







Deep MNIST for Experts解读(一)
https://www.tensorflow.org/get_started/mnist/pros
Tensorflow依赖于后端的高度优化的C++库,为了与C++库交互,需要session。
所以,Tensorflow的编程模式是先创建一个计算图,再交接session去计算。
这与平常的编程模式不太一样,尤其在调试时感受比较明显。比如查一个变量的运行时的值,一般跑起来后可以直接查看,但在Tensorflow中,必须要等到session.run()才能看到。
Session与InteractiveSession的区别是什么?
答:Session是Tensorflow的标准方式,把一个计算图搞完后,整体提交session,完成计算。在这种情况下,建构OP对象时是没有session的,所以在后面必须显示的使用session.run()。但InteractiveSession不同,它出现后,OP对象在构建时,就会把它做为缺省session安装上去,所以自带session,可以直接调用运算函数完成计算(Tensor.eval() 和 Operation.run() )。这种好处是,可以随时构建计算节点,然后随时计算结果,不用时刻去想session的事情,故名交互式Session。参见:http://blog.csdn.net/zcf1784266476/article/details/70272905
代码:
import tensorflow as tf
sess = tf.InteractiveSession()
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
# 注意下面这一行,这里使用了c.eval(),如果使用session,可能会是:sess=tf.Session() print(sess.run(c))
# 而且,InteractiveSession在用完后需要显式关闭
print(c.eval())
sess.close()
Tensorflow为什么要使用图计算模式?
Numpy是Tensorflow的好帮手,尤其擅长矩陈运算。但在普通的python环境与numpy(真正的重活是C++环境在干)之间转换,特别是在GPU或分布式下,切换成本还是比较高的。所以频繁在python与C++之间切换导致了低效。使用python去描述计算图,然后一次性提交sesion,然后一次性提交session,交由C++去完成计算,性能好很多。
Deep MNIST for Experts的前半部分仍然在解释mnist_softmax.py,参见之前两篇的博客:
http://blog.csdn.net/vagrantabc2017/article/details/77063792
http://blog.csdn.net/vagrantabc2017/article/details/77101799
这里进一步复习一下。
x = tf.placeholder(tf.float32, shape=[None, 784])
#x = tf.placeholder(tf.float32, shape=[每批次多少张图片, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
#y_ = tf.placeholder(tf.float32, [每批次多少张图片, 10])
W为什么会是784*10?
答:因为是输入是一个图,有784个点(features),并且有10个输出(0到9).所以W的是shape[features数量,输出数量]。
y = tf.matmul(x, w) + b
矩阵相乘后得到shape[每批次多少张图片,10],再加b.
举个例子,假设2张图片,b的
xW=tf.constant([[0,1,2,3,4,5,6,7,8,9],
[9,8,7,6,5,4,3,2,1,0]])
b=tf.constant([0,0,1,0,0,0,0,0,0,0])
res = xW + b
输出:
[[0 1 3 3 4 5 6 7 8 9]
[9 8 8 6 5 4 3 2 1 0]]
可见,加b就是在xW乘积的每行都重叠一个b的行向量。
激活函数:softmax,输出属于某一类的概率
损失函数:交叉熵函数,softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵.
优化器用于计算损失函数的坡度并将坡度应用于变量。Tensorflow提供以下优化器:
tf.train.Optimizer
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer
现在只了熟悉GradientDescentOptimizer,其它以后再说。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
内部处理(看上去还是比较抽象):
1. 计算坡度
2. 计算参数更新步数
3. 对参数应用更新步数
打印出y看看,在mnist_softmax.py的for _ in range(1000):复合语句之后(外面)插入一句:
print(sess.run(y, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
得到:
[[ 0.43599528 -8.72492504 1.67129803 ..., 10.67329407 -0.38615787 2.09889698]
[ 4.16476679 -1.62994194 10.84041023 ..., -13.57742596 4.29881573 -8.53488922]
[ -5.26533985 6.19166565 1.90310097 ..., 0.46886426 1.02612364 -1.4779768 ]
...,
[ -7.61233521 -6.62633181 -2.11581898 ..., 2.29557776 3.58375025 3.92177582]
[ -2.38366461 -1.31900096 -1.06822062 ..., -3.82995367 5.05690718 -3.35313249]
[ 3.45034647 -9.92010784 6.14171076 ..., -6.9410162 0.33765018 -4.41856956]]
因为y的shape是shape[每批次多少张图片,10],所以每行有10个数。
让我们构造个例子。
y=tf.constant([[-2,6,9,3,2,4,-8,1,5,-1], #每行找出最大数的坐标。
[4,5,6,-1,-2,8,10,1,3,4],
[1,2,3,4,55,-9,7,2,-3,-1]])
y_=tf.constant([[0,0,1,0,0,0,0,0,0,0], #每行找出最大数的坐标。
[0,0,0,0,0,0,0,0,1,0],
[0,0,0,0,1,0,0,0,0,0]])
correct = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) #两个坐标的位置是否一样
print(sess.run(correct))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
print(sess.run(accuracy))
输出:[ True False True]
0.666667
可见,以上我们人为构造的例子,正确预测率为三分之二,第二条没预测对。
通过上面2篇半博客,mnist_softmax.py就介绍完了,如果再不懂,撞墙。。。:)
最后解释两个概念:
1. 什么是logits?
答:从源码logits=y可以看出,logits不就是模型xW+b嘛。
2. 什么是 one-hot ?
答:只有一个热点,形如[0,0,1,0,0,0]的只有一个1,其它都是0的形式就是one-hot.
下面接着说多层卷积网。
据说识别率可以达到99.2%,而上个softmax模型不管咋搞只有92%,十个字里面错一个,想想还是头痛。
下面学习源码样例mnist_deep.py。
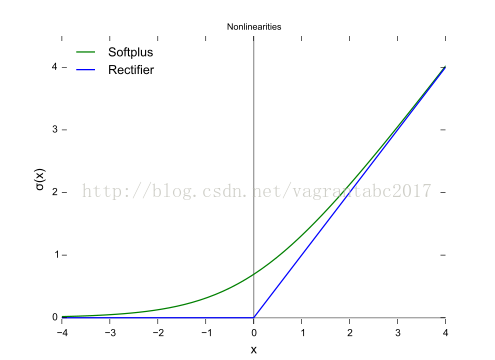
什么是修改线性单元ReLU?
先得说说修正器。修正器是激活函数的一种。我们学了softmax激活函数 ,大概了解sigmoid激活函数,修改器也是激活函数的一种。
修改器的定义;f(x)=x+=max(0,x)
参见:https://en.wikipedia.org/wiki/Rectifier_(neural_networks)
据说比sigmoid要好使,在DNN中最流行。
这个说完了,ReLU就好解释了,不就是使用修正器作激活函数的神经单元嘛。
这个函数比较硬,也就是说,在负值段是0,在原点突然就向上拔高,线条不柔和。所以又有了softplus。
softplus定义:f(x)=ln[1+exp(x)]
它的导数正好是Logistic函数: 1/[1+exp(-x)]
第一个简单函数:weight_variable:这里涉及一个函数initial = tf.truncated_normal(shape, stddev=0.1)。这个函数生成一个正态分布的tensor对象。
练习:
#生成一个10元素的向量,元素值随机,要求均值为0,标准差为1。
x = tf.truncated_normal([10])
输出:
[ 0.34689453 -0.80089593 -1.72287786 -0.41869378 0.77246767 -1.75758398 -0.53423828 0.00332778 0.85409206 -1.41753328]
#要求同上,但标准差(standard deviation,即stddev)为0.1.
x = tf.truncated_normal([10],stddev=0.1)
输出:
[ 0.18521971 0.10536867 -0.11113615 0.10921837 -0.1070381 0.14818405 0.07154682 -0.10790845 0.17011671 -0.0928892 ]
第二个简单函数:bias_variable,bias初值全部为0.1,没啥说的。
x = tf.constant(0.1, shape=[5])
输出:[ 0.1 0.1 0.1 0.1 0.1]
剩下两个函数其实内容挺多的,看完deepnn后再说。
conv2d:只有一句:tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME'),完成卷积运算。
x: input输入。
W:一个四维的tensor,[filter_height, filter_width, in_channels, out_channels]
strides=[1, 1, 1, 1]:
padding: 两种取值方式 "SAME", "VALID". VAlID就是顺着砍甘蔗,到最左或最后,不够一整节的就扔了。SAME是不够就前后补0,先简单这样理解着。
max_pool_2x2:也只有一句:tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
这两句是卷积神经网络模型的关键所在,先留第一个遗留问题。
deepnn中,分了几层:
1.第一卷积层
2.第二卷积层
3.全联接层
4.dropout层
5.输出层
每层的含义,留下第二个遗留问题。
main函数
注意的是,计算图采用了deepnn模型。
之后softmax,交叉熵与前面一样,没什么可说的。
优化器采用了AdamOptimizer,不再是坡度优化,算第三个遗留问题。
其它代码,如果前面的懂了,这里并不困难。
所以,在后面的内容中,我们主要看这三个遗留问题。(待续)
https://www.tensorflow.org/get_started/mnist/pros
Tensorflow依赖于后端的高度优化的C++库,为了与C++库交互,需要session。
所以,Tensorflow的编程模式是先创建一个计算图,再交接session去计算。
这与平常的编程模式不太一样,尤其在调试时感受比较明显。比如查一个变量的运行时的值,一般跑起来后可以直接查看,但在Tensorflow中,必须要等到session.run()才能看到。
Session与InteractiveSession的区别是什么?
答:Session是Tensorflow的标准方式,把一个计算图搞完后,整体提交session,完成计算。在这种情况下,建构OP对象时是没有session的,所以在后面必须显示的使用session.run()。但InteractiveSession不同,它出现后,OP对象在构建时,就会把它做为缺省session安装上去,所以自带session,可以直接调用运算函数完成计算(Tensor.eval() 和 Operation.run() )。这种好处是,可以随时构建计算节点,然后随时计算结果,不用时刻去想session的事情,故名交互式Session。参见:http://blog.csdn.net/zcf1784266476/article/details/70272905
代码:
import tensorflow as tf
sess = tf.InteractiveSession()
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
# 注意下面这一行,这里使用了c.eval(),如果使用session,可能会是:sess=tf.Session() print(sess.run(c))
# 而且,InteractiveSession在用完后需要显式关闭
print(c.eval())
sess.close()
Tensorflow为什么要使用图计算模式?
Numpy是Tensorflow的好帮手,尤其擅长矩陈运算。但在普通的python环境与numpy(真正的重活是C++环境在干)之间转换,特别是在GPU或分布式下,切换成本还是比较高的。所以频繁在python与C++之间切换导致了低效。使用python去描述计算图,然后一次性提交sesion,然后一次性提交session,交由C++去完成计算,性能好很多。
Deep MNIST for Experts的前半部分仍然在解释mnist_softmax.py,参见之前两篇的博客:
http://blog.csdn.net/vagrantabc2017/article/details/77063792
http://blog.csdn.net/vagrantabc2017/article/details/77101799
这里进一步复习一下。
x = tf.placeholder(tf.float32, shape=[None, 784])
#x = tf.placeholder(tf.float32, shape=[每批次多少张图片, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
#y_ = tf.placeholder(tf.float32, [每批次多少张图片, 10])
W为什么会是784*10?
答:因为是输入是一个图,有784个点(features),并且有10个输出(0到9).所以W的是shape[features数量,输出数量]。
y = tf.matmul(x, w) + b
矩阵相乘后得到shape[每批次多少张图片,10],再加b.
举个例子,假设2张图片,b的
xW=tf.constant([[0,1,2,3,4,5,6,7,8,9],
[9,8,7,6,5,4,3,2,1,0]])
b=tf.constant([0,0,1,0,0,0,0,0,0,0])
res = xW + b
输出:
[[0 1 3 3 4 5 6 7 8 9]
[9 8 8 6 5 4 3 2 1 0]]
可见,加b就是在xW乘积的每行都重叠一个b的行向量。
激活函数:softmax,输出属于某一类的概率
损失函数:交叉熵函数,softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵.
优化器用于计算损失函数的坡度并将坡度应用于变量。Tensorflow提供以下优化器:
tf.train.Optimizer
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer
现在只了熟悉GradientDescentOptimizer,其它以后再说。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
内部处理(看上去还是比较抽象):
1. 计算坡度
2. 计算参数更新步数
3. 对参数应用更新步数
打印出y看看,在mnist_softmax.py的for _ in range(1000):复合语句之后(外面)插入一句:
print(sess.run(y, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
得到:
[[ 0.43599528 -8.72492504 1.67129803 ..., 10.67329407 -0.38615787 2.09889698]
[ 4.16476679 -1.62994194 10.84041023 ..., -13.57742596 4.29881573 -8.53488922]
[ -5.26533985 6.19166565 1.90310097 ..., 0.46886426 1.02612364 -1.4779768 ]
...,
[ -7.61233521 -6.62633181 -2.11581898 ..., 2.29557776 3.58375025 3.92177582]
[ -2.38366461 -1.31900096 -1.06822062 ..., -3.82995367 5.05690718 -3.35313249]
[ 3.45034647 -9.92010784 6.14171076 ..., -6.9410162 0.33765018 -4.41856956]]
因为y的shape是shape[每批次多少张图片,10],所以每行有10个数。
让我们构造个例子。
y=tf.constant([[-2,6,9,3,2,4,-8,1,5,-1], #每行找出最大数的坐标。
[4,5,6,-1,-2,8,10,1,3,4],
[1,2,3,4,55,-9,7,2,-3,-1]])
y_=tf.constant([[0,0,1,0,0,0,0,0,0,0], #每行找出最大数的坐标。
[0,0,0,0,0,0,0,0,1,0],
[0,0,0,0,1,0,0,0,0,0]])
correct = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) #两个坐标的位置是否一样
print(sess.run(correct))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
print(sess.run(accuracy))
输出:[ True False True]
0.666667
可见,以上我们人为构造的例子,正确预测率为三分之二,第二条没预测对。
通过上面2篇半博客,mnist_softmax.py就介绍完了,如果再不懂,撞墙。。。:)
最后解释两个概念:
1. 什么是logits?
答:从源码logits=y可以看出,logits不就是模型xW+b嘛。
2. 什么是 one-hot ?
答:只有一个热点,形如[0,0,1,0,0,0]的只有一个1,其它都是0的形式就是one-hot.
下面接着说多层卷积网。
据说识别率可以达到99.2%,而上个softmax模型不管咋搞只有92%,十个字里面错一个,想想还是头痛。
下面学习源码样例mnist_deep.py。
什么是修改线性单元ReLU?
先得说说修正器。修正器是激活函数的一种。我们学了softmax激活函数 ,大概了解sigmoid激活函数,修改器也是激活函数的一种。
修改器的定义;f(x)=x+=max(0,x)
参见:https://en.wikipedia.org/wiki/Rectifier_(neural_networks)
据说比sigmoid要好使,在DNN中最流行。
这个说完了,ReLU就好解释了,不就是使用修正器作激活函数的神经单元嘛。
这个函数比较硬,也就是说,在负值段是0,在原点突然就向上拔高,线条不柔和。所以又有了softplus。
softplus定义:f(x)=ln[1+exp(x)]
它的导数正好是Logistic函数: 1/[1+exp(-x)]
想象一下平躺在地上的一根钢条,用脚踩住中间,双手把一端向上掰上来,弯折的部分也是很柔和的,不会有一个尖角,对了,就是这个形状。
第一个简单函数:weight_variable:这里涉及一个函数initial = tf.truncated_normal(shape, stddev=0.1)。这个函数生成一个正态分布的tensor对象。
练习:
#生成一个10元素的向量,元素值随机,要求均值为0,标准差为1。
x = tf.truncated_normal([10])
输出:
[ 0.34689453 -0.80089593 -1.72287786 -0.41869378 0.77246767 -1.75758398 -0.53423828 0.00332778 0.85409206 -1.41753328]
#要求同上,但标准差(standard deviation,即stddev)为0.1.
x = tf.truncated_normal([10],stddev=0.1)
输出:
[ 0.18521971 0.10536867 -0.11113615 0.10921837 -0.1070381 0.14818405 0.07154682 -0.10790845 0.17011671 -0.0928892 ]
第二个简单函数:bias_variable,bias初值全部为0.1,没啥说的。
x = tf.constant(0.1, shape=[5])
输出:[ 0.1 0.1 0.1 0.1 0.1]
剩下两个函数其实内容挺多的,看完deepnn后再说。
conv2d:只有一句:tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME'),完成卷积运算。
x: input输入。
W:一个四维的tensor,[filter_height, filter_width, in_channels, out_channels]
strides=[1, 1, 1, 1]:
padding: 两种取值方式 "SAME", "VALID". VAlID就是顺着砍甘蔗,到最左或最后,不够一整节的就扔了。SAME是不够就前后补0,先简单这样理解着。
max_pool_2x2:也只有一句:tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
这两句是卷积神经网络模型的关键所在,先留第一个遗留问题。
deepnn中,分了几层:
1.第一卷积层
2.第二卷积层
3.全联接层
4.dropout层
5.输出层
每层的含义,留下第二个遗留问题。
main函数
注意的是,计算图采用了deepnn模型。
之后softmax,交叉熵与前面一样,没什么可说的。
优化器采用了AdamOptimizer,不再是坡度优化,算第三个遗留问题。
其它代码,如果前面的懂了,这里并不困难。
所以,在后面的内容中,我们主要看这三个遗留问题。(待续)














 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









