







Zookeeper简介
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等等。
Zookeeper基本概念
zk角色
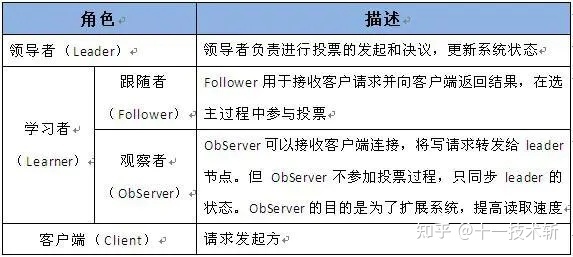
Zookeeper中的角色主要有以下三类,如下表所示:zookeeper角色
zk service网络结构
Zookeeper的工作集群可以简单分成两类,一个是Leader,唯一一个,其余的都是follower,如何确定Leader是通过内部选举确定的。

Leader和各个follower是互相通信的,对于zk系统的数据都是保存在内存里面的,同样也会备份一份在磁盘上。
对于每个zk节点而言,可以看做每个zk节点的命名空间是一样的,也就是有同样的数据。(可查看下面的树结构)
如果Leader挂了,zk集群会重新选举,在毫秒级别就会重新选举出一个Leaer。
集群中除非有一半以上的zk节点挂了,zk service才不可用。
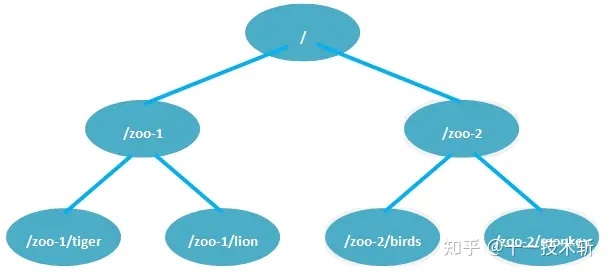
zk命名空间结构
Zookeeper的命名空间就是zk应用的文件系统,它和linux的文件系统很像,也是树状,这样就可以确定每个路径都是唯一的,对于命名空间的操作必须都是绝对路径操作。与linux文件系统不同的是,linux文件系统有目录和文件的区别,而zk统一叫做znode,一个znode节点可以包含子znode,同时也可以包含数据。
提示:
比如/Nginx/conf,/是一个znode,/Nginx是/的子znode,/Nginx还可以包含数据,数据内容就是所有安装Nginx的机器IP,/Nginx/conf是/Nginx子znode,它也可以包含内容,数据就是Nginx的配置文件内容。在应用中,我们可以通过这样一个路径就可以获得所有安装Nginx的机器IP列表,还可以获得这些机器上Nginx的配置文件。
zk读写数据
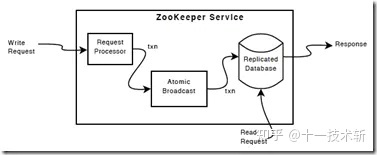
写数据,但一个客户端进行写数据请求时,会指定zk集群中节点,如果是follower接收到写请求,就会把请求转发给Leader,Leader通过内部的Zab协议进行原子广播,直到所有zk节点都成功写了数据后(内存同步以及磁盘更新),这次写请求算是完成,然后zk service就会给client发回响应
读数据,因为集群中所有的zk节点都呈现一个同样的命名空间视图(就是结构数据),上面的写请求已经保证了写一次数据必须保证集群所有的zk节点都是同步命名空间的,所以读的时候可以在任意一台zk节点上
ps:其实写数据的时候不是要保证所有zk节点都写完才响应,而是保证一半以上的节点写完了就把这次变更更新到内存,并且当做最新命名空间的应用。所以在读数据的时候可能会读到不是最新的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8438
8438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









