







概述

DeepSeek是由中国杭州深度求索人工智能公司开发的一系列AI大模型,其核心技术架构和训练策略在效率、性能及成本效益上具有显著优势。以下从技术原理及与其他主流模型的对比两方面进行解析:
deepseek原理及对比
deepseek原理及对比
一、DeepSeek的核心原理与技术特点
1. 混合专家架构(MoE)
DeepSeek-V3等模型采用混合专家架构,总参数量高达6710亿,但每个输入仅激活370亿参数,通过动态路由机制选择最相关的专家处理任务,显著降低计算冗余。例如,在处理128K长文本时,推理延迟降低42%。
2. 多头隐式注意力(MLA)
MLA机制通过压缩Key-Value矩阵为低秩潜在向量,将内存占用减少至传统Transformer的1/4,同时保留多头注意力的优势。这一技术在处理长文档和复杂语义关联时表现突出,如法律文本摘要或长篇小说翻译。
3. 训练策略优化
- 主动学习与迁移学习:通过筛选高价值数据标注,减少数据量和算力消耗,提升训练效率。
- FP8混合精度训练:使用8位浮点数表示参数和梯度,在保证精度的同时降低内存需求和训练成本,计算效率达92%。
- 多Token预测(MTP):一次预测未来4个Token,提高代码生成等任务的吞吐量3.8倍。
4. 模型压缩与量化
通过剪枝和量化技术,将模型参数从高精度转为低精度,降低存储和计算需求。例如,70B参数模型可部署在4张A100显卡上,推理成本仅需$0.00012/token。
5. 强化学习与冷启动策略
DeepSeek-R1采用纯强化学习范式,仅需200个思维链样例即可启动训练,并通过群体相对策略优化(GRPO)提升训练稳定性65%,在数学推理任务中准确率达81.2%。
二、DeepSeek与其他主流AI模型的对比
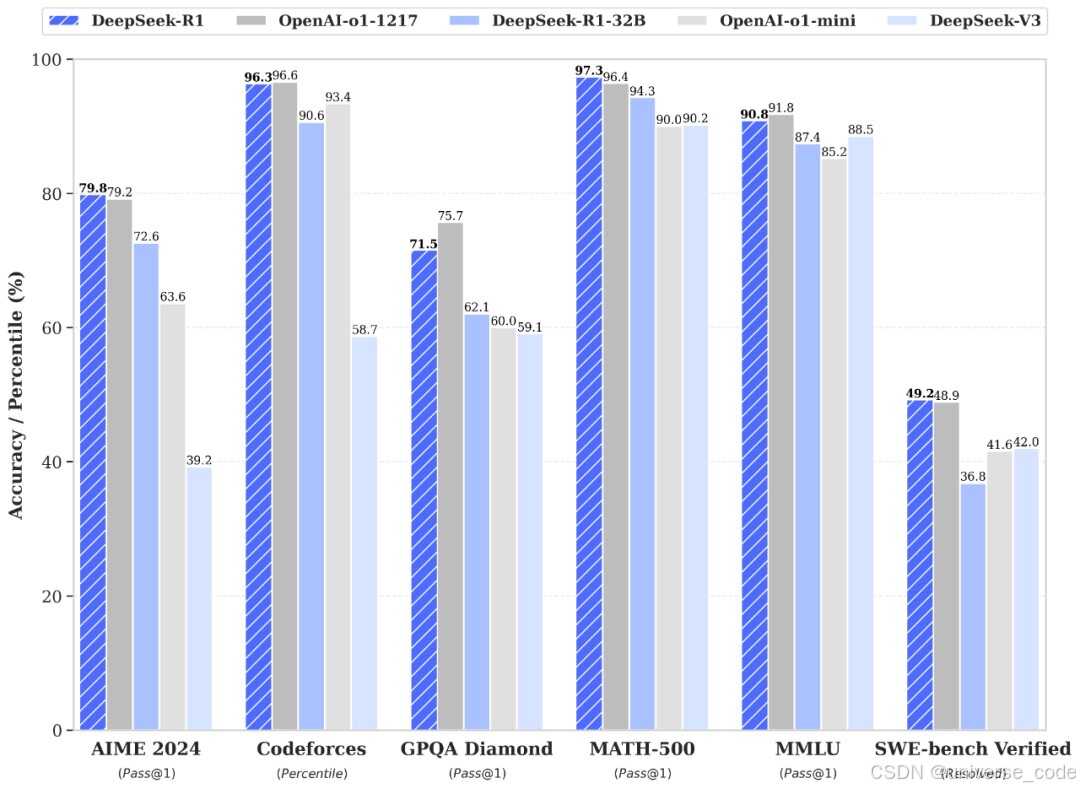
1. 架构差异
- DeepSeek vs GPT系列:
GPT系列基于纯Transformer解码器架构,依赖大规模参数(如GPT-4约1.8万亿参数),而DeepSeek采用MoE架构,通过动态激活参数降低计算量,在相同任务下训练成本仅为GPT-3的50%。 - DeepSeek vs Gemini:
Gemini侧重多模态融合,但纯文本任务表现较弱ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









