



文章目录
摘要
本周对《An Attention-Based CNN-LSTM Method for Effluent Wastewater Quality Prediction》这篇关于污水处理的文章进一步阅读,并尝试使用代码复现。本文提出了一种基于注意力机制的CNN-LSTM混合模型(CLATT),用于预测污水处理厂(WWTP)出水水质,通过结合CNN、LSTM和注意力机制,成功提高了污水处理厂出水水质的预测精度和稳定性。
Abstract
This week, I will further read the article “An Attention Based CNN-LSTM Method for Ef fl uent Wastewater Quality Prediction” about wastewater treatment and attempt to reproduce it using code. This article proposes a CNN-LSTM hybrid model (CLATT) based on attention mechanism for predicting the effluent quality of wastewater treatment plants (WWTP). By combining CNN, LSTM, and attention mechanism, the prediction accuracy and stability of wastewater treatment plant effluent quality have been successfully improved.
文献
本文详细分析了使用基于注意力机制的CNN-LSTM(卷积神经网络-长短期记忆网络)混合模型(CLATT)进行污水处理厂出水水质预测的研究。该研究的背景、模型设计、实验结果、创新点和局限性,以及未来工作将通过详细的讨论展开。本分析将深入探讨该研究的各个方面,并结合污水处理的实际应用背景,提供全面的技术细节。
1. 研究背景与问题提出
污水处理是全球水资源管理的重要组成部分,随着水资源日益紧张以及环保要求的不断提高,污水处理技术的发展变得至关重要。污水处理的关键目标是通过物理、化学和生物方法去除污水中的污染物,从而将处理后的水质提升至环保标准以下。污水处理厂通常面临的主要挑战包括:
水质变化的复杂性:由于污水来源多样,成分复杂,水质指标如化学需氧量(COD)、氨氮(NH3-N)、总磷(TP)和总氮(TN)等指标在不同时间具有较大的波动性。
过程控制的滞后性:污水处理厂通常依靠后端控制方法,即通过传感器监控处理后的出水水质指标,并根据这些数据进行工艺调整。然而,由于数据处理和反应的滞后性,污水处理厂可能采取过度的控制措施,例如过量添加化学品或加大曝气量,以确保出水水质达标。这不仅浪费了大量的资源,还可能降低整体处理效率。
非线性和时间依赖性:污水处理过程是一个复杂的、非线性的、动态系统。随着时间推移,污水成分和处理工艺的变化会影响系统性能。传统的反应机制模型如活性污泥模型(ASM),虽然在实践中有所应用,但这些模型需要大量的参数,并且随着时间和工况的变化需要频繁更新,这使得控制难以适应实际生产中的快速变化。
为了应对这些挑战,近年来,基于数据驱动的神经网络模型引起了广泛关注。这类模型能够利用污水处理厂的大量历史数据,自动学习复杂的非线性关系,并通过预测未来的水质变化来优化处理过程。然而,现有的神经网络模型大多采用单一网络结构,如卷积神经网络(CNN)或长短期记忆网络(LSTM),这些模型虽然能够在一定程度上捕捉污水处理过程中的动态变化,但在处理复杂的时间序列数据、提取重要特征信息方面仍存在不足。
2. CLATT模型设计与创新
本文提出了一种基于CNN-LSTM-注意力机制的混合模型(CLATT),用于预测污水处理厂的出水水质。该模型结合了卷积神经网络、长短期记忆网络和注意力机制,通过多层次的特征提取和动态信息整合,有效解决了现有模型在处理复杂非线性和时间依赖关系中的不足。
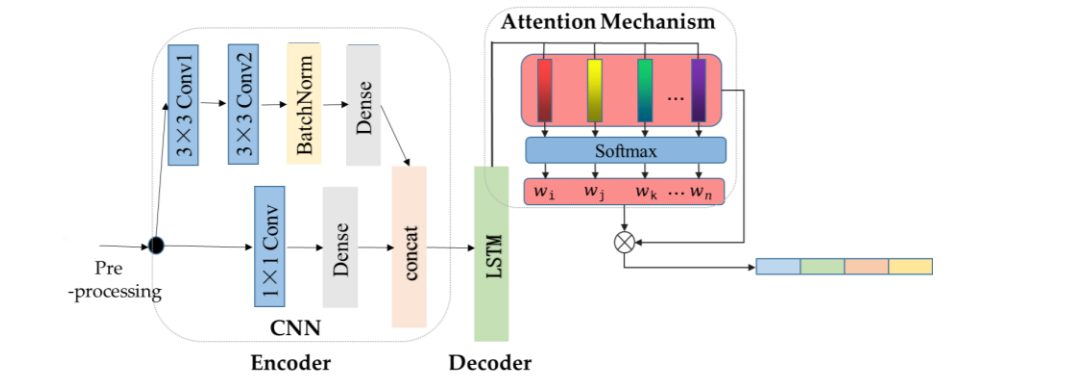
2.1 CNN编码器
卷积神经网络(CNN)是一类适用于处理多维数据的前馈神经网络,特别擅长从局部模式中提取特征。CNN在处理图像数据中应用广泛,因为它能够有效捕捉局部空间特征,如边缘、纹理等。在时间序列数据处理中,CNN也展现出其优势,它能够提取时间序列中不同时间段的变化趋势。
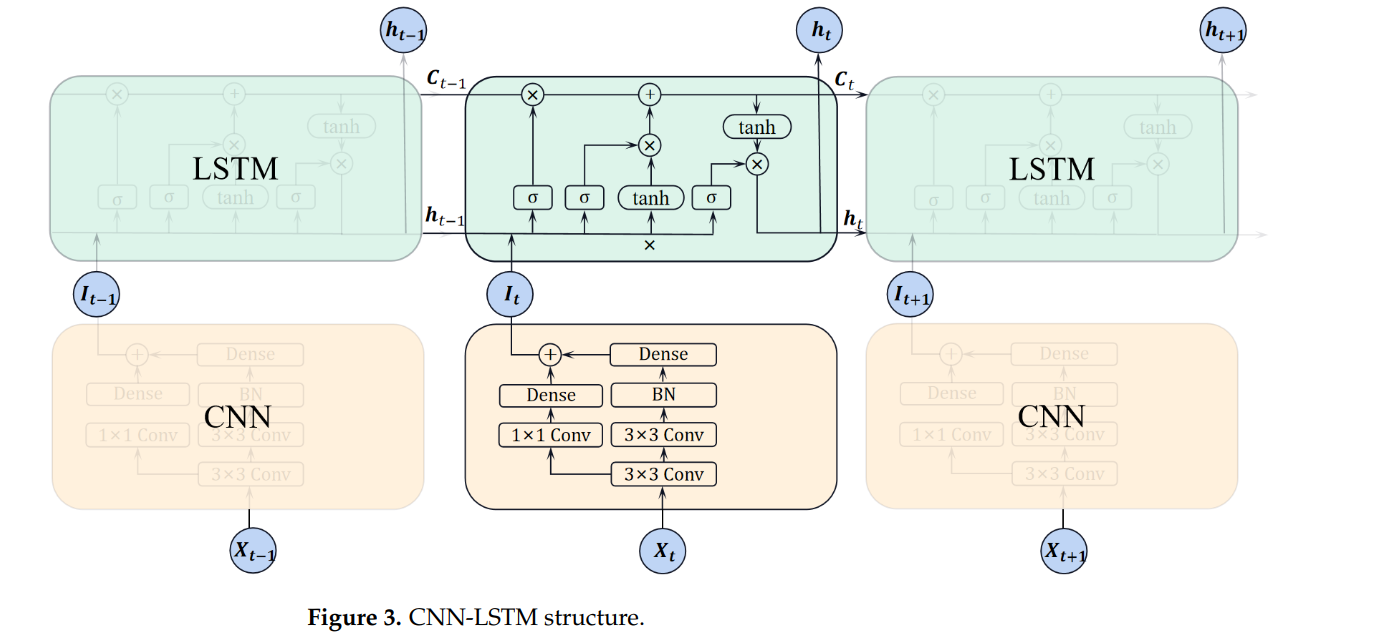
在CLATT模型中,CNN被用作编码器,用于提取污水处理过程中进水水质指标的局部特征。具体来说,CNN通过对输入的时间序列数据进行卷积操作,捕捉每个时间步长中的局部模式。卷积层中的卷积核通过滑动窗口对输入特征进行操作,提取出局部特征图。这些特征图能够反映不同水质指标在特定时间段内的变化模式。
此外,模型设计中加入了批归一化层(Batch Normalization),用于加速训练过程并防止梯度消失或爆炸现象。批归一化层通过对每一批数据进行归一化处理,使得数据在传递过程中保持数值稳定,从而提高了网络的收敛速度。
2.2 LSTM解码器
LSTM是一种改进的递归神经网络(RNN),它引入了“记忆单元”和“门控机制”,能够有效解决传统RNN在长时间依赖性问题上的不足。RNN的主要问题在于,随着时间步的增加,早期输入的信息会逐渐被遗忘,这在处理长时间依赖性较强的任务时表现尤为明显。
LSTM通过引入遗忘门、输入门和输出门,控制信息在网络中的流动,从而能够记住长期依赖关系。遗忘门决定了应该从记忆单元中丢弃哪些信息,输入门决定了当前时刻的信息应该被存储到记忆单元中,而输出门则控制了从记忆单元输出的信息。在污水处理预测中,LSTM用于解码CNN提取的特征,并对这些特征进行进一步的处理,以捕捉时间序列数据中的长期依赖性。
在CLATT模型中,LSTM通过处理多个时间步长的污水处理数据,能够有效建模污水成分的变化和处理工艺的动态响应。LSTM通过其门控机制在不同时间步之间选择性地保留或丢弃信息,从而提高了对复杂非线性关系的建模能力。
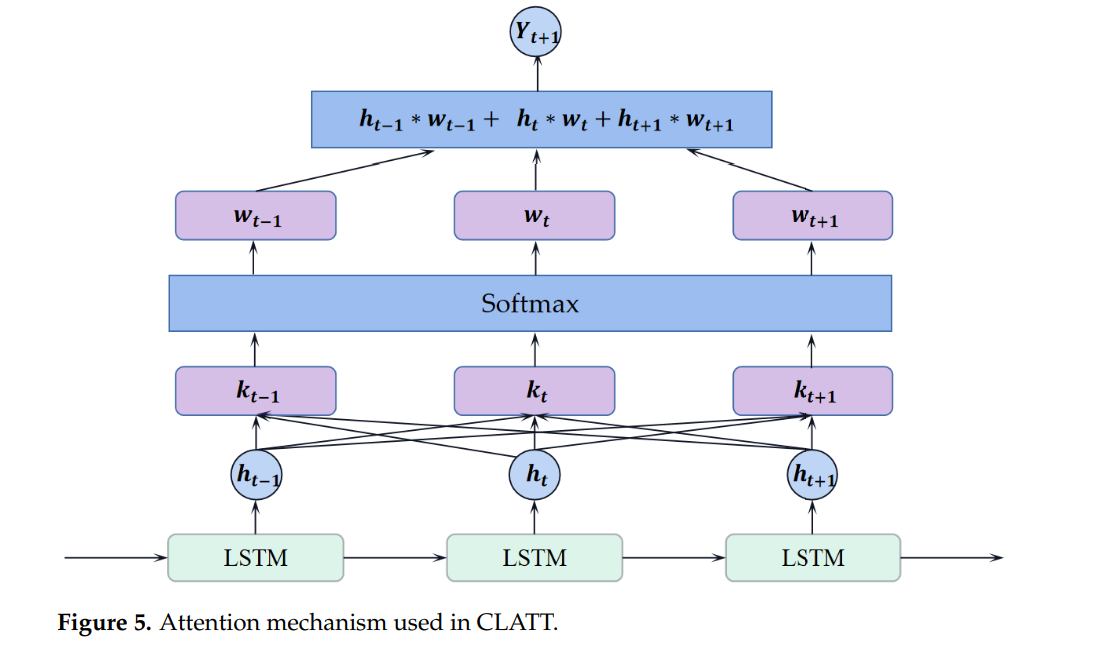
2.3 注意力机制
注意力机制的灵感来源于人类视觉系统的工作方式。当人类处理复杂的视觉信息时,大脑会自动聚焦于特定目标,而忽略无关的信息。在机器学习中,注意力机制用于增强神经网络的处理能力,帮助模型在处理复杂数据时自动选择重要特征,提升模型的精度和解释性。
在CLATT模型中,注意力机制用于整合LSTM在每个时间步产生的输出信息。由于污水处理过程是一个连续的动态系统,相邻时刻的污水成分和处理结果之间存在较强的相关性。注意力机制通过计算不同时间步之间的相关性,自动分配权重,重点关注对预测最有贡献的时刻,从而提高了模型的预测精度。
具体来说,CLATT中的注意力机制会计算LSTM在每个时间步输出的上下文向量与当前时刻输出的相关性,并为每个时间步分配一个权重。这些权重表示了不同时间步对最终预测结果的重要性,权重较高的时刻对模型的预测贡献更大。最终,模型根据这些权重对LSTM的输出进行加权求和,生成最终的预测结果。
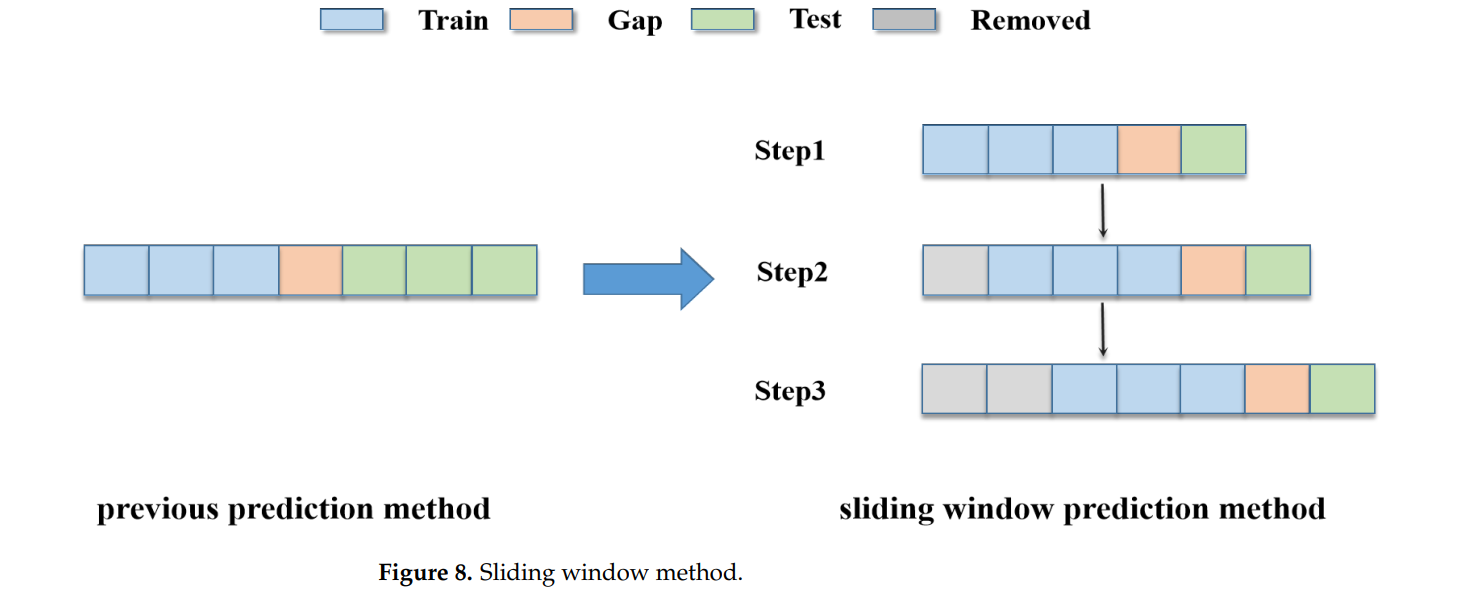
2.4 滑动窗口方法
在时间序列预测任务中,模型性能通常会随着时间的推移而下降,特别是在处理长期预测任务时。这是由于模型在长时间序列上学习到的特征可能不适用于未来的样本。为了应对这一问题,CLATT模型引入了滑动窗口方法。
滑动窗口方法将整个预测过程分解为多个短期预测任务,每个任务仅对相邻的一部分数据进行预测。具体来说,模型在每次训练时只处理固定窗口内的数据,而预测完成后,窗口会向前滑动,预测下一部分数据。这种方法通过动态更新模型参数,避免了模型在长时间序列上性能下降的问题。滑动窗口还起到了“数据增强”的作用,它将原始数据切分为多个部分,从而使模型能够更好地学习数据中的潜在模式。
3. 实验设计与结果分析
3.1 数据集
实验数据集来自中国福建省某污水处理厂,涵盖了2022年5月30日至2023年2月1日期间的2622个样本,采样频率为每两小时一次。数据集包含六个进水水质指标(COD、NH3-N、TP、TN、流量、pH)和四个出水水质指标(COD、NH3-N、TP、TN)。这些数据通过传感器采集,并进行了必要的预处理。

为了评估模型的性能,实验将数据集拆分为训练集、验证集和测试集,分别用于模型的训练、参数调整和性能评估。模型通过历史数据预测未来出水水质指标,实验使用的时间步长为6,也就是说,模型使用过去12小时的进水数据来预测接下来2小时的出水水质。
3.2 基线模型与评价指标
为了验证CLATT模型的有效性,本文使用了几种现有的神经网络模型作为基线模型,包括:
Reg-CNN:一种基于卷积神经网络的回归模型,用于处理多输出回归问题。
CNN-LSTM 混合模型:该模型结合了卷积神经网络和长短期记忆网络,用于捕捉时间序列数据的局部模式和长期依赖性。它在电力负荷预测等领域已经展现了其优越的性能。
SSAA-LSTM:这是基于长短期记忆网络(LSTM)和注意力机制的污水水质预测模型,与CLATT类似,使用了注意力机制来增强模型对时间序列数据中重要信息的聚焦能力。
为了量化模型的预测效果,实验中使用了三个常用的评价指标:
均方误差(MSE):评估模型预测值与真实值之间的差异,MSE值越小,模型的预测误差越小。
平均绝对百分比误差(MAPE):用于衡量预测误差的相对比例,MAPE越小,模型的预测精度越高。
极限误差率(LER):表示误差超过15%的样本占总样本的比例,LER越低,模型在不同工况下的稳定性越好。
3.3 实验结果与分析
实验结果表明,CLATT模型在多个水质指标的预测中都优于现有的基线模型,并且在滑动窗口方法的辅助下,其预测性能在长时间序列中保持了较高的稳定性。
3.3.1 与基线模型的对比
实验首先比较了CLATT模型与基线模型在测试集上的表现。结果表明,CLATT在预测COD、NH3-N、TP、TN四个出水水质指标时,均比其他模型表现更优。具体的评价指标如下:
Reg-CNN:作为一个仅依赖卷积神经网络的模型,Reg-CNN能够从时间序列中提取局部模式,但由于无法有效捕捉长期依赖性,它在所有指标上的表现均不及其他模型。
CNN-LSTM 混合模型:相比Reg-CNN,CNN-LSTM混合模型能够更好地处理时间依赖性,MSE、MAPE和LER值均有明显改善。然而,由于该模型未使用注意力机制,在处理复杂的时序特征时仍存在一定的局限性。
SSAA-LSTM:与CLATT类似,SSAA-LSTM模型结合了LSTM和注意力机制,能够有效捕捉污水处理过程中的时序特征。然而,CLATT通过加入CNN来增强非线性建模能力,从而在各项指标上进一步提升了预测精度。
CLATT的MSE值相比CNN-LSTM混合模型降低了2.69,MAPE降低了5%,LER降低了3%。这表明CLATT模型在污水处理的复杂动态系统中具有更好的非线性建模能力。
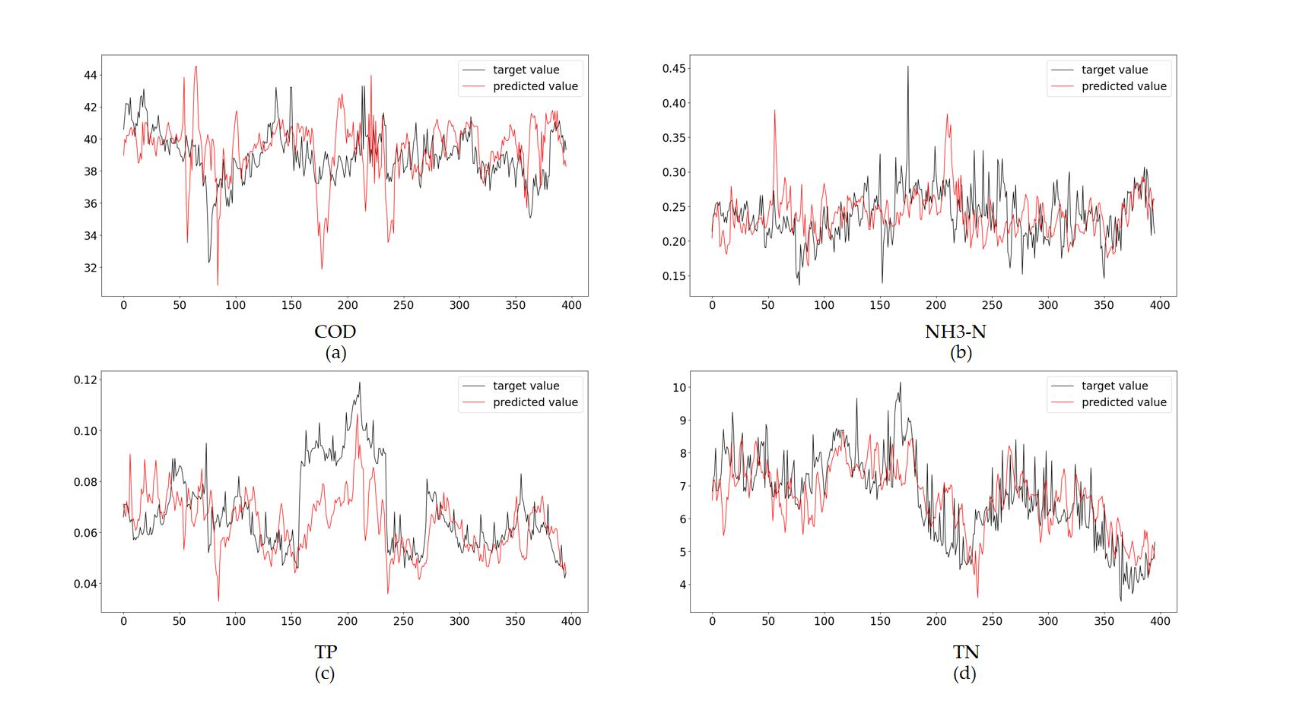
3.3.2 滑动窗口方法的效果
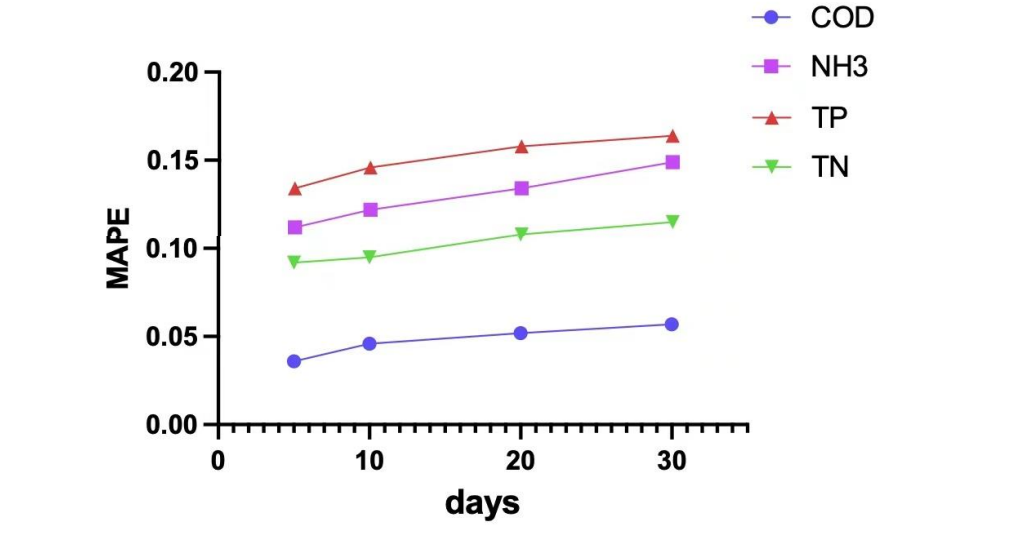
滑动窗口方法显著提高了模型的长期预测性能。实验中,研究者首先在未使用滑动窗口的情况下对模型进行了评估,结果发现,随着预测时间的延长,MSE和MAPE值逐渐升高。这是因为污水处理的水质条件会随着时间发生变化,模型在长时间序列上难以保持高精度预测。
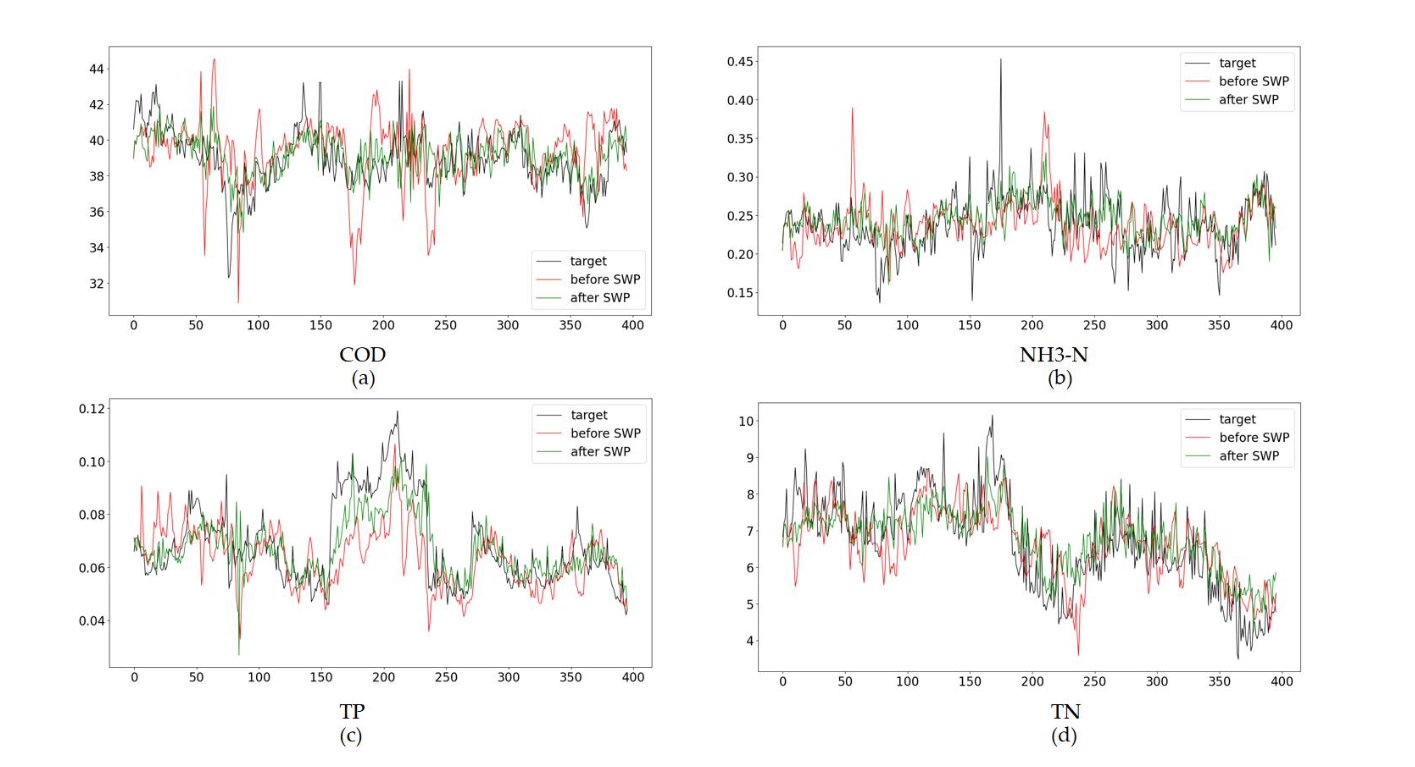
使用滑动窗口方法后,CLATT模型能够动态更新其参数,保持了较高的预测准确性和稳定性。滑动窗口方法不仅使模型在不同时间段内保持了低误差,还有效降低了LER值,表明模型在不同工况下的稳定性得到了显著提升。
实验结果表明,滑动窗口方法在处理长时间序列数据时非常有效。通过将预测任务分解为多个短期任务,模型避免了对长时间序列数据的过拟合,同时能够动态适应时间序列中的变化。滑动窗口的加入使得CLATT模型的MSE减少了0.25,MAPE降低了5%,LER减少了7%。
3.3.3 消融实验分析
为了验证模型中各个模块的贡献,研究者进行了消融实验。通过分别去除CNN、LSTM和注意力机制模块,分析它们对模型性能的影响。消融实验结果表明:
去除LSTM:去除LSTM后,模型的MSE和MAPE值显著升高,表明时间依赖性对污水处理过程的预测至关重要。LSTM能够有效建模时间序列中的长期依赖性,因此在预测污水处理过程中的动态变化时起到了关键作用。
去除CNN:去除CNN后,模型的特征提取能力有所下降。CNN能够捕捉进水水质的局部特征,并为LSTM提供高质量的输入。没有CNN的帮助,模型难以从复杂的非线性数据中提取关键特征,导致预测性能下降。
去除注意力机制:去除注意力机制后,模型的MSE和MAPE值有所升高,但相比去除LSTM的影响要小一些。注意力机制能够增强模型对相邻时间步之间相关性的处理能力,提升了模型对关键时间点的聚焦能力。因此,虽然去除注意力机制并未完全破坏模型的时序处理能力,但预测精度显著下降。
实验还分析了CNN模块中的残差块和批归一化层(BN层)的作用。结果显示,残差块的移除对模型性能的影响最大。残差块确保了网络在传递深层信息时不会丢失重要特征,并有效防止了梯度消失问题。BN层的移除也使得模型的预测性能略有下降,表明BN层在加速模型收敛、平衡特征贡献方面发挥了重要作用。
4. 结论与未来工作
本文提出的CLATT模型通过结合CNN、LSTM和注意力机制,成功实现了污水处理厂出水水质的高效预测。实验结果表明,CLATT模型在多个水质指标的预测中表现出色,尤其在滑动窗口方法的帮助下,能够保持较高的预测精度和稳定性。
4.1 研究贡献
创新的模型架构:CLATT模型结合了CNN的局部特征提取能力、LSTM的时序依赖性处理能力和注意力机制的特征聚焦能力,为污水处理预测任务提供了强有力的工具。实验结果显示,CLATT模型在处理复杂非线性动态系统时具有显著的优势。
滑动窗口方法的应用:滑动窗口方法不仅提升了模型的长期预测能力,还增强了模型对数据变化的适应性。该方法可以推广到其他时间序列预测任务中,具有较大的应用潜力。
消融实验验证模型合理性:通过消融实验,研究者验证了CNN、LSTM和注意力机制在模型中的重要性,进一步证明了CLATT的合理设计。
4.2 研究局限性与未来工作
尽管CLATT模型在污水处理预测任务中表现出色,但仍然存在一些局限性和改进空间:
模型的泛化能力:目前的CLATT模型主要应用于市政污水处理厂的数据集。然而,不同类型的污水(如工业污水、化工污水)的水质特征差异较大,CLATT模型在不同数据集上的泛化能力需要进一步验证。未来工作可以尝试构建更具泛化能力的模型,适应不同来源的污水处理数据。
操作工艺参数的集成:当前的模型仅基于进水水质指标进行预测,未考虑污水处理厂中的具体操作工艺(如化学品投加量、曝气能力等)。未来可以将这些操作工艺参数纳入模型输入,以提高模型对实际工况的适应能力,并为操作优化提供参考。
实时性与计算效率:虽然CLATT模型能够有效预测出水水质,但在实际应用中,污水处理厂需要实时处理大量数据,因此模型的计算效率和实时性仍是一个值得研究的问题。未来工作可以尝试进一步优化模型结构,提升其在实时预测任务中的表现。
深度学习
使用PyTorch实现CNN-LSTM-注意力机制(CLATT)模型
以下是使用PyTorch实现CNN-LSTM-注意力机制(CLATT)模型的完整代码示例。该代码包括了数据生成、模型构建、训练和测试的基本步骤。为了演示模型,这里提供了一个随机生成的模拟污水处理数据集。
- 数据集生成
首先我们生成一个模拟的污水处理数据集,其中包括进水和出水的水质指标。每个样本包含6个进水特征和4个出水目标。
import numpy as np
import torch
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 生成模拟数据集
np.random.seed(42)
n_samples = 3000
n_in_features = 6
n_out_features = 4
# 随机生成进水和出水水质指标
X = np.random.rand(n_samples, n_in_features) * 100 # 进水特征数据
y = np.random.rand(n_samples, n_out_features) * 10 # 出水目标数据
# 数据标准化
scaler_in = StandardScaler()
scaler_out = StandardScaler()
X_scaled = scaler_in.fit_transform(X)
y_scaled = scaler_out.fit_transform(y)
# 滑动窗口方法
def create_sequences(X, y, time_steps=6):
Xs, ys = [], []
for i in range(len(X) - time_steps):
Xs.append(X[i:i+time_steps])
ys.append(y[i+time_steps])
return np.array(Xs), np.array(ys)
time_steps = 6
X_seq, y_seq = create_sequences(X_scaled, y_scaled, time_steps)
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_seq, y_seq, test_size=0.2, random_state=42)
# 转换为PyTorch张量
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32)
# 数据集的大小
print(X_train.shape, y_train.shape)
- 模型构建
接下来,我们用PyTorch构建CNN-LSTM-注意力机制模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义注意力机制层
class AttentionLayer(nn.Module):
def __init__(self, input_dim):
super(AttentionLayer, self).__init__()
self.attn_weights = nn.Linear(input_dim, input_dim)
def forward(self, inputs):
scores = torch.tanh(self.attn_weights(inputs))
attn_weights = torch.softmax(scores, dim=1)
context_vector = torch.sum(attn_weights * inputs, dim=1)
return context_vector
# 构建CNN-LSTM-注意力机制模型
class CLATT(nn.Module):
def __init__(self, time_steps, in_features, hidden_dim=128, out_features=4):
super(CLATT, self).__init__()
# CNN编码器
self.conv1 = nn.Conv1d(in_features, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(64, 64, kernel_size=3, padding=1)
self.batch_norm = nn.BatchNorm1d(64)
self.flatten = nn.Flatten()
# LSTM解码器
self.lstm = nn.LSTM(64 * time_steps, hidden_dim, batch_first=True)
# 注意力机制
self.attention = AttentionLayer(hidden_dim)
# 输出层
self.fc = nn.Linear(hidden_dim, out_features)
def forward(self, x):
# CNN部分
x = x.transpose(1, 2) # 调整输入形状,适配1D卷积
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = self.batch_norm(x)
x = self.flatten(x)
x = x.unsqueeze(1) # 扩展为LSTM输入
# LSTM部分
lstm_out, (h_n, c_n) = self.lstm(x)
# 注意力机制
attention_out = self.attention(lstm_out)
# 输出层
out = self.fc(attention_out)
return out
# 创建模型
model = CLATT(time_steps, n_in_features)
print(model)
- 训练模型
定义训练和测试循环并训练模型。
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
def train_model(model, X_train, y_train, n_epochs=50, batch_size=64):
model.train()
for epoch in range(n_epochs):
for i in range(0, len(X_train), batch_size):
X_batch = X_train[i:i+batch_size]
y_batch = y_train[i:i+batch_size]
# 前向传播
y_pred = model(X_batch)
loss = criterion(y_pred, y_batch)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch+1}/{n_epochs}, Loss: {loss.item():.4f}')
train_model(model, X_train, y_train)
- 测试模型
在测试集上评估模型的性能。
# 测试模型
def evaluate_model(model, X_test, y_test):
model.eval()
with torch.no_grad():
y_pred = model(X_test)
loss = criterion(y_pred, y_test)
print(f'Test Loss: {loss.item():.4f}')
return y_pred
y_pred = evaluate_model(model, X_test, y_test)
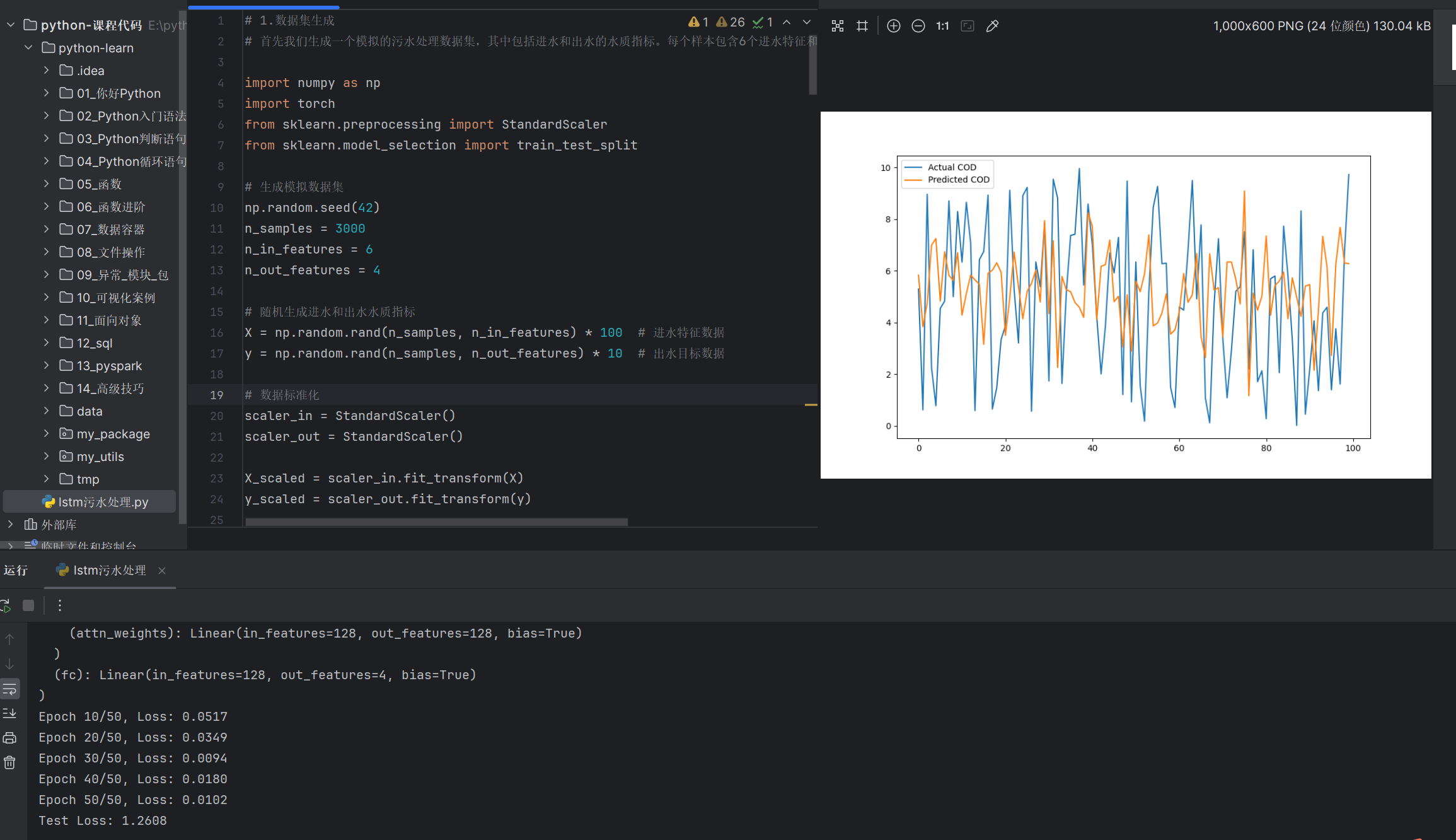
- 结果可视化
可以将模型预测结果与实际值进行可视化比较。
import matplotlib.pyplot as plt
# 反标准化
y_test_inv = scaler_out.inverse_transform(y_test.numpy())
y_pred_inv = scaler_out.inverse_transform(y_pred.numpy())
# 绘制预测结果
plt.figure(figsize=(10, 6))
plt.plot(y_test_inv[:100, 0], label='Actual COD')
plt.plot(y_pred_inv[:100, 0], label='Predicted COD')
plt.legend()
plt.show()
通过此PyTorch实现,我们构建了一个CNN-LSTM-注意力机制的混合模型来预测污水处理厂的出水水质。模型使用了卷积神经网络提取局部特征,LSTM处理时间序列依赖,最后通过注意力机制整合相邻时间点的信息。
预测结果如下:
总结
总的来说,本文提出的CLATT模型为污水处理厂的智能化控制提供了有效的解决方案。通过结合先进的深度学习技术,研究者成功提高了污水处理的效率和精度,未来可以进一步拓展该模型的应用范围,推动污水处理行业的智能化发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









