







原文地址:http://blog.csdn.net/uq_jin/article/details/51451995
如果你还没有虚拟机,请参考:http://blog.csdn.net/uq_jin/article/details/51355124
如果你还没有配置JAVA,请参考:http://blog.csdn.net/uq_jin/article/details/51356799
参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
下载安装Hadoop
1、下载地址
http://hadoop.apache.org/releases.html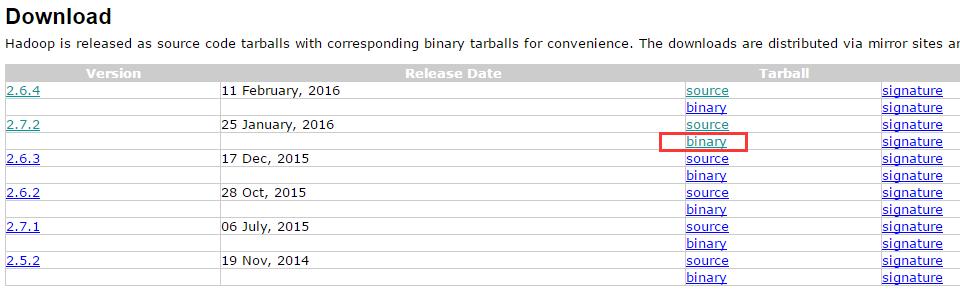
我下载的是2.7.2,官网在2.5之后默认提供的就是64位的,这里直接下载下来用即可
2、安装Hadoop
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/soft3、查看Hadoop是32 or 64 位
参考:http://www.aboutyun.com/thread-12796-1-1.html
cd /opt/soft/hadoop-2.7.2/lib/native
file libhadoop.so.1.0.0
4、配置/etc/hosts
vi /etc/hosts
配置启动Hadoop
1、修改hadoop2.7.2/etc/hadoop/hadoop-env.sh指定JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/opt/soft/jdk1.8.0_912、修改hdfs的配置文件
修改hadoop2.7.2/etc/hadoop/core-site.xml 如下:
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://singlenode:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop-2.7.2/tmp</value>
</property>
</configuration>这里fs.defaultFS的value最好是写本机的静态IP当然写本机主机名,再配置hosts是最好的,如果用localhost,然后在windows用java操作hdfs的时候,会连接不上主机。
修改hadoop2.7.2/etc/hadoop/hdfs-site.xml 如下:
<configuration>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3、配置SSH免密码登录
配置前:
ssh localhost
会出现如上效果,要求我输入本机登录密码
配置方法:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys配置后,不用密码可以直接登录了

4、hdfs启动与停止
第一次启动得先格式化(最好不要复制):
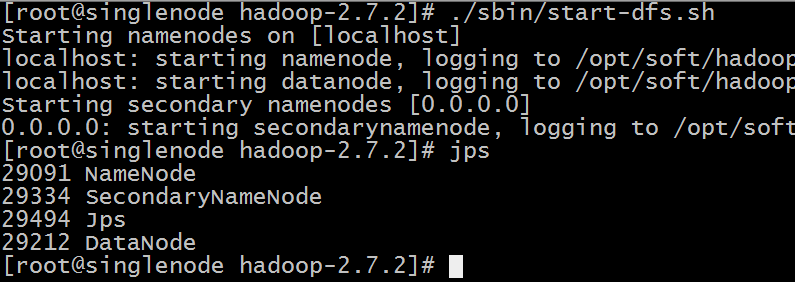
./bin/hdfs namenode –format启动hdfs
./sbin/start-dfs.sh看到如下效果表示成功:
测试用浏览器访问:(如果没响应,则开发50070端口)
firewall-cmd --zone=public --add-port=50070/tcp --permanent
firewall-cmd --reloadhttp://192.168.2.100:50070/效果如下:
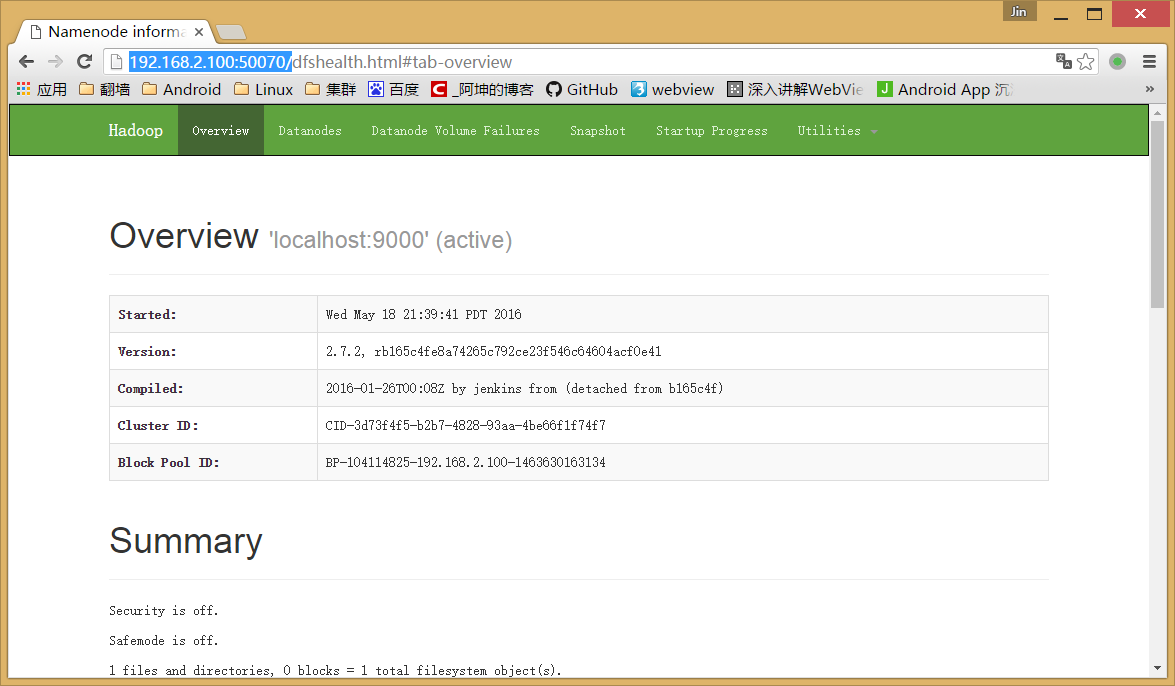
停止hdfs
sbin/stop-dfs.sh5、常用操作:
HDFS shell
查看帮助
hadoop fs -help <cmd>上传
hadoop fs -put <linux上文件> <hdfs上的路径>查看文件内容
hadoop fs -cat <hdfs上的路径>查看文件列表
hadoop fs -ls /下载文件
hadoop fs -get <hdfs上的路径> <linux上文件>上传文件测试
创建一个words.txt 文件并上传
vi words.txt
Hello World
Hello Tom
Hello Jack
Hello Hadoop
Bye hadoop将words.txt上传到hdfs的根目录
bin/hadoop fs -put words.txt /可以通过浏览器访问:http://192.168.2.100:50070/
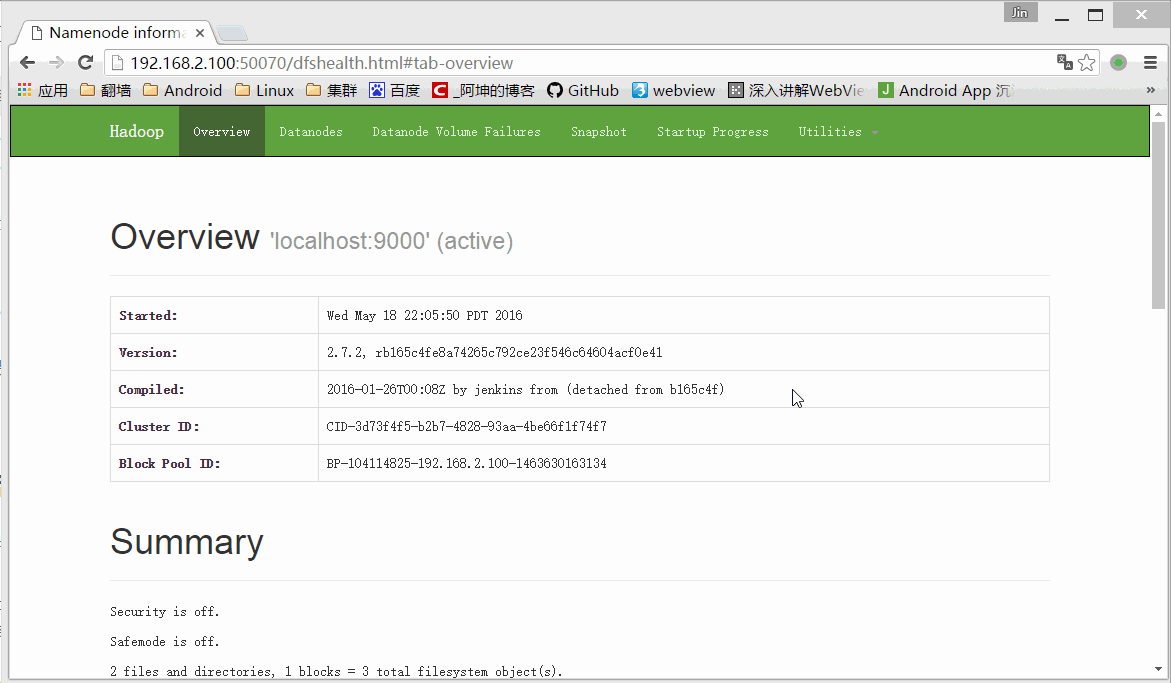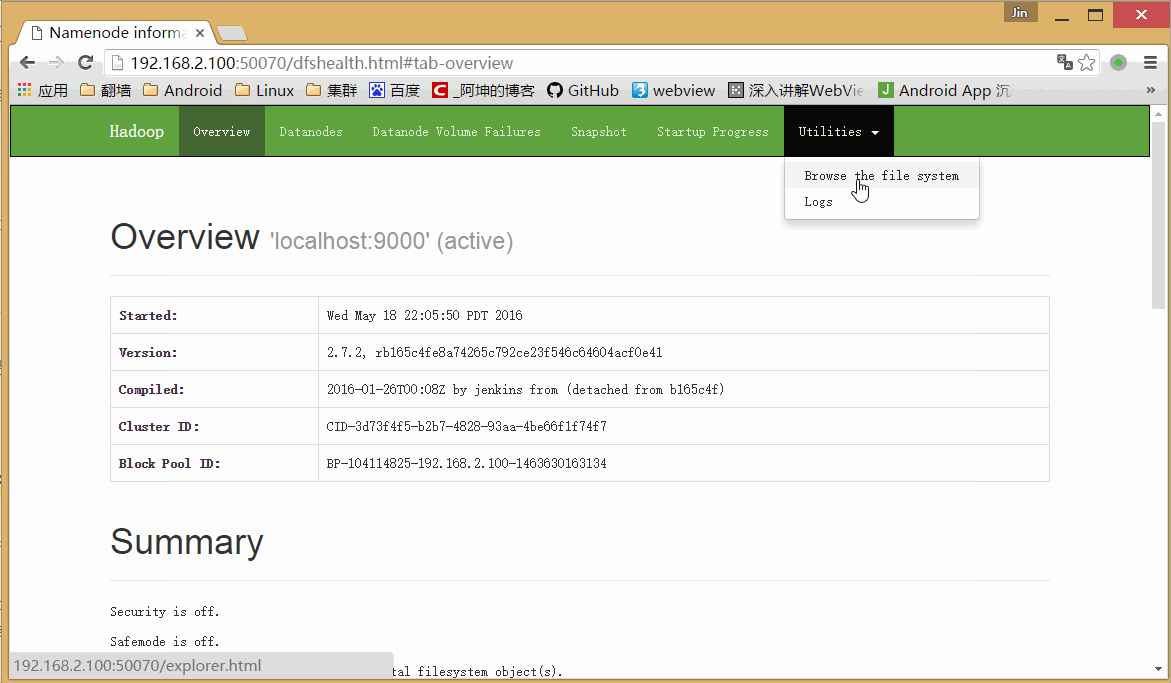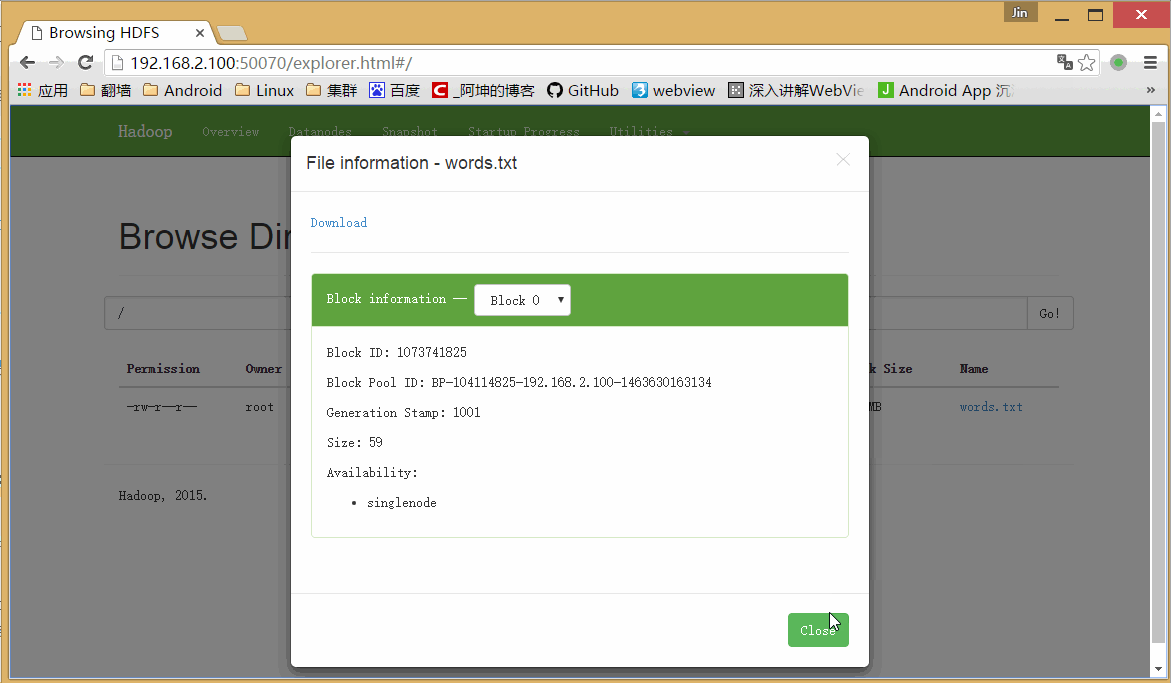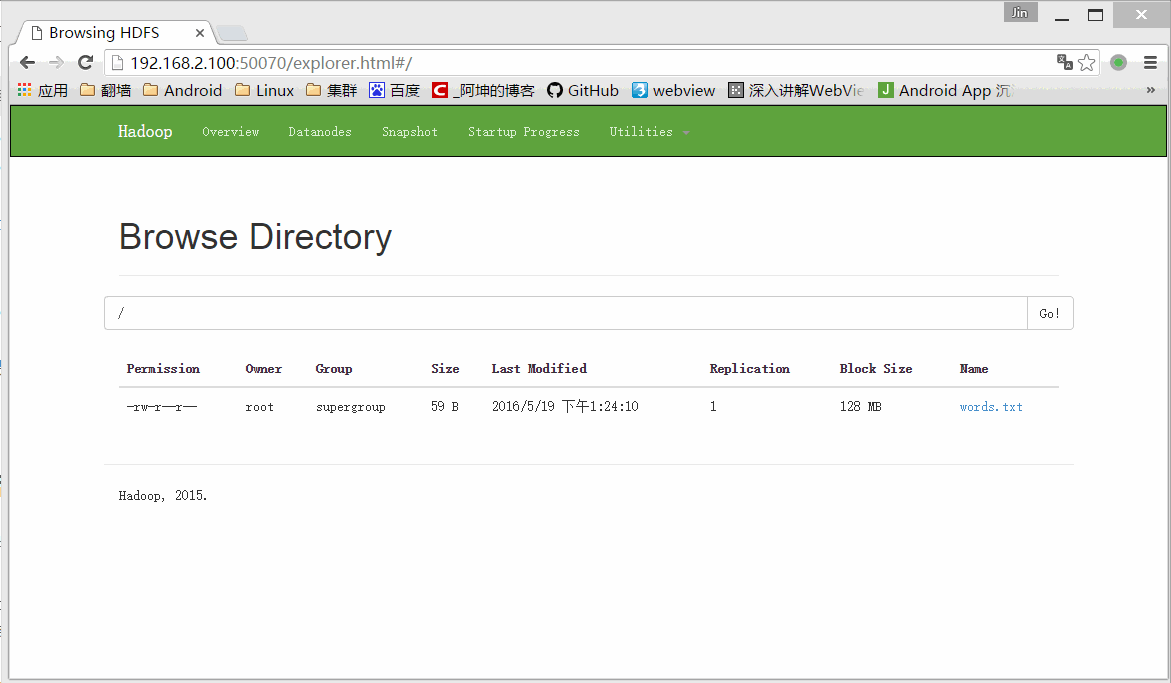
这里的words.txt就是我们上传的words.txt
配置启动YARN
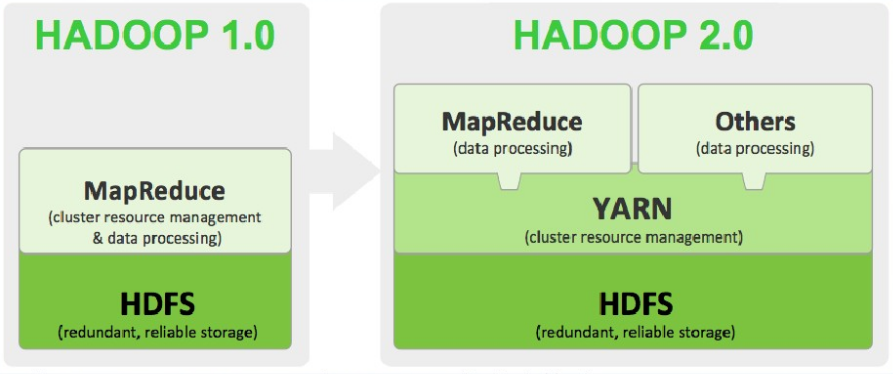
从上图看看出我们的MapReduce是运行在YARN上的,而YARN是运行在HDFS之上的,我们已经安装了HDFS现在来配置启动YARN,然后运行一个WordCount程序。
1、配置etc/hadoop/mapred-site.xml:
mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2、配置etc/hadoop/yarn-site.xml:
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>3、YARN的启动与停止
启动
./sbin/start-yarn.sh如下:
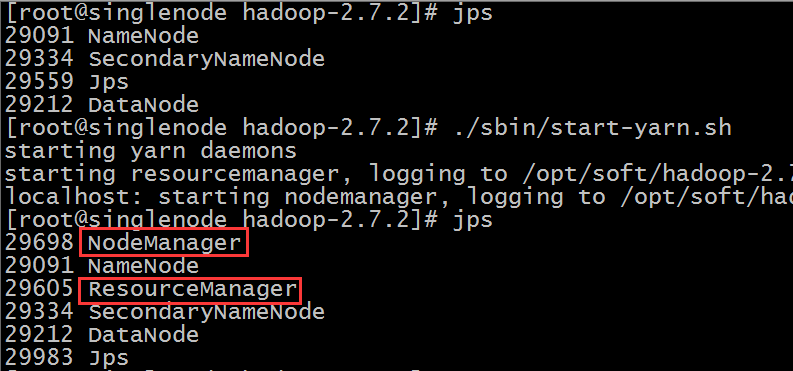
测试用浏览器访问:(如果没响应,则开发8088端口)
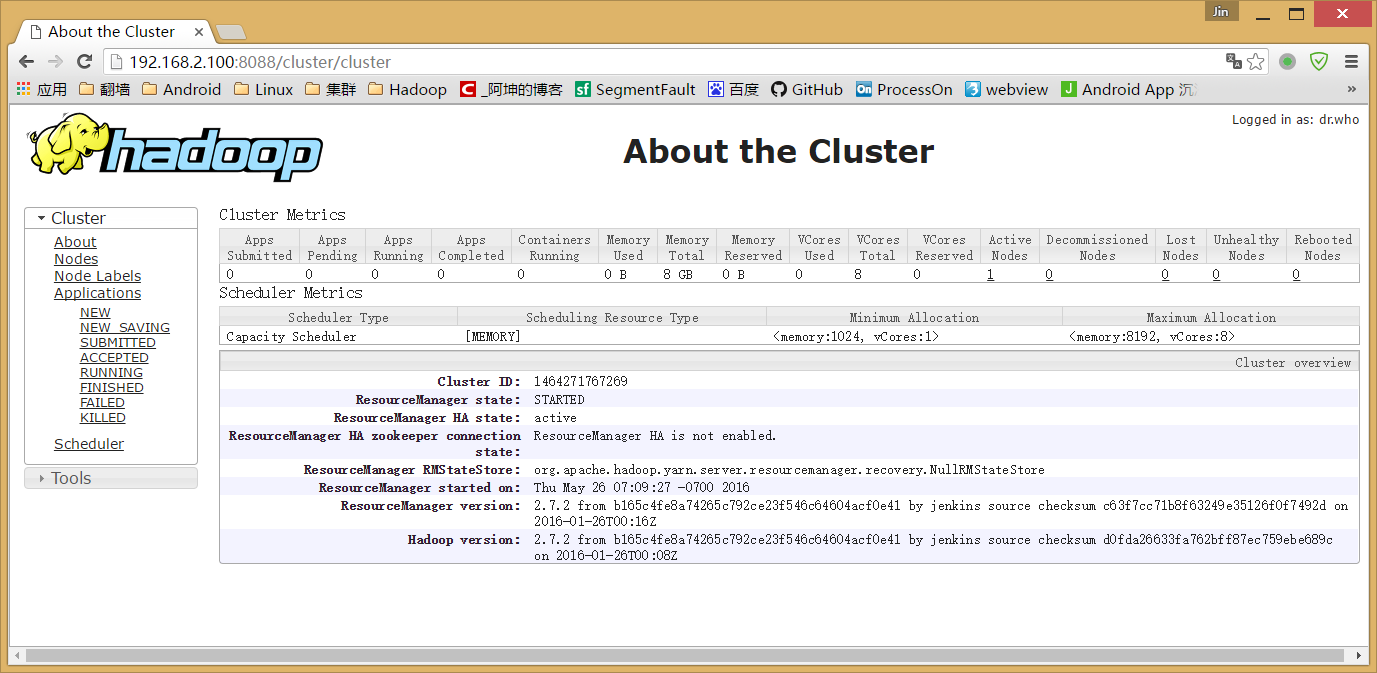
停止
sbin/stop-yarn.sh现在我们的hdfs和yarn都运行成功了,我们开始运行一个WordCount的MP程序来测试我们的单机模式集群是否可以正常工作。
运行一个简单的MP程序
我们的MapperReduce将会跑在YARN上,结果将存在HDFS上:
./bin/hadoop jar /opt/soft/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount hdfs://localhost:9000/words.txt hdfs://localhost:9000/out用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,其中输入参数为 hdfs上根目录的words.txt 文件,而输出路径为 hdfs跟目录下的out目录,运行过程如下:
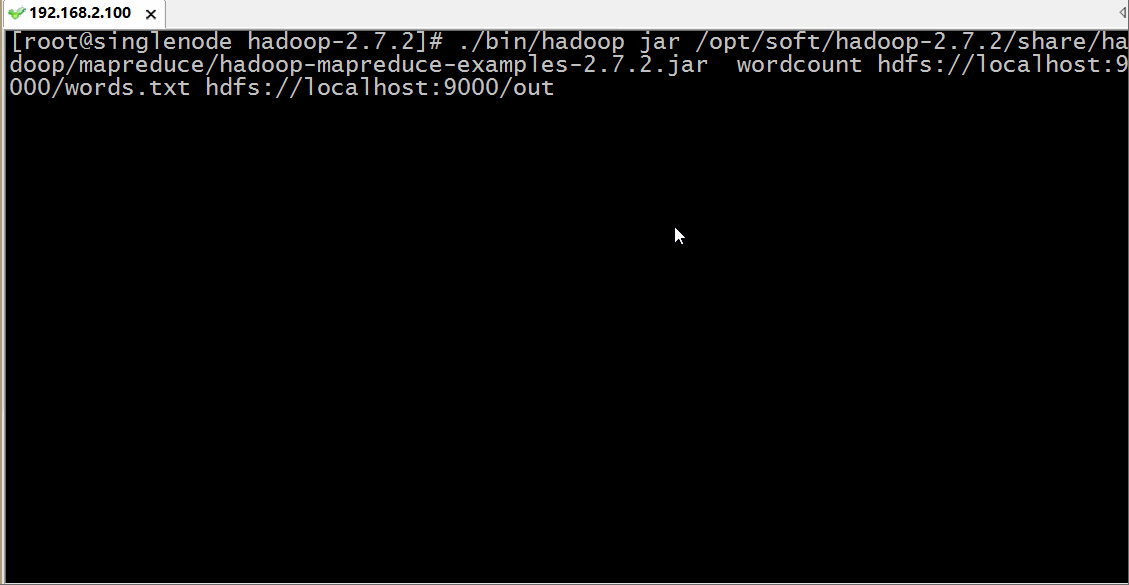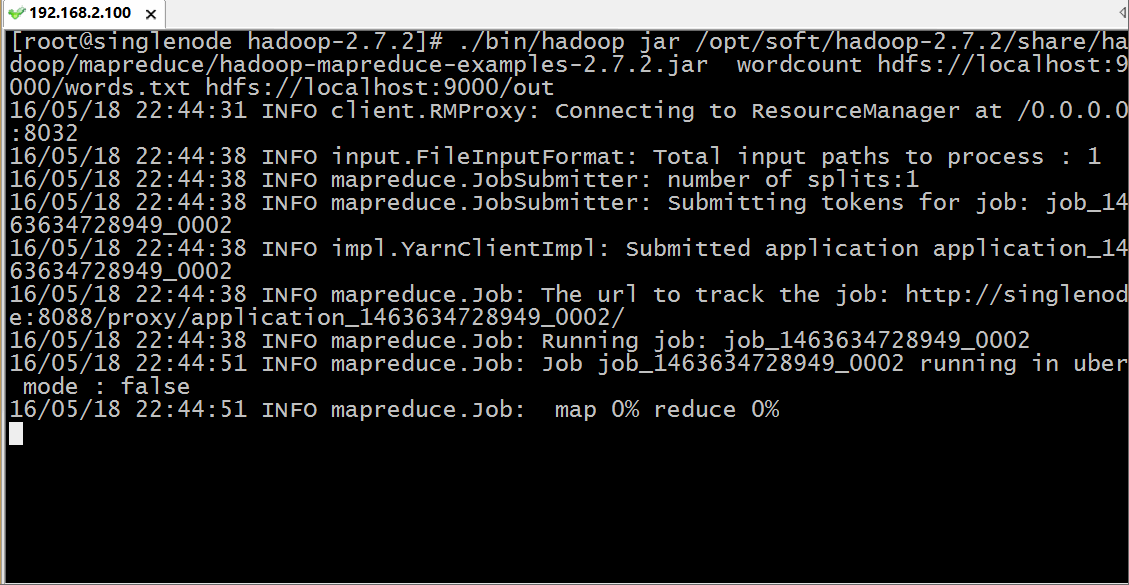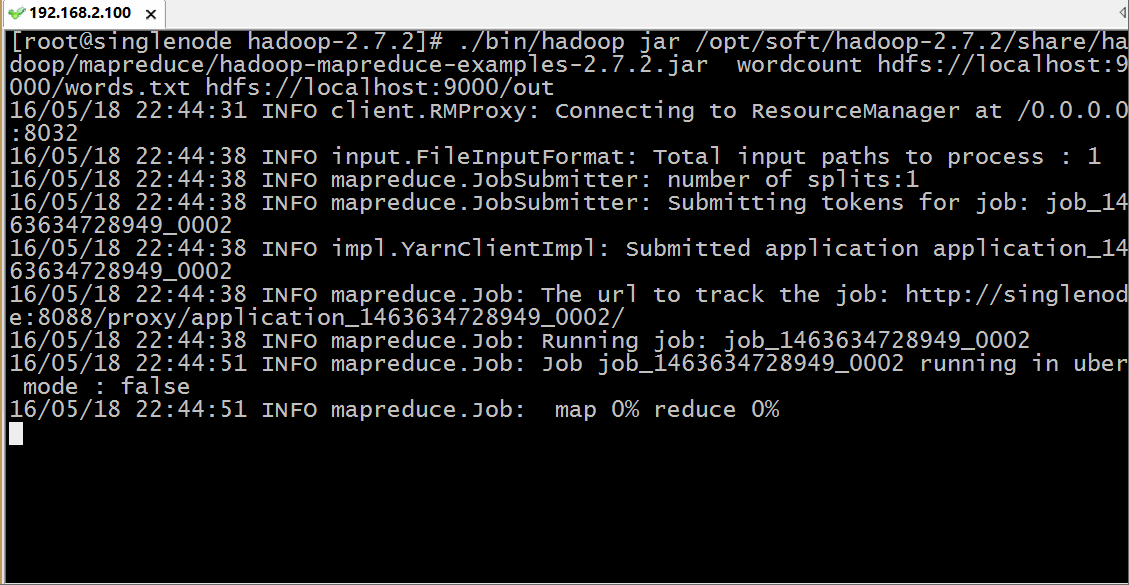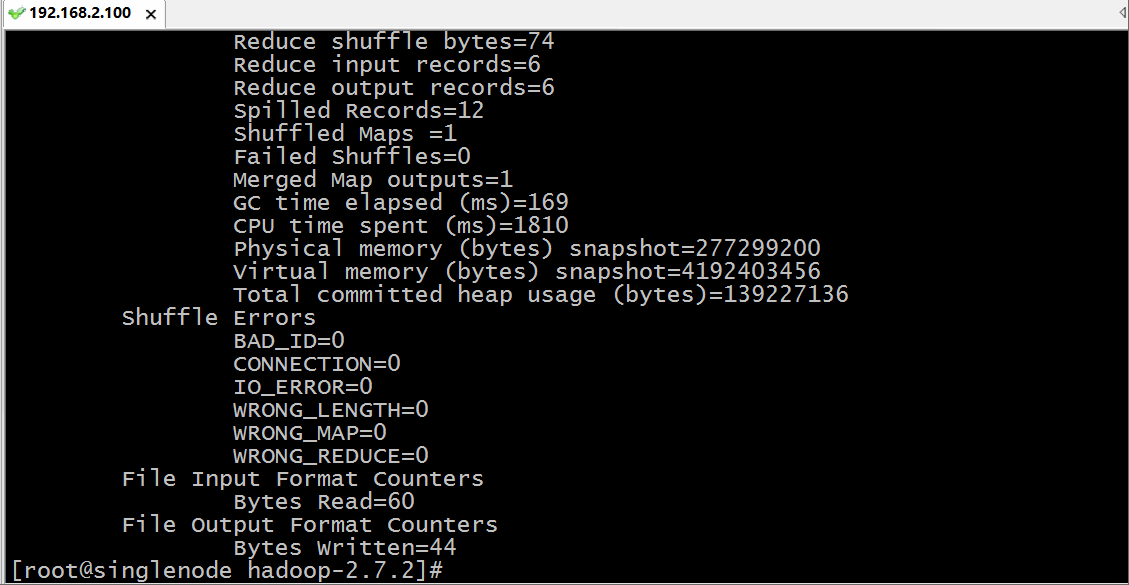
我们通过浏览器访问和下载查看结果:
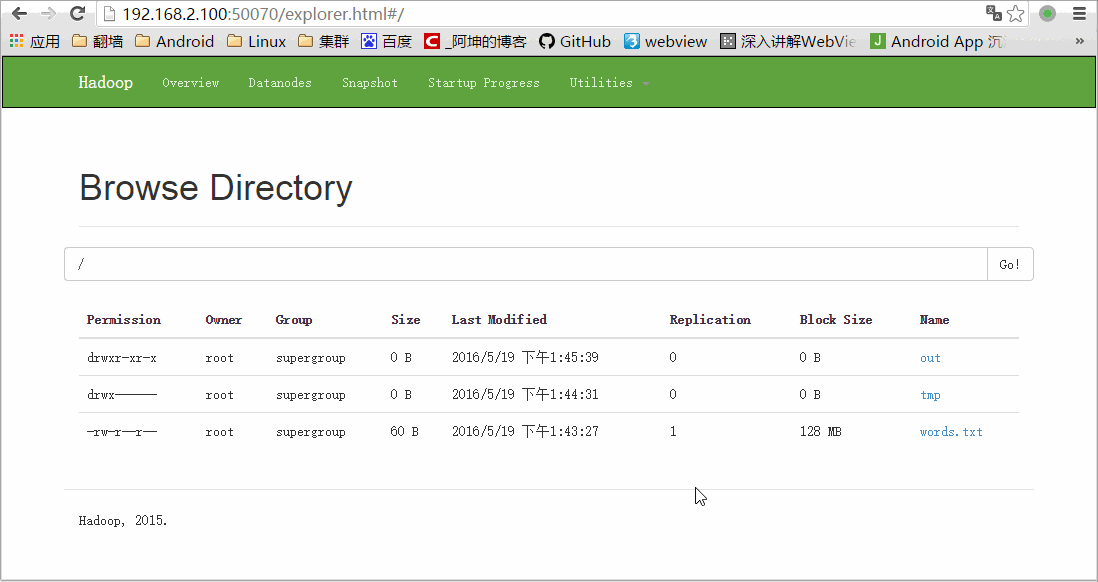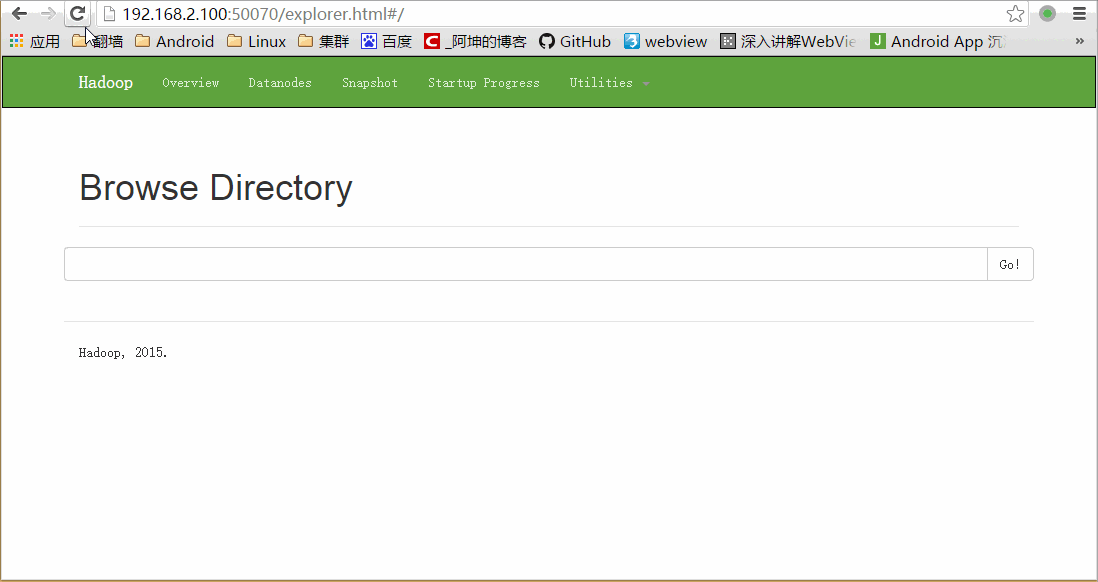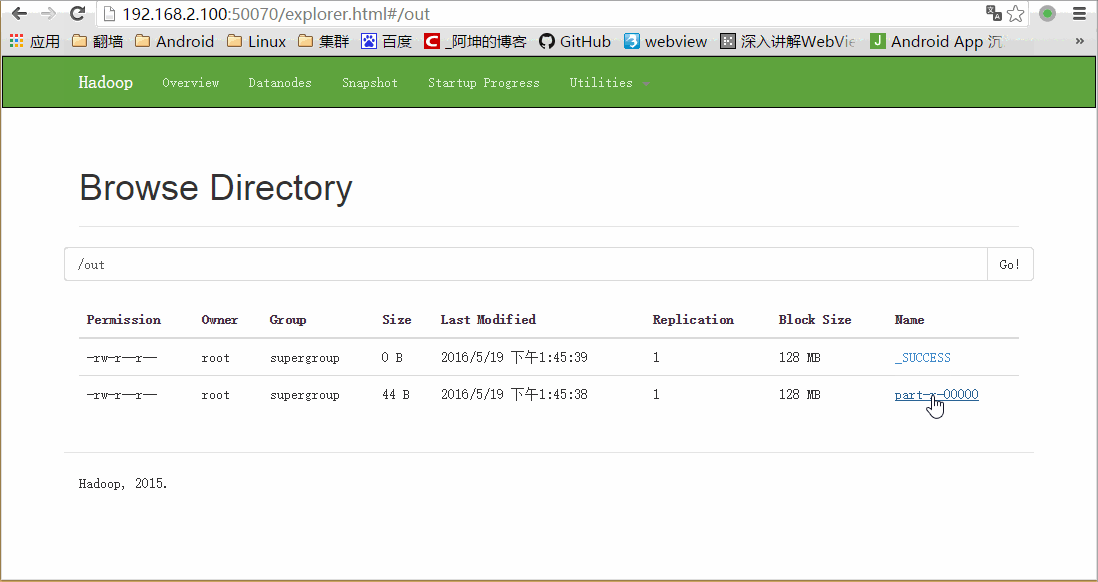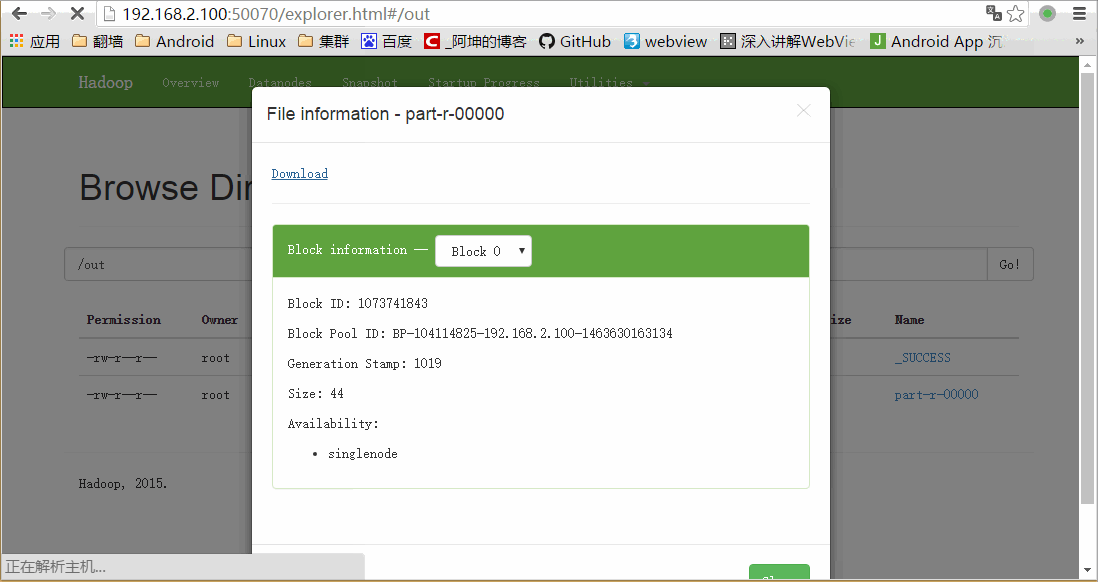
这里下载的时候会跳转到另一个地址如下:
http://singlenode:50075/webhdfs/v1/out/part-r-00000?op=OPEN&namenoderpcaddress=localhost:9000&offset=01、需把singlenode换成192.168.2.100或是在hosts里加入 192.168.2.100 singlenode 隐射关系
2、需开放50075端口。
下载下来结果如下:
Bye 1
Hadoop 2
Hello 4
Jack 1
Tom 1
World 1说明我们已经计算出了,单词出现的次数。
至此,我们Hadoop的单机模式搭建成功。















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









