






一、训练、验证、测试集
样本数据分成以下三个部分:
训练集(train set): 用于对模型进行训练。
验证集(hold-out cross validation/development set): 对不同模型进行评估。
测试集(test set): 对选取的模型进行无偏评估。
node: 验证集要和训练集最好来自于同一个分布,可以使得机器学习算法变快。如果不需要用无偏估计来评估模型的性能,则可以不需要测试集。
数据的量的分配:
数据量较小时(小于10000):70% / 30% 或 60% / 20% / 20%;
数据量较大时:通常验证和测试集主要是评估不同模型,数据量不需要太大,足够就行。根据数据量的增加减少验证和测试集的比例。百万数据时 98% / 1% / 1%。
二、偏差和方差
偏差(bias):由训练集的error决定:error 大是高偏差(hight bias)
方差(variance):由训练集和验证集的error决定:训练集error 远小于验证集error 是高方差(hight bias)
node: 这里的大小是相对于最优误差也称为“贝叶斯误差”的,例如:以人眼判别误差为“贝叶斯误差”,人眼误差为0%时16%的误差大,如果人眼为15%时16%的误差小。
欠拟合(underfitting): 高偏差
improve:更复杂的网络结构(bigger network),增加layer 或 hidden unit;增加迭代次数;寻找更合适的网络;
过拟合(overfitting): 高方差
improve: 更多的数据(more data); 正则化(regularization); 寻找更合适的网络;
三、正则化(regularization)
作用:防止 overfitting, 即消除High variance
Logistic regression:
在 cost function 中增加正则化项:
为正则化因子。正则化项有很多种,通常使用上式的L2向量范数(norm)。

Neural network:
在 cost function 中增加正则化项:
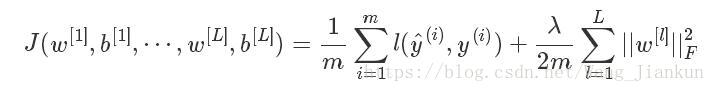
上式的正则化项使用了“Frobenius ”矩阵范数。
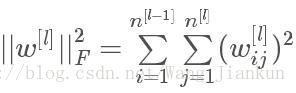
Weight decay:正则化也视为权重衰减
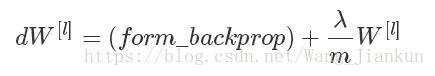
求梯度:
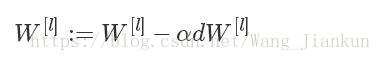
梯度更新
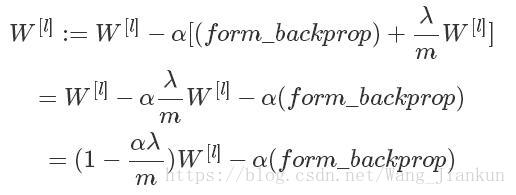
因为(1−α*λ/m)<1,所以W[l]一定会变小,因此称为权重衰减(Weight decay)
正则化是怎样防止overfitting的:
直观理解:
当正则化因子λ足够大时,为了最小化 cost function,权重矩阵W会变得很小,接近于0。可以理解为很多w=0,即消除了这些神经元,所以神经网络就会变成一个较小的网络。实际上隐藏层的神经元依然存在,只是它们的值趋于0影响变的很小,使得网络学习特征的能力变弱,这样就可以达到防止过拟合的效果。
数学原理:
以激活函数为g(z)=tanh(z)为例:

当λ增大,W[l]减小,Z[l]=W[l]a[l−1]+b[l]Z[l]也会变小。由激活函数的图像得,在z较小的区域里,tanh(z)函数近似线性,所以每层的函数就为近似的线性函数,整个网络就成为一个简单的近似线性的网络,从而防止过拟合。
四、Dropout Regularization
Dropout: 称为随机失活,即在训练每一个example时随机删除神经网络的unit,使得网络变小,对于每一个example删除的unit可能不一样。keep_prob: 每个 unit 被保留的概率。
node: 训练时dropout,验证或测试时不用,因为那样会使得预测结果变得随机。
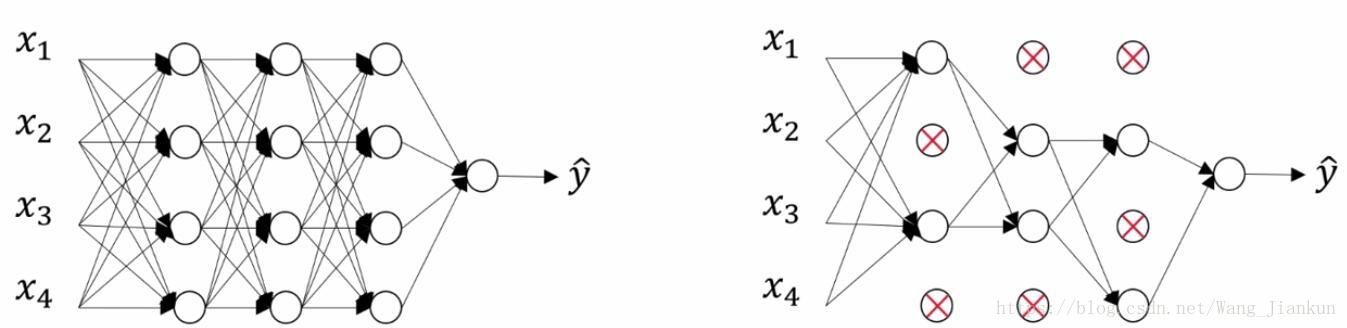
理解 Dropout:
以一个unit为例:
在网络中加入了Dropout后,unit的每一个输入都有可能会被随机删除,所以该unit不会再严重依赖于任何一个输入,即不会给任何一个输入设置太大的权重。所以通过传播过程,dropout将产生和L2范数相同的收缩权重的效果。
可以在不同的层,设置不同的keep_prob。通常在unit较少的层可以设为1。unit越多的层可以把它设的越小。
Dropout的缺点:采用Dropout使得 Cost function 不能再被明确的定义,因为每次迭代都会随机消除一些unit,所以无法绘制出J(W,b)迭代下降的图。所以通常先关dropout功能,即设置 keep_prob = 1.0。训练网络,确保J(W,b)函数单调递减后
再打开dropout。
五、其它正则化方法
数据扩增(Data augmentation):通过对图片进行变换,如:水平翻转、随机裁剪、扭曲等,得到更多的样本。
提前停止训练(Early stopping):在交叉验证集的误差上升之前的点停止迭代,避免过拟合。这样会同时停止优化cost function,即增大bias。所以这种方法的缺点是无法同时解决bias和variance之间的最优。
Speed up trainnig
六、正则化输入(归一化)
各特征的数值范围相差很大时需要归一化。如:0-1000 和 0-1。在不确定是否需要归一化时,都进行归一化,因为它不会有坏的影响。
计算各特征值所有样本数据的均值:
使各样本所有样本均值=0:x =x-uv
使个样本所有样本方差=1
作用:加速训练,更快收敛
最优化 cost function 时没归一化的迭代次数远多于有归一化。
七、梯度消失&梯度爆炸
梯度消失(vanishing gradients): 梯度指数级递减
梯度爆炸(exploding gradients): 梯度指数级递增
处理梯度消失和爆炸: 使用初始化策略
以单个unit为例:
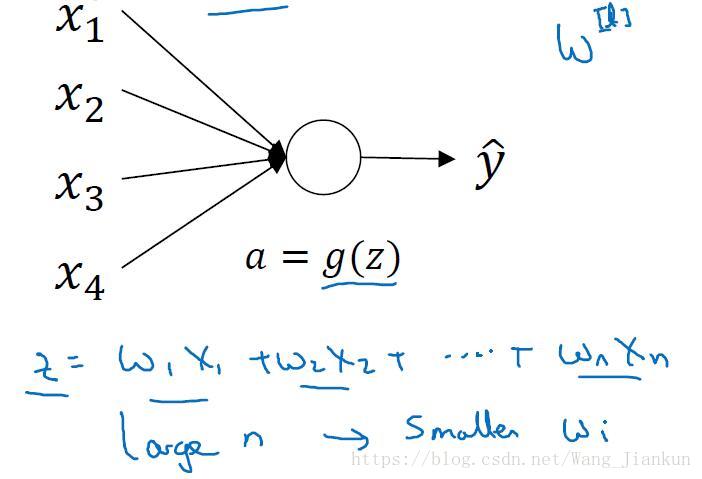
当输入特征n变大时,wi值要变小,使得z保持合理的值。可以设置wi=(1/n)*wi。
初始化代码
#激活函数为tanh时,n为输入特征数,使用Xavier initialization
WL = np.random.randn(WL.shape[0],WL.shape[1])* np.sqrt(1/n)
#激活函数为ReLU时,使用 He initialization
WL = np.random.randn(WL.shape[0],WL.shape[1])* np.sqrt(2/n)
八、梯度检验(Gradient Checking)
梯度的数值逼近: 使用双边误差的方法逼近导数
梯度检验:
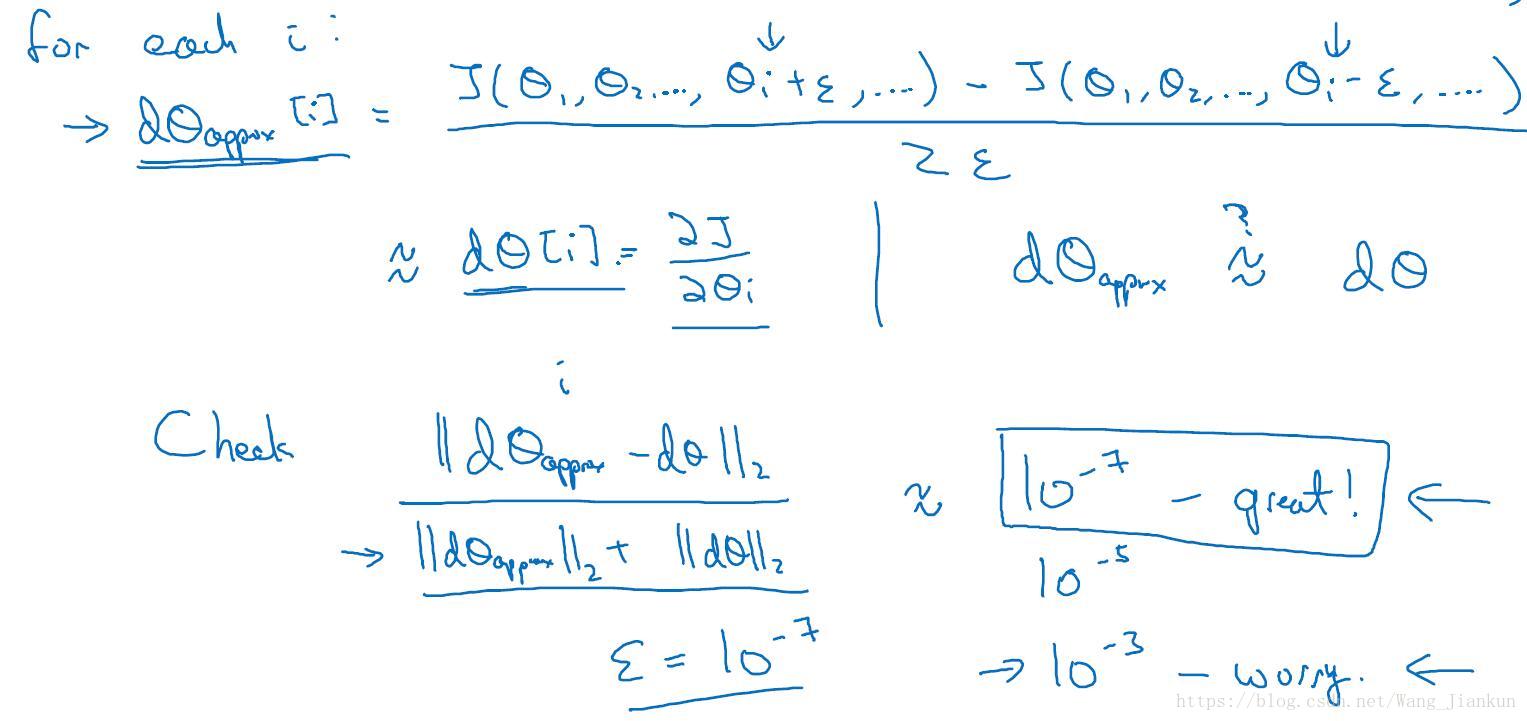















 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









