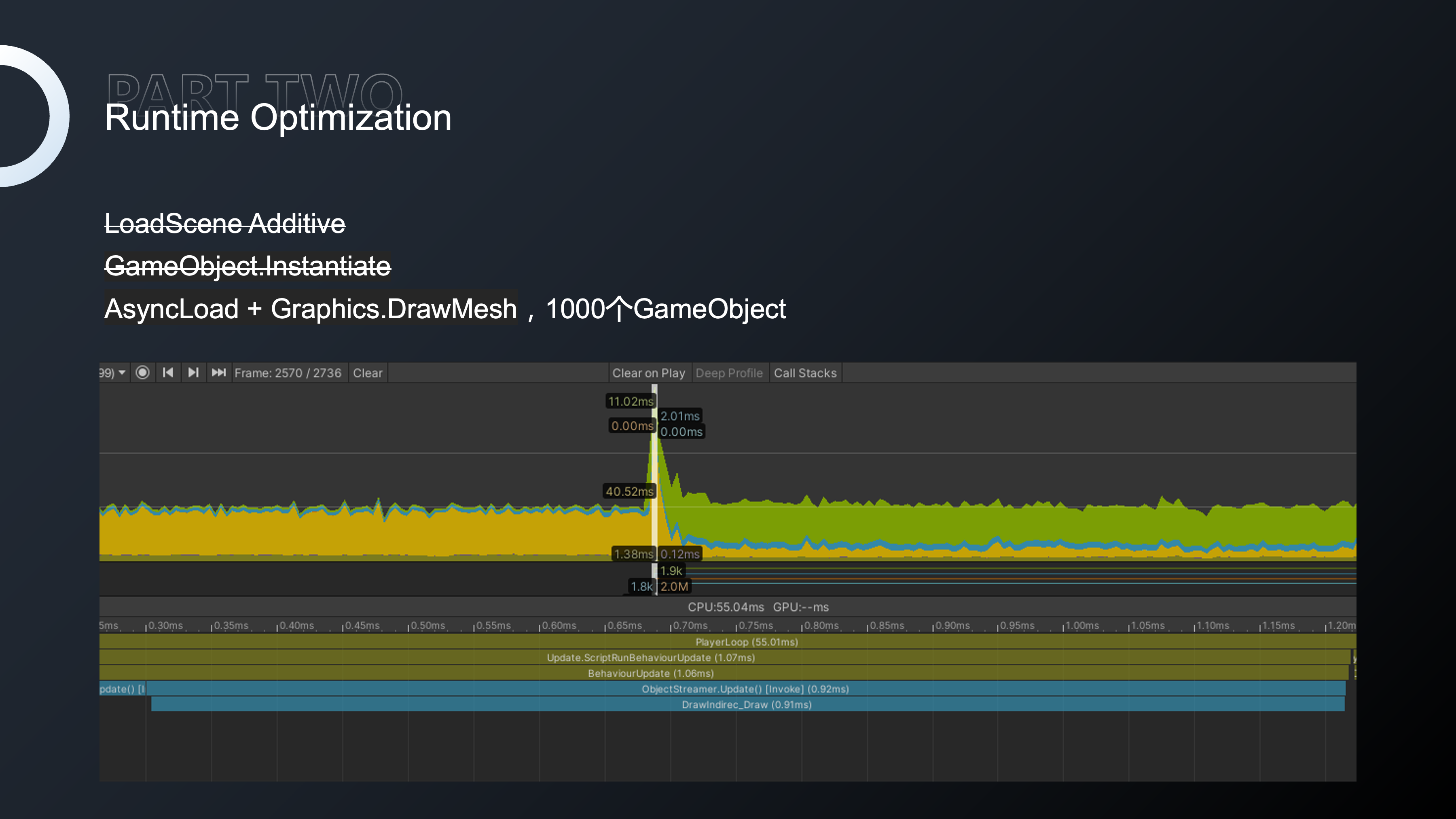
一, LoadScene Additive,无论同步还是异步的场景加载,都会有不同程度的加载卡顿,随着场景物体的数量增多,卡顿的严重性会明显增加。
二,GameObject.Init,过多的GameObject.Init也会产生过多的GC。
因此在我们的项目中使用异步的方式对资源进行按需逐步加载,减少因加载物体产生的卡顿,直接使用DrawMesh对物体进行绘制。
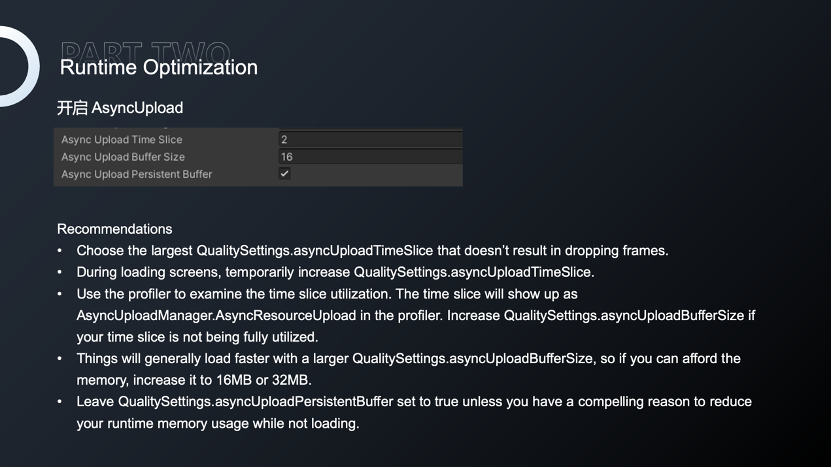
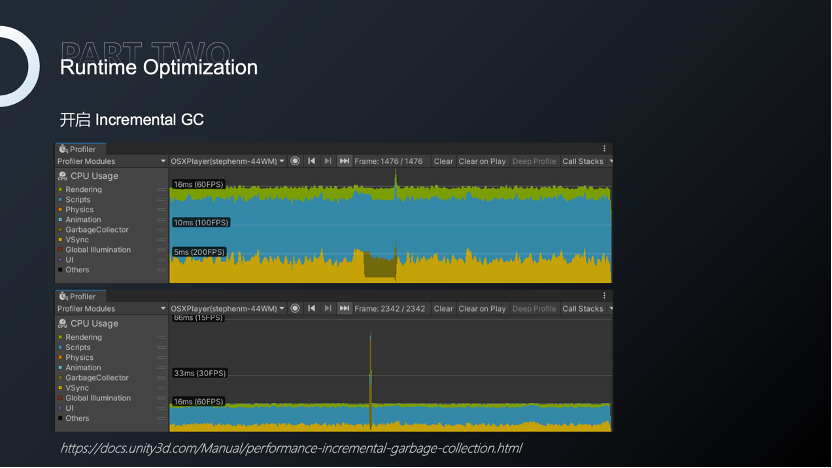
我们也可以通过开启异步上传,加速Mesh和纹理的上传速度,减少Loading时间,同时开启增量GC,能够将GC均摊到每一帧,避免某一时刻因为GC过大产生的卡顿。
至此,从离线压缩到运行时渲染策略,包括场景的加载速度都有一个比较通用的优化基础,在此基础上,我们会根据不同的场景、不同的需求执行具有针对性的优化方法,最终目的就是平衡内存的前提下尽可能减少Drawcall或者setpass。我们在做运行时优化时,更会注重局部性,不仅有空间局部性,还有时间局部性,提升视野内的局部性效果,平衡整体性能需求。
再与大家分享几个关于URP的话题。
SRP Batch是URP的核心功能之一,也是我们决定升级渲染管线的决定性因素之一。我们在某些大场景下由于内存的原因甚至减少静态合批物体的数量,平衡整体性能,减少对因为内存产生的崩溃。SRP Batch的接入会对这种问题进行很大的改善。在诛仙项目中,Shader还是比较统一的,场景中绝大多数物体可以使用1-3个Shader完成绘制,使用SRP Batch可以极大的减少setpass。

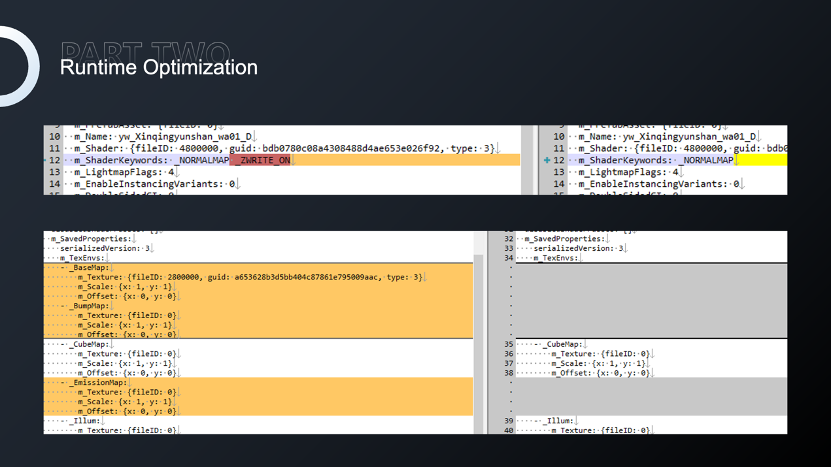
我们往往可以看到2个SRP Batch,Shader和关键字都是一致的,但就是不能合批。材质文件保存的是对关键字的使用,出现与当前Shader不匹配的关键字的原因可能是因为之前的调试或者效果的调试,切换Shader并且激活了关键字,然后在材质中就会保存关键字。Unity判断合批的时候会根据当前已经使用的关键字与材质保存的关键字并集判断是否合批。
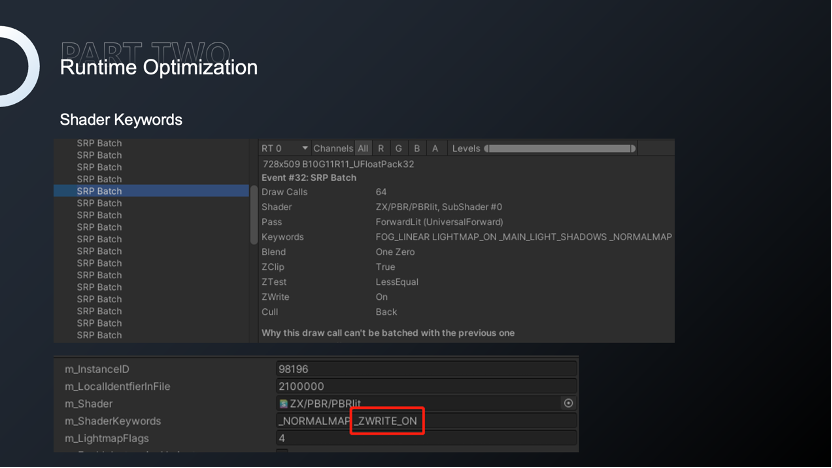
针对这样一个问题,我们在场景编辑完成以后会对所有材质进行基于Shader属性的格式化,避免因为关键字导致的合批失败。除此之外,材质文件还会保存对纹理的使用记录,如果不剔除的话也会被引入到场景,造成不必要的纹理引用。
在URP管线下,可以根据项目需求进行一些定制化的优化。举2个比较容易实现的小例子:
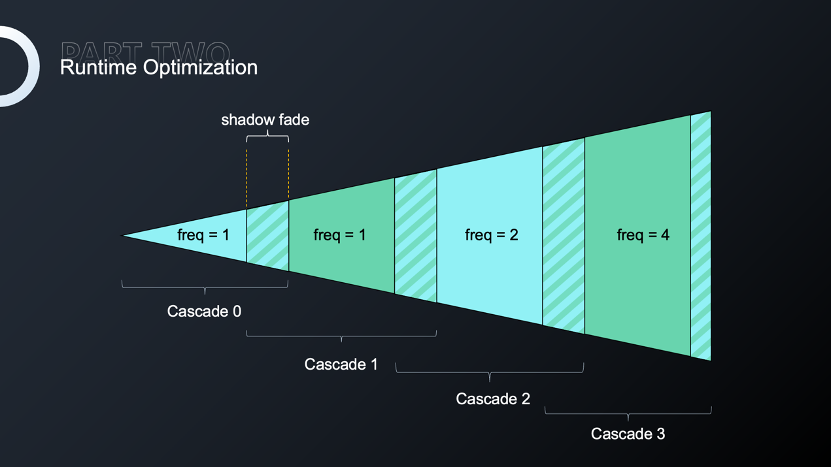
第一个 CSM。仍然是这样家园的玩法,在前文中介绍了如何对物体本身进行有效率的合批,但过多的阴影也会产生过多的DrawCall。我们会对场景阴影进行分帧渲染,针对不同的CSM等级采用不同的渲染频率,降低整体阴影的渲染次数。

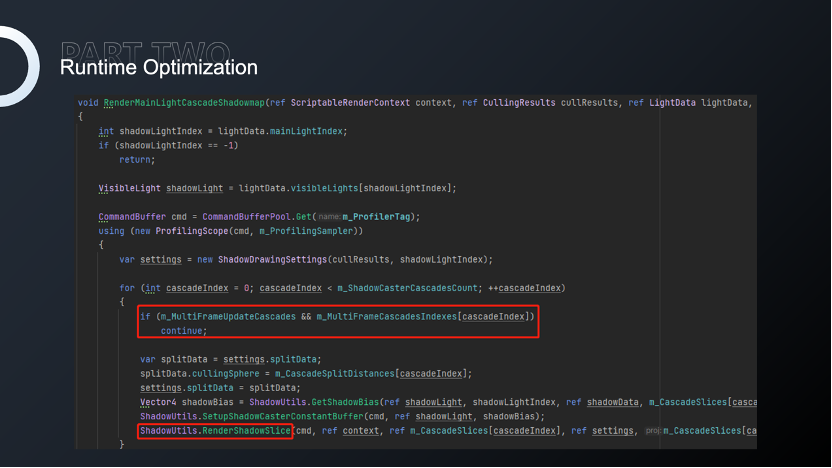
URP实现分帧阴影相对来说容易许多,只要修改CSM函数,对CSM切片进行分帧限制就可以达到这样的效果。
第二个,UI和场景我们采用了不同的颜色空间。UI 使用 Gamma,会有更好的视觉感知和对比度;场景使用线性空间,有助于在渲染过程中进行更准确的光照计算和颜色混合。我们这样的需求就需要对CameraBuffer进行操作。Builtin管线混线无法获得CameraBuffer,但在URP中就可以直接获得这样的CameraBuffer,直接进行操作,从而减少对渲染的消耗。

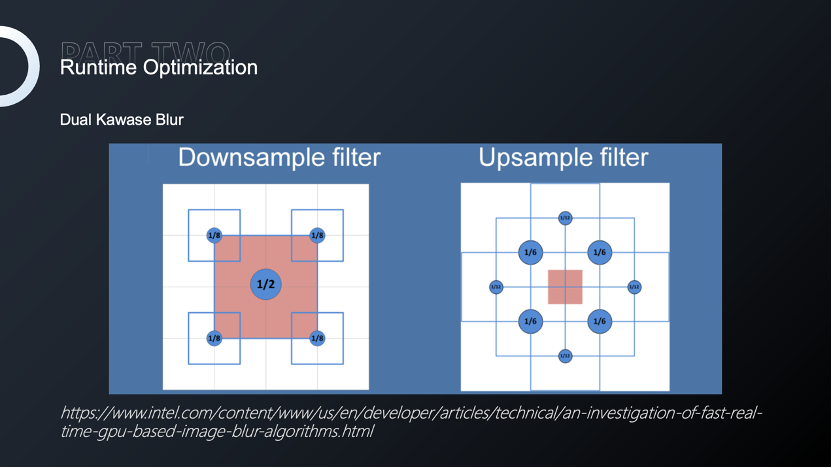
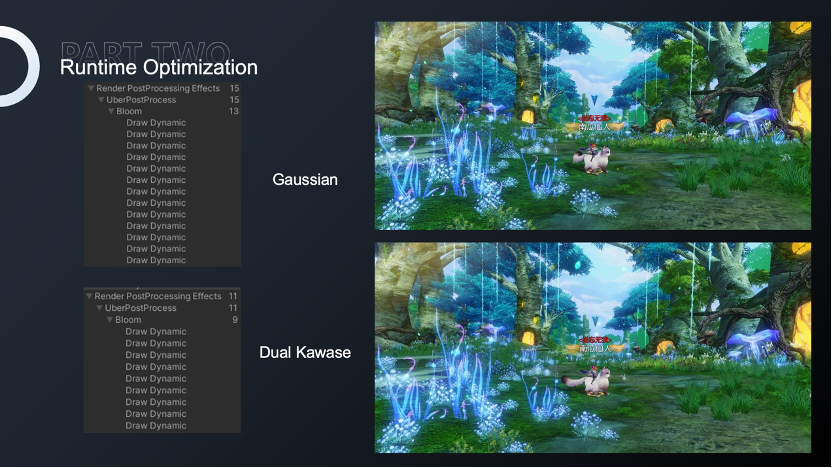
除了对管线原有逻辑的修改,我们还可以对管线进行扩展。简单来说,Kawase是快速高效的图形模糊算法,可以在一定程度上实现Gauss模糊,但只需要较少的采样次数和计算量。
Unity Performance Reporting
接下来为大家分享一下 UPR (Unity Performance Reporting)在诛仙中的使用以及质量保证。
我们2021年上半年计划进行一次引擎升级,希望通过可编程的渲染管线进一步改善项目性能,为后续增加效果以及功能迭代让出更多的空间。我们计划是在5个月内完成这样的工作,需要完成包括引擎升级、管线升级、新效果增加、新功能增加以及最后的测试封包。从技术角度,公司的中台部门以及Unity都为我们提供了切实可行的技术方案;从质量角度,希望升级前后效果不要产生太大的差异,并且还要保证新的管线和新的功能接入以后对当前具有较高的兼容性,作为最基本的要求。
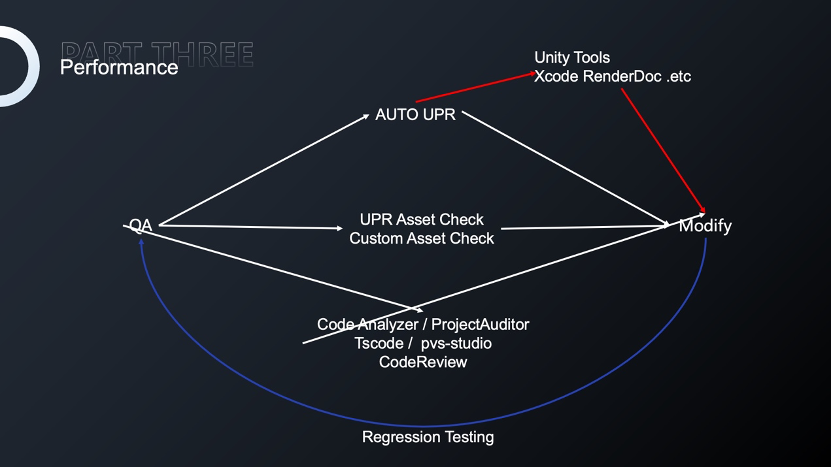
因此,我们需要对升级以后的版本进行多次性能测试。准备升级的时候我们也对项目中所有资源进行了粗略统计,截至到准备升级的那一刻,我们已经积累33个资料片,其中包括场景200多个、模型和特效的Prefabs加起来1万多个。如此大量的资源,完全通过手动测试是非常困难的。

因此,我们借助UPR搭建了一套自动化的性能测试系统,可以系统地对技能、寻路、多场景串联测试等数据进行收集,最后通过UPR对数据进行分析,以提高测试效率。这里唯一需要工作时间的就是测试逻辑的配置,包括寻路路点、技能释放顺序。但是这些配置是一次性的,在后续的回归测试或者对比测试中,这些工作也就不存在了。自动化流程还可以保证每次测试变量是一致的,避免因为某一次测试由于一些变量的修改造成测试的差异。
视频中就是在主城中进行的多个人物的测试,包括单人和多人技能测试。技能测试可能是同时释放的,以计算性能瓶颈;也可能是随机释放的,以模拟在团战以及帮战情况下的性能压力。
通过UPR,我们可以更加直接地对数据进行分析,只有在某些数据不能直观判断的时候才会再次使用xcode renderdoc等平台性工具进行逐帧的分析。性能测试只是我们质量保证中的一环,版本末期还会对资源以及代码进行系统性审查,然后进行回归测试和修改,以保证上线后的游戏质量。
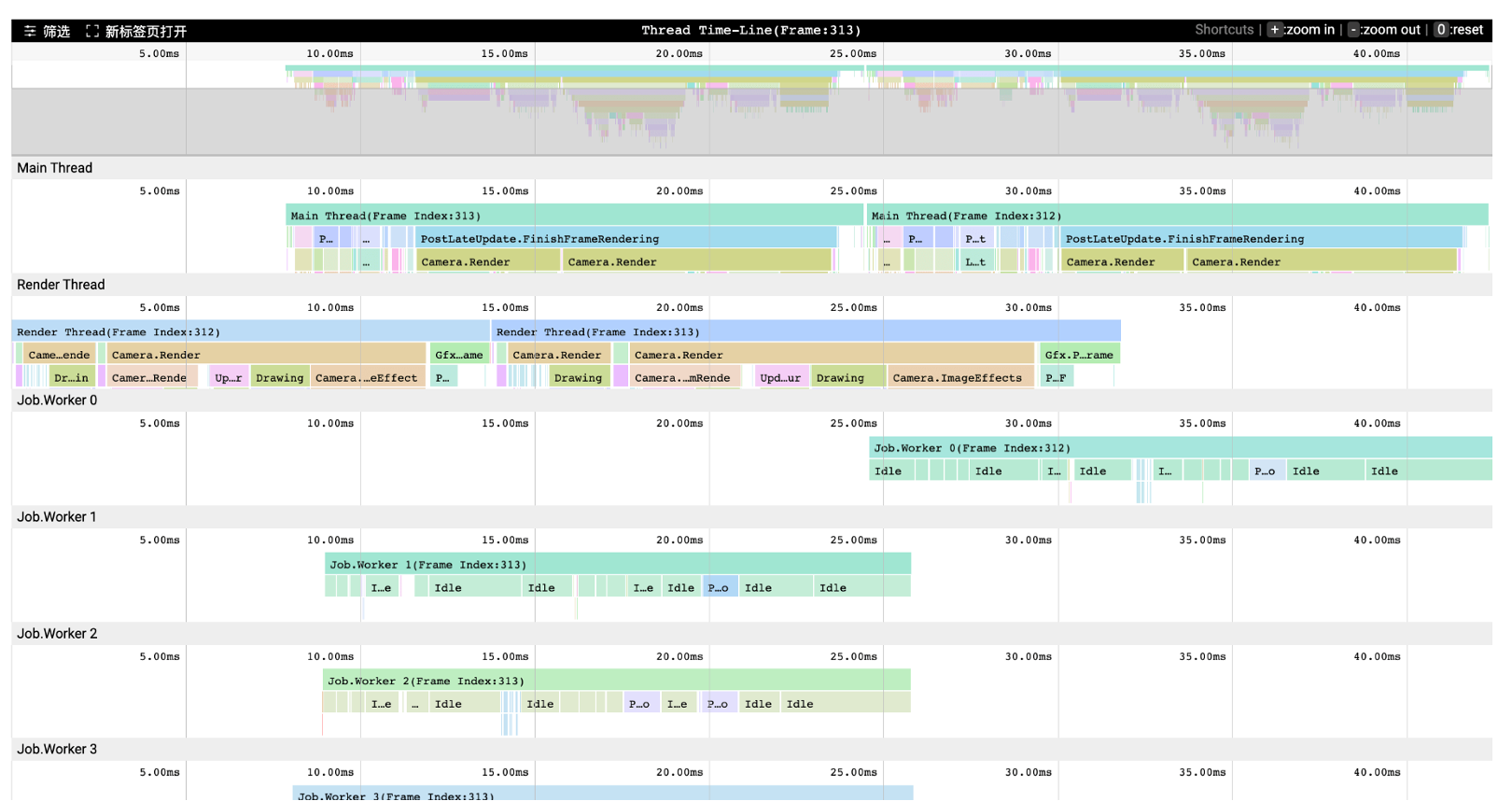
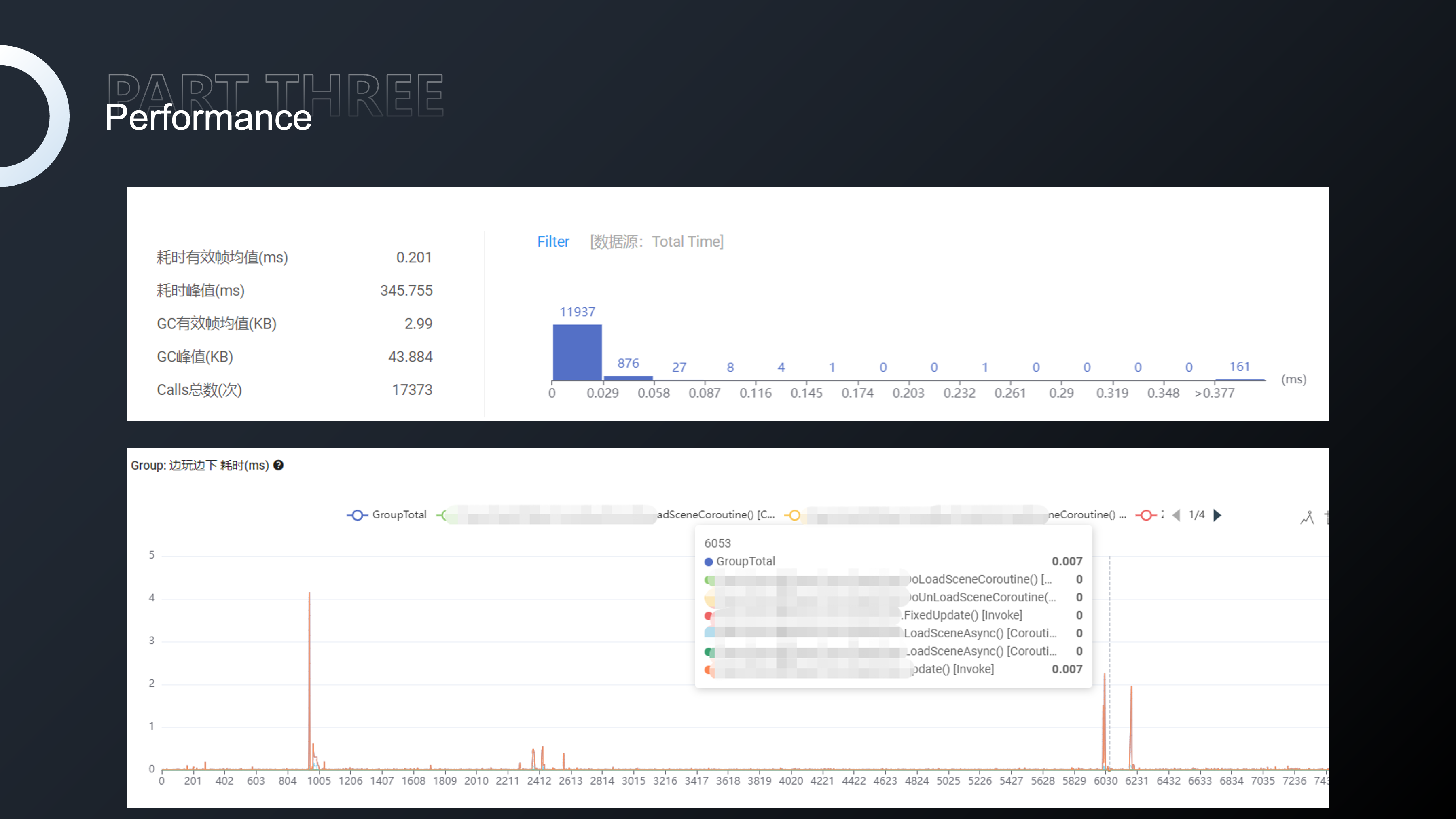
选择UPR之前,我们也针对市面同类型的产品做过许多调研和评估。选择UPR的主要原因在于两点:一,UPR具有0侵入性,不需要借助任何SDK就可以使用这样的工具。二,它能够提供与Unity Editor下相一致的数据,如图中这样的时序图就是与Unity Profiler相一致,可以提供主线程、渲染线程、Job线程等等,看到相应的调用堆栈。
还有与MemoryProfiler相一致的内存分布图,对经常做性能优化的程序同学来说,通过这样一张图,我们可以非常直观地判断哪些纹理是没有被压缩的,哪些Shader不应该在这个场景出现。

我们也可以对某些函数进行打点采样,包括对某一组函数进行打点采样,然后进行整体数据分析。我们可以将Bundle、寻路计算和功能性特定玩法涉及的函数打造成为一个标签进行整体分析和性能对比。
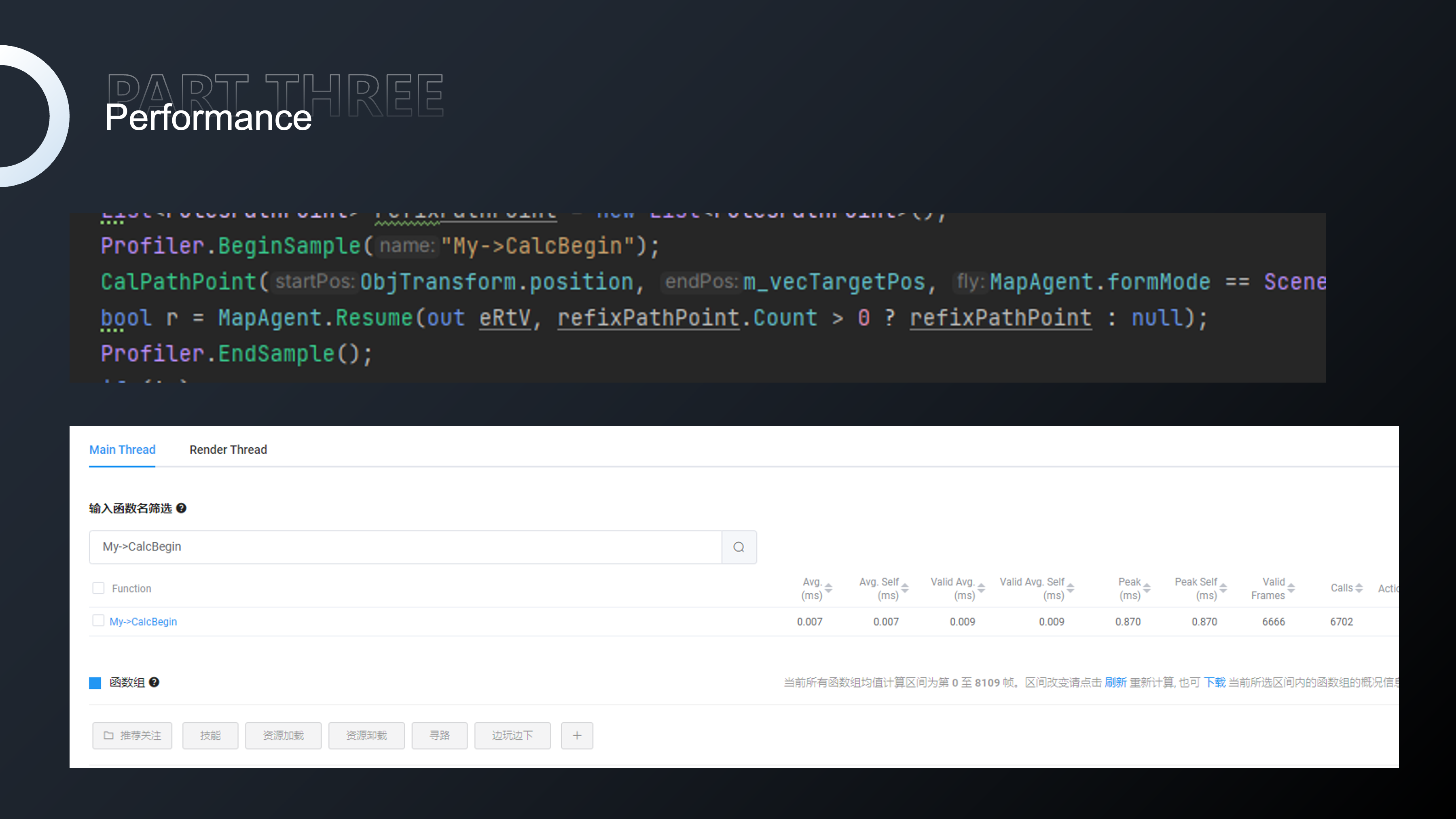
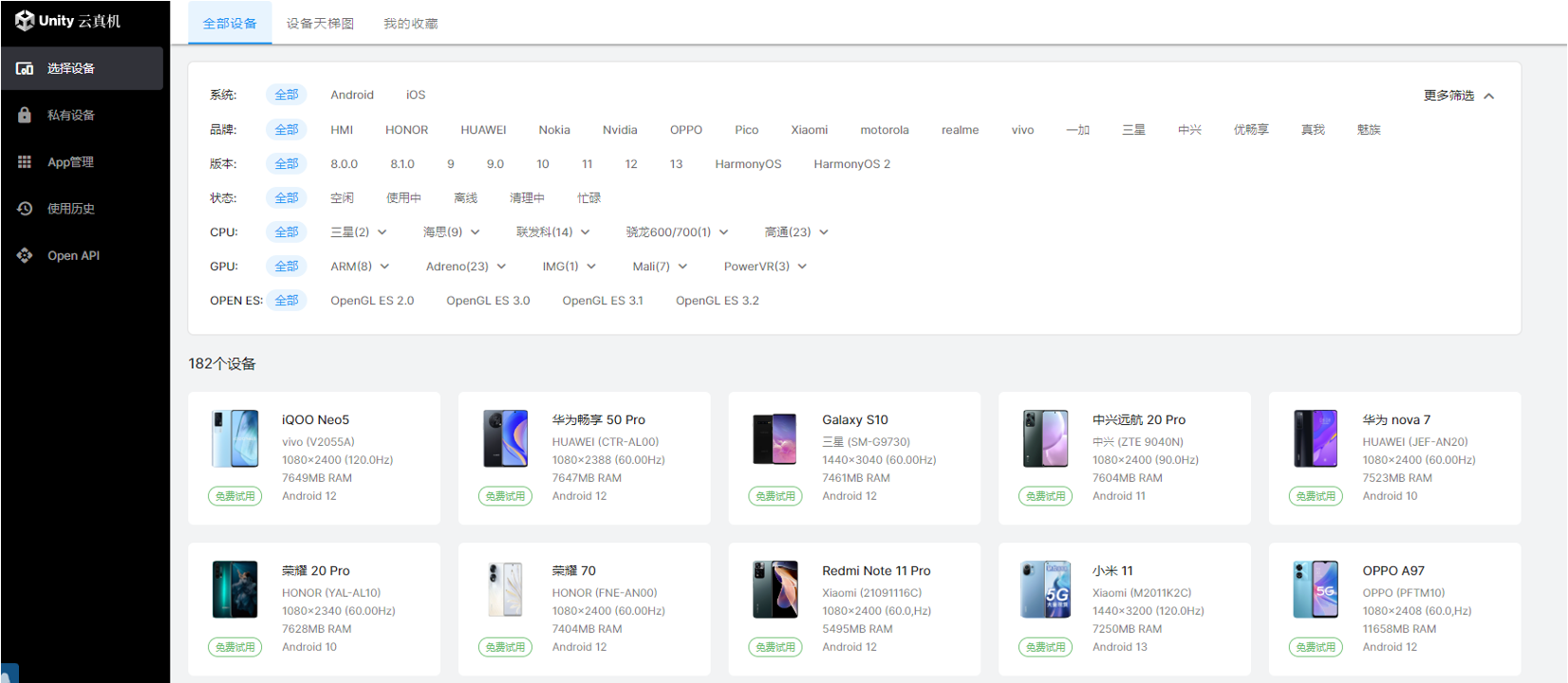
整个引擎升级或者新效果开发的时候也会遇到很多兼容性的问题,一般来说 我们会使用多部设备来确认兼容性的根本原因,是系统问题,还是芯片问题,是否与品牌或者产品型号有关。在我们设备不足时,就会使用云真机来进行兼容性的测试与验证。
谢谢大家!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









