






文章目录
摘要
本周阅读了一篇关于手写识别CNN的文章,文中使用级联CNN的方法,使得手写识别的准确率进一步提高。然后对分类任务使用的生成模型、判别模型进行学习,通过这些学习,进一步加深对分类任务的理解。
Abstract
This week, I read an article about handwriting recognition CNN, which uses a cascaded CNN method to further improve the accuracy of handwriting recognition. Then learn the generation model and discrimination model used in the classification task. Through these studies,further deepen the understanding of the classification task.
文献阅读
题目
A discriminative cascade CNN model for offline handwritten digit recognition
Introduction
现有的手写自动识别算法,例如KNN、SVM、MQDF、NN、CNN等,已经取得了很多的成果,其中CNN是较高性能的算法,六层神经网络已经实现了0.35%的错误率。由于不同CNN架构之间的互补性,组合多个CNN可以获得更好的结果。但CNN有一些天生的缺点,CNN没有充分利用上分类错误的样本,单个网络的性能与其他网络的互补性有所限制。本文致力于寻求一种在神经网络相对较少的情况下也能更好进行网络融合的方法,即离线手写字符判别级联模型。
CNN模型
卷积层
CNN是分层神经网络,包括两个部分:特征提取层和分类层。特征提取部分由交替的卷积层和子采样层组成。卷积层由以下参数化:映射的数量(M)、映射的大小(Mx,My)、内核大小(Kx,Ky)和跳过因子(Sx,Sy)[11]。输出映射大小定义为:
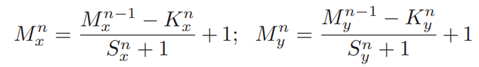
其中n指示层索引。令Ln指示网络中的第n层。Ln中的每个映射至多与Ln−1中的Ln−1个映射相连。同一个图中的神经元共享它们的权重,但具有不同的感受野。
子采样层
通过子采样层减少神经元的数量、需要计算的参数数量,有利于更快地进行训练。
最大池化层
最大池化层由矩形区域大小(Kx,Ky)参数化。最大池化层的输出由非重叠池化区域内最活跃的神经元生成。(保留矩阵的最大值)
全连接层
全连接分类层将最后一个特征提取层的输出组合成一维特征向量。最后通过softmax激活函数:
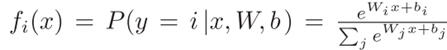
输入x和标签y最小化负对数似然损失:
 注意
注意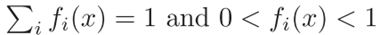
SVM
SVM是MLP的一个很好的替代品。具有不同核函数的SVM通过将原始数据投影到高维特征空间中,可以将非线性可分问题转化为线性可分问题[13]。软边缘SVM倾向于找到最佳分离超平面,其中数据集D = {(xi,yi)}可以通过解决以下原始问题来线性分离:
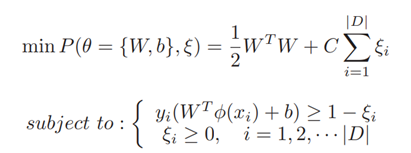
其中C和ξ表示惩罚参数和松弛变量。|D|是数据集的大小。
级联CNN模型
级联模型由11个不同的网络组成。离线手写数字识别系统的两级级联模型图如图所示:

STAGE I是由四个CNN-MLP网络和两个CNN-SVM网络组成的。这个阶段的目的是关注写得好的样本,具有较高的识别准确率,以保证整体性能。
STAGE II由三个CNN-MLP网络和两个CNN-SVM网络组成,主要关注少数写得差的样本,Discriminative Learning用于提高这一阶段识别较差书写样本的能力。
在每个阶段内考虑线性置信度累积,每个类别的组合概率p(wj| x)被计算为N个网络的预测概率p(wij |x):
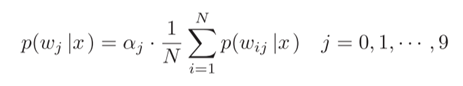
其中αj是通过所有网络计算出的加权参数。令vj(x)表示由N个网络识别后认为是第j类的概率,然后将结果归一化。
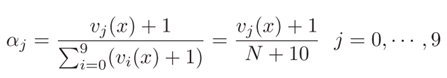
所有测试样本将被发送到第一阶段并获得识别置信度RC。如果RC高于阈值Th1,则系统将使用第一阶段的识别结果作为预测。否则,测试样本将被传递到第二阶段,并且系统的预测将是第二阶段的识别结果。级联CNN模型的最终决策导出如下:
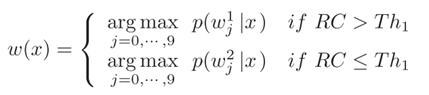
其中w1、w2表示第一阶段和第二阶段的候选结果。
实验过程
级联模型已在MNIST数据集上得到验证。MNIST包含70000个数字样本:50000个样本用于训练,10000个样本用于验证,10000个样本用于测试。训练每个单独的网络之前,应用三种类型的失真来扩展原始训练集。它们是旋转变形、弹性变形、剪切变形和局部剪切变形。基于先前的实验选择失真参数:
(1)σ和α:弹性变形的实值参数σ是高斯滤波器的标准偏差。α是控制失真幅度的缩放参数。设σ = 6.0,α =36.0。
(2)a和k:用于剪切和局部大小调整失真的随机值。a是尺寸调整范围,k是剪切斜率。
令a≤ 2且k≤ 0.04。
(3)β:范围在[−7.5◦, 7.5◦]中的随机角度,用于旋转失真。
(4)对于CNN-SVM模型,选择参数σ =2^−6和惩罚系数C = 32的RBF核。所有网络均使用Theano完成。所有的实验都是在同一台计算机上进行的,使用GPU来加速训练。
实验结果
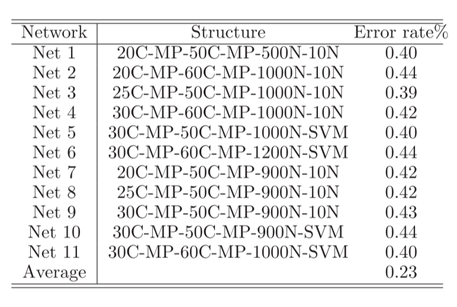
不同网络的结构在测试集上的错误率:
classification分类
输入x,需要输出其对应的种类y,常见任务有医疗诊断、手写文字识别、人脸识别等等。
实现分类的方法有生成模型和判别模型等。
Generative Model(生成模型)
在神奇宝贝的例子中,有79只水系,61只自然系,假设训练集服从高斯分布,使用极大似然法找出79只水系和61只自然系最符合的高斯分布(越接近中心点,x被选出的概率越高)。

Posterior probability后验概率
生成模型中需要计算后验概率,仍以二分类神奇宝贝为例:
P(c1|x)为测试集属于水系的概率。由下述可知,生成模型需要先求出均值向量μ和协方差矩阵Σ后,再计算出w和b的值,计算较为复杂。

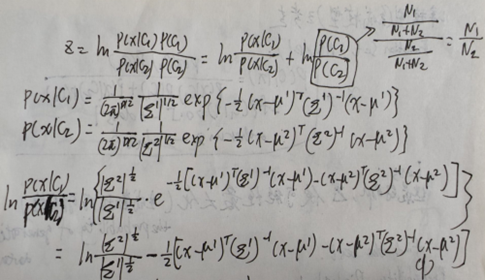
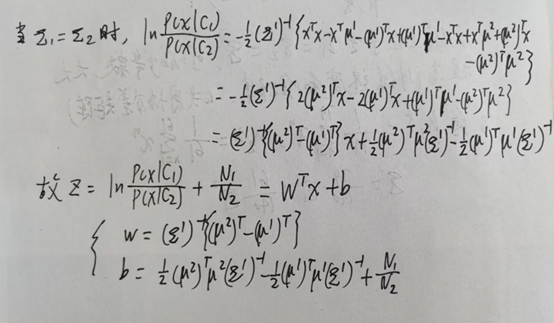
Discriminative Model(判别模型)
判别模型使用逻辑回归的方法直接找w和b的值,通常比生成模型更加准确,尤其在训练集很多的情形下。



总结
本周完成对CNN的基础学习,下周将开展有关RNN和LSTM的论文阅读以及相关学习。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









