






未分区的表,只能存储在一个FileGroup中;对table进行分区后,每一个分区都存储在一个FileGroup中。表分区是将逻辑上一个完整的表,按照特定的字段拆分成Partition set,分散到(相同或不同的)FileGroup中,每一个Partition在FileGroup中都独立存储,每一个parititon都属于唯一的表对象,每一个Partition 都有唯一的ID。
在创建表时,使用On 子句指定table存储的逻辑位置:
On filegroup | "default" 表示逻辑存储位置是单一的FileGroup;
ON partition_scheme_name ( partition_column_name ) 表示逻辑存储位置是多个FileGroup,按照partition_column_name将table拆分成多个partition,每一个partition都存储在一个指定的Filegroup中。
CREATE TABLE [schema_name . ] table_name ( <column_definition> ) [ ON { partition_scheme_name ( partition_column_name ) | filegroup | "default" } ] [ WITH ( <table_option> [ ,...n ] ) ] [ ; ]
Partition的含义就是table的一部分逻辑存储空间。
跟逻辑存储空间相对应的是物理存储空间,物理存储空间是由File指定的,FileGroup是File的集合,每一个File都属于唯一的FileGroup。将table的存储空间拆分到不同的FileGroup中,逻辑上是将table的存储管理体系增加了一层 Partition,介于Table和FileGroup中间,Table的数据存储在Partition,Partition存储在FileGroup中,FileGroup管理着File,File是实际存储data的物理文件。
table为什么要增加Parition?因为FileGroup是所有的Table共享,Partition是由一个table独占,每一个Partition都唯一属于一个table。这样,对某个parititon进行操作,而不影响table的其他parition,也不会影响其他table。
一:创建分区表的步骤
Step1, 创建分区函数
分区函数的作用是提供分区字段的类型和分区的边界值
CREATE PARTITION FUNCTION [pf_int](int) AS RANGE LEFT FOR VALUES (10, 20)
pf_int 的含义是按照int类型分区,分区的边界值是10,20,left表示边界值属于左边界。两个边界值能够分成三个分区,别是(-infinite,10],(10,20],(20,+infinite)。
Step2,创建分区scheme
分区scheme的作用是为Parition分配FileGroup,Partition Scheme和FileGroup在逻辑上等价,都是数据存储的逻辑空间,只不过Partition Scheme指定的是多个FileGroup。
CREATE PARTITION SCHEME [ps_int] AS PARTITION [pf_int] TO ([PRIMARY], [db_fg1], [db_fg1])
不管是在不同的FileGroup中,还是在相同的FileGroup中,分区都是独立存储的。
Step3,创建分区表
创建分区表,实际上是使用on子句指定table存储的逻辑位置。

create table dbo.dt_test ( ID int, code int ) on [ps_int] (id)
二,查看Partition的Metadata
1, 查看partition function
select * from sys.partition_functions

查看partition function定义的边界值
select * from sys.partition_range_values
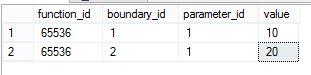
查看partition function 定义的parmeter,这个Parmeter是一个data type,system_type_id标识该data type。
select * from sys.partition_parameters

根据system_type_id查看data type
select * from sys.types where system_type_id=56
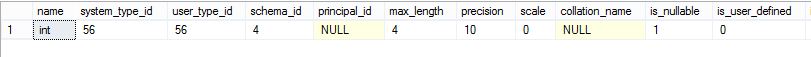
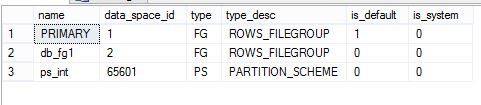
2, 查看Partition scheme和 filegroup
select * from sys.partition_schemes

data_space_ID 是数据空间ID,每一个Parition Scheme都有一个ID。
select * from sys.filegroups

data_space_ID 是数据空间ID,每一个FileGroup都有一个ID。
3, 查看Data Space
select * from sys.data_spaces
Each filegroup has one row, and each partition scheme has one row. If the row refers to a partition scheme, data_space_id can be joined with sys.partition_schemes.data_space_id. If the row referes to a file, data_space_id can be joined with sys.filegroups.data_space_id.
sys.data_spaces 是sys.filegroups 和 sys.partition_schemes 结果的交集,充分说明,partition scheme和filegroup都是数据存储的逻辑空间。
4,partition scheme和filegroup 之间的关系
一个partition scheme能够使用多个filegroup存储数据,同时一个filegroup可以被多个partition scheme使用,partition scheme和filegroup 之间的关系是many-to-many,sql server使用 sys.destination_data_spaces 提供partition scheme和filegroup 之间的关系。
select * from sys.destination_data_spaces
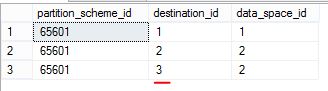
partition_scheme_id 是 sys.partition_schemes的data_space_id,标识一个Partition Scheme。
data_space_id 是 sys.filegroups的data_space_id,标识partition scheme使用的filegroup。
destination_id 是 Partition number。Partition Number是一个数字,从1开始,标识table的parition的编号。表的partition number从左向右开始编号,最左边的分区,其partition number 是1。
5,查看分区的信息
select * from sys.partitions where object_id=object_id('dbo.dt_test')

partition_id:每一个partition都有一个ID,唯一标识该分区。
rows:分区包含的数据行数目
data_compression和data_compression_desc:partition 使用的数据压缩类型
6,查看分区的统计信息
select * from sys.dm_db_partition_stats where object_id=object_id('dbo.dt_test')


| used_page_count | bigint | Total number of pages used for the partition. Computed as in_row_used_page_count + lob_used_page_count +row_overflow_used_page_count. |
| reserved_page_count | bigint | Total number of pages reserved for the partition. Computed as in_row_reserved_page_count + lob_reserved_page_count +row_overflow_reserved_page_count. |
| row_count | bigint | The approximate number of rows in the partition. |
sys.dm_db_partition_stats displays information about the space used to store and manage in-row data, LOB data, and row-overflow data for all partitions in a database. One row is displayed per partition.
The counts on which the output is based are cached in memory or stored on disk in various system tables.
In-row data, LOB data, and row-overflow data represent the three allocation units that make up a partition. The sys.allocation_units catalog view can be queried for metadata about each allocation unit in the database.
If a heap or index is not partitioned, it is made up of one partition (with partition number = 1); therefore, only one row is returned for that heap or index. Thesys.partitions catalog view can be queried for metadata about each partition of all the tables and indexes in a database.
The total count for an individual table or an index can be obtained by adding the counts for all relevant partitions.














 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









