







爬虫流程
1. 确定目标网址和所需内容
https://www.jiansheku.com/search/enterprise/
只是个学习案例,所以目标就有我自己来选择,企业名称,法定代表人,注册资本,成立日期

2. 对目标网站,进行分析
-
动态内容分析:
JS和Ajax请求:确定页面是否使用JavaScript动态加载内容,如果是,需要分析Ajax请求以获取数据的API。
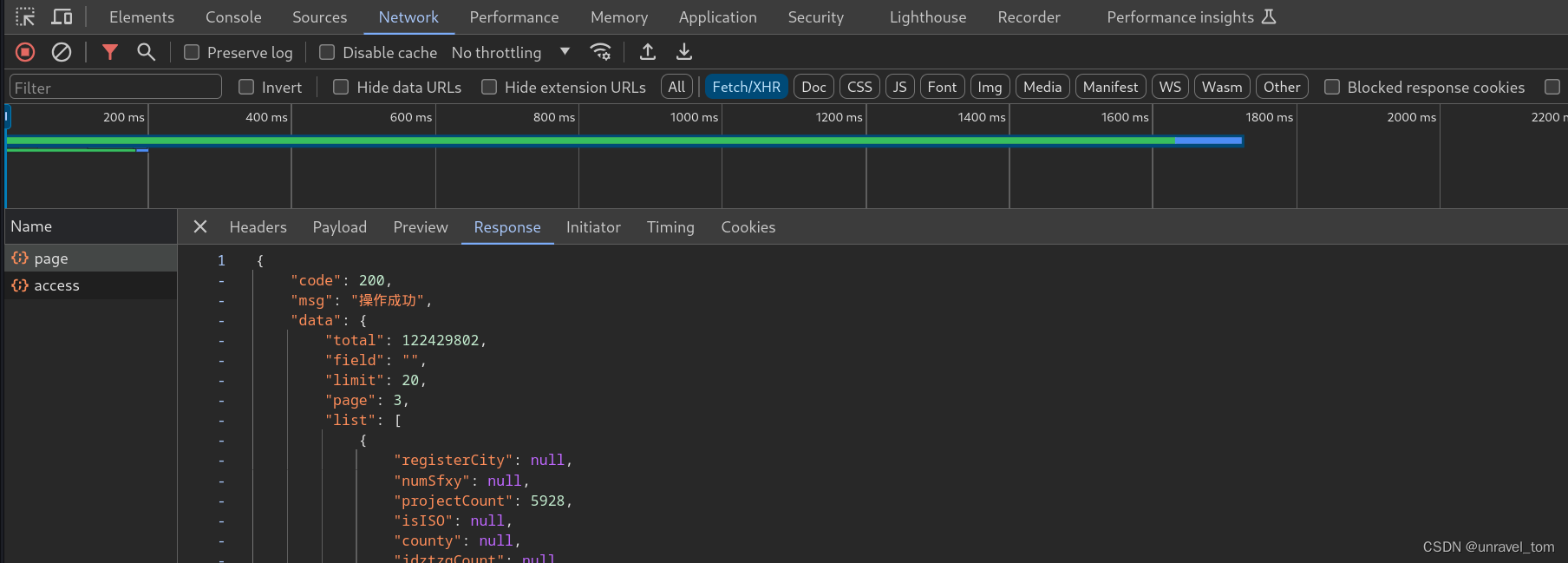 进行页面切换,抓去Ajax,发现page里面的response携带这我们所需要的数据
进行页面切换,抓去Ajax,发现page里面的response携带这我们所需要的数据找到动态变化值,一般在
headers,或者payload中,动态变化值,可能就是影响批量爬虫的关键
例中的payload是明文数据,headers中sign,timestamp是动态变化值
3 .找到加密的入口
靠经验,运气,猜测,分析代码,观察数据,调试代码,逆向分析,等等。
使用关键字搜索,断点,调用堆栈等方法。
这里我使用关键字搜索
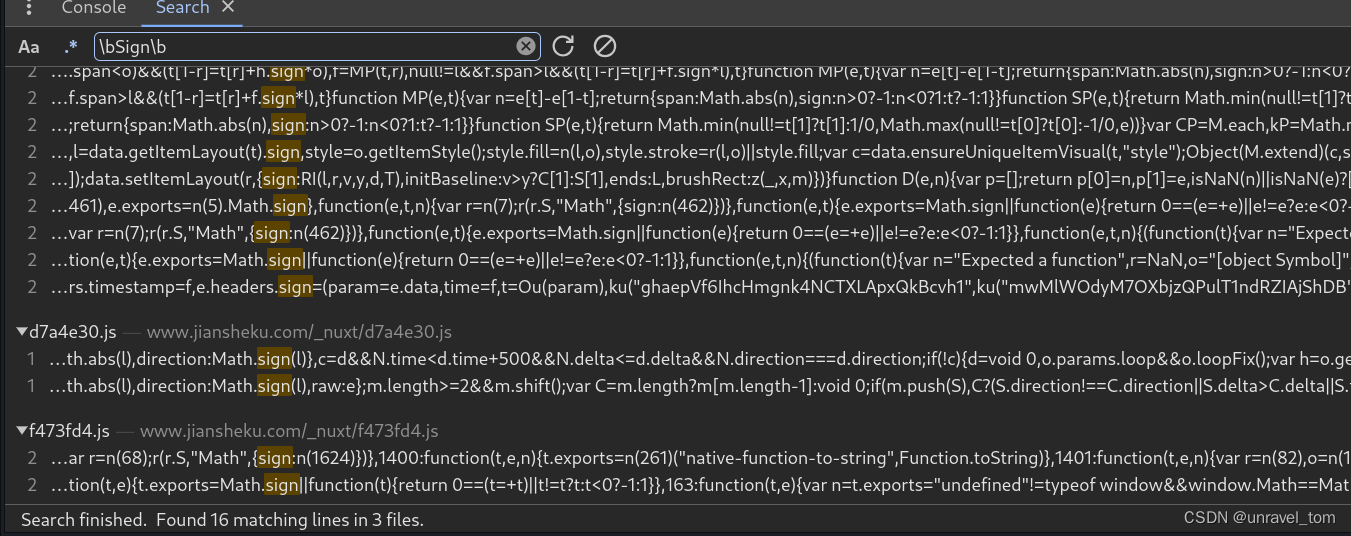
使用正则表达式搜索缩小搜索范围,勾选“Use Regular Expression”或.*并输入正则表达式,如\bSign\b—\b确定搜索边界
像Math.sign这种是js的数学库文件,可以直接排除,就10几个,慢慢排查,使用断点调试
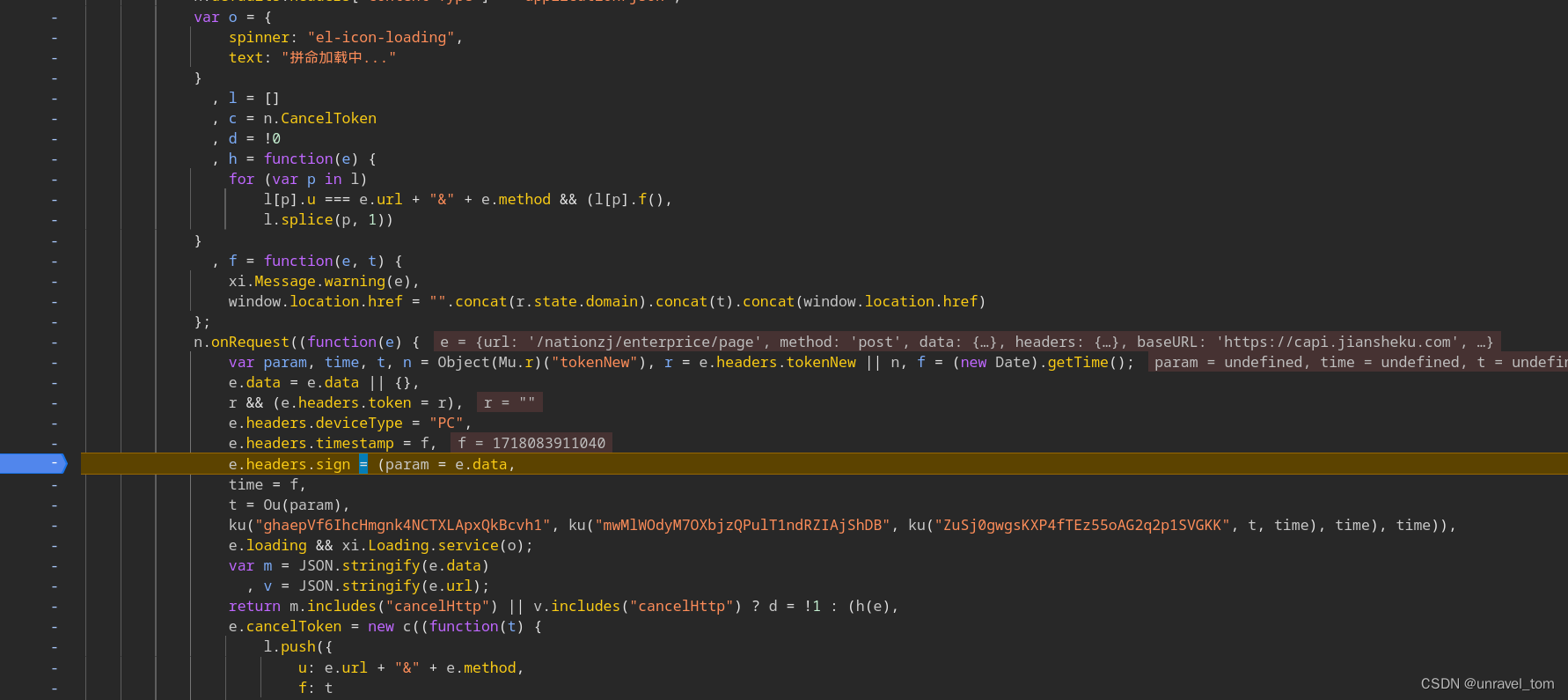
这里就是目标,注意这里使用了js的逗号表达式,想要查看结果悬浮,或者在控制台中查看,注意你要在断点的作用域内,函数是有生命周期的
4. 扣js代码
复制js代码,模拟浏览器加密过程
这里我发现一个好用的小技巧,使用单步调试,从断点开始出发查看经过的函数基本都是我们所需的js代码,途中会跳转到其他的js文件(webpack)然后回来就可一看见MD5加密的算法了

5. 写代码
- 请求模拟
- 获取js逆向值
- py调用js
- 数据清洗
- 数据存储
- 处理反爬机制(ip封禁)
注意事项
- 下载packages的时候过慢,pip和node我都会给出镜像源
- 我使用的是Linux:
pip install PyExecJS2,Windows:pip install PyExecJS,不行就两个都试一遍 - google在浏览器开发者工具中不让粘贴,可在控制台输入
allow pasting - 本来打算以csv文件保存,但是爬取页数一多,就打不开csv文件,所以就保存为txt
- 最好不要使用异步模块,这个爬取的速度不会太慢,爬取的太快服务区可能不会响应
- 不要大量爬去,该网站会封IP(使用代理池就可以了)
packages
- pip
# 模拟浏览器发送请求
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
# 在py中调用js
pip install PyExecJS2 -i https://mirrors.aliyun.com/pypi/simple/
# 方便实时预览进度
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
- npm
# 使用淘宝源
npm config set registry https://registry.npm.taobao.org
# 我遇到了证书过期(可能是我设置的是外国时区,使用的是国内的源),设置 npm 忽略 SSL 证书错误
npm config set strict-ssl false
npm install crypto-js
python code
import requests
import time
import execjs
import json
from tqdm import tqdm
def fetch_data(page, timer):
json_data = {
'eid': '',
'achievementQueryType': 'and',
'achievementQueryDto': [],
'personnelQueryDto': {
'queryType': 'and',
},
'aptitudeQueryDto': {
'queryType': 'and',
'nameStr': '',
'aptitudeQueryType': 'and',
'businessScopeQueryType': 'or',
'filePlaceType': '1',
'aptitudeDtoList': [
{
'codeStr': '',
'queryType': 'and',
'aptitudeType': 'qualification',
},
],
'aptitudeSource': 'new' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









