






IDL 是实现端对端之间可靠通讯的一套编码方案,业界著名的如 Protobuf 和 Thrift。随着系统越来越复杂和用户量的激增,需要把整个单体系统拆分成多个微服务,各个服务之间通过网络通信来组装响应信息。对于服务之间频繁的相互网络传输,传统的 HTTP 因为 Header 冗余信息过多、文本协议报文过大等拖慢了整体系统的效率。相比 HTTP ,RPC 在协议通用性和报文体积大小之间做了取舍,舍弃了通用性,换来体积精简的高性能。
本 Chat 会从以下几个方面描述:
- RPC 是什么、使用场景
- 自制属于自己的 IDL 语言
- 使用 MQTT 构建 RPC 报文交换
- 实现 RPC Client 和 Server
RPC 是什么
在很久之前的单机时代,一台电脑中跑着多个进程,进程之间没有交流各干各的,就这样过了很多年。突然有一天有了新需求,A 进程需要实现一个画图的功能,恰好邻居 B 进程已经有了这个功能,偷懒的程序员 C 想出了一个办法:A 进程调 B 进程的画图功能。于是出现了IPC(Inter-process communication,进程间通信)。就这样程序员 C 愉快的去吃早餐去了!
又过了几年,到了互联网时代,每个电脑都实现了互联互通。这时候雇主又有了新需求,当时还没挂的 A 进程需要实现使用tensorflow识别出笑脸 >_< 。说巧不巧,远在几千里的一台快速运行的电脑上已经实现了这个功能,睡眼惺忪的程序媛 D 接手了这个 A 进程后借鉴之前IPC的实现,把IPC扩展到了互联网上,这就是RPC(Remote Procedure Call,远程过程调用)。RPC其实就是一台电脑上的进程调用另外一台电脑上的进程的工具。成熟的RPC方案大多数会具备服务注册、服务发现、熔断降级和限流等机制。目前市面上的 RPC 已经有很多成熟的了,比如Facebook家的Thrift、Google家的gRPC、阿里家的Dubbo和蚂蚁家的SOFA。
接口定义语言
接口定义语言,简称IDL,是实现端对端之间可靠通讯的一套编码方案。这里有涉及到传输数据的序列化和反序列化,我们常用的 http 的请求一般用 json 当做序列化工具,定制rpc协议的时候因为要求响应迅速等特点,所以大多数会定义一套序列化协议。比如:
Protobuf:
// protobuf 版本syntax = "proto3";package testPackage;service testService { // 定义一个 ping 方法,请求参数集合 pingRequest, 响应参数集合 pingReply rpc ping (pingRequest) returns (pingReply) {}}message pingRequest { // string 是类型,param 是参数名,1 是指参数在方法的第 1 个位置 string param = 1;}message pingReply { string message = 1; string content = 2;}讲到Protobuf就得讲到该库作者的另一个作品Cap'n proto了,号称性能是直接秒杀Google Protobuf,直接上官方对比:

虽然知道很多比Protobuf更快的编码方案,但是快到这种地步也是厉害了,为啥这么快,Cap'n Proto 的文档里面就立刻说明了,因为Cap'n Proto没有任何序列号和反序列化步骤,Cap'n Proto编码的数据格式跟在内存里面的布局是一致的,所以可以直接将编码好的 structure 直接字节存放到硬盘上面。贴个栗子:
@0xdbb9ad1f14bf0b36; # unique file ID, generated by `capnp id`struct Person { name @0 :Text; birthdate @3 :Date; email @1 :Text; phones @2 :List(PhoneNumber); struct PhoneNumber { number @0 :Text; type @1 :Type; enum Type { mobile @0; home @1; work @2; } }}struct Date { year @0 :Int16; month @1 :UInt8; day @2 :UInt8;}我们这里要定制的编码方案就是基于protobuf和Cap'n Proto结合的类似的语法。因为本人比较喜欢刀剑神域里的男主角,所以就给这个库起了个名字 —— Kiritobuf。
首先我们定义kirito的语法:
# testservice testService { method ping (reqMsg, resMsg)}struct reqMsg { @0 age = Int16; @1 name = Text;}struct resMsg { @0 age = Int16; @1 name = Text;}#开头的是注释- 保留关键字,
service、method、struct, {}里是一个块结构()里有两个参数,第一个是请求的参数结构,第二个是返回值的结构@是定义参数位置的描述符,0表示在首位=号左边是参数名,右边是参数类型
参数类型:
- Boolean:
Bool - Integers:
Int8,Int16,Int32,Int64 - Unsigned integers:
UInt8,UInt16,UInt32,UInt64 - Floating-point:
Float32,Float64 - Blobs:
Text,Data - Lists:
List(T)
定义好了语法和参数类型,我们先过一下生成有抽象关系代码的流程:
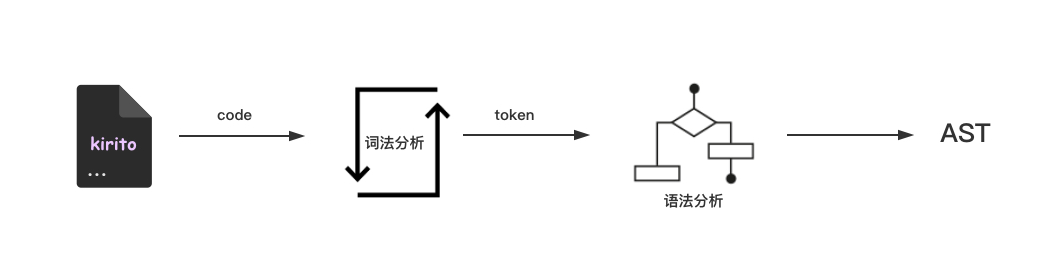
取到.kirito后缀的文件,读取全部字符,通过词法分析器生成token,得到的token传入语法分析器生成AST (抽象语法树)。
首先我们新建一个kirito.js文件:
'use strict';const fs = require('fs');const tokenizer = Symbol.for('kirito#tokenizer');const parser = Symbol.for('kirito#parser');const transformer = Symbol.for('kirito#transformer');// 定义词法分析 Token 类型 const TYPE = { // 保留字,service、struct、method... KEYWORD: 'keyword', // 变量 VARIABLE: 'variable', // 符号,{ } ( ) ; # @ , SYMBOL: 'symbol', // 参数位置,数值表示 0、1、2、3... INDEX: 'index'};// 定义语法分析字段类型const EXP = { // 变量 VARIABLE: 'Identifier', // 结构申明,service、struct、method STRUCT_DECLARATIONL: 'StructDeclaration', // 变量申明,@ VAR_DECLARATION: 'VariableDeclaration', // 数据类型, Int16、UInt16、Bool、Text... TYPE: 'DataType',};定义好了一些必要的字面量,接下来首先是词法分析阶段。
词法解析
我们设计词法分析得到的Token是这样子的:
[ { type: 'keyword', value: 'service' }, { type: 'variable', value: 'testService' }, { type: 'symbol', value: '{' }, { type: 'keyword', value: 'method' }, { type: 'variable', value: 'ping' }, { type: 'symbol', value: '(' }, { type: 'variable', value: 'reqMsg' }, { type: 'variable', value: 'resMsg' }, { type: 'symbol', value: ')' }, { type: 'symbol', value: '}' }, { type: 'keyword', value: 'struct' }, { type: 'variable', value: 'reqMsg' }, { type: 'symbol', value: '{' }, { type: 'symbol', value: '@' }, { type: 'index', value: '1' }, { type: 'variable', value: 'age' }, { type: 'symbol', value: '=' }, { type: 'variable', value: 'Int16' }, { type: 'symbol', value: ';' }, { type: 'symbol', value: '@' }, { type: 'index', value: '2' }, { type: 'variable', value: 'name' }, { type: 'symbol', value: '=' }, { type: 'variable', value: 'Text' }, { type: 'symbol', value: ';' }, { type: 'symbol', value: '}' }, { type: 'keyword', value: 'struct' }, { type: 'variable', value: 'resMsg' }, { type: 'symbol', value: '{' }, { type: 'symbol', value: '@' }, { type: 'index', value: '1' }, { type: 'variable', value: 'age' }, { type: 'symbol', value: '=' }, { type: 'variable', value: 'Int16' }, { type: 'symbol', value: ';' }, { type: 'symbol', value: '@' }, { type: 'index', value: '2' }, { type: 'variable', value: 'name' }, { type: 'symbol', value: '=' }, { type: 'variable', value: 'Text' }, { type: 'symbol', value: ';' }, { type: 'symbol', value: '}' } ]词法分析步骤:
- 把获取到的
kirito代码串按照\n分割组合成数组 A,数组的每个元素就是一行代码 - 遍历数组 A,将每行代码逐个字符去读取
- 在读取的过程中定义匹配规则,比如注释、保留字、变量、符号、数组等
- 将每个匹配的字符或字符串按照对应类型添加到 tokens 数组中
代码如下:
[tokenizer] (input) { // 保留关键字 const KEYWORD = ['service', 'struct', 'method']; // 符号 const SYMBOL = ['{', '}', '(', ')', '=', '@', ';']; // 匹配所有空字符 const WHITESPACE = /\s/; // 匹配所有 a-z 的字符、不限大小写 const LETTERS = /^[a-z]$/i; // 匹配数值 const NUMBER = /\d/; // 以换行符分割成数组 const source = input.split('\n'); // 最终生成的 token 数组 const tokens = []; source.some(line => { // 声明一个 `current` 变量作为指针 let current = 0; // 是否继续当前循环、移动到下一行,用于忽略注释 let isContinue = false; while (current < line.length) { let char = line[current]; // 匹配任何空字符 if (WHITESPACE.test(char)) { current++; continue; } // 忽略注释 if (char === '#') { isContinue = true; break; } // 匹配 a-z|A-Z 的字符 if (LETTERS.test(char)) { // 定义一个字符串变量,用来存储连续匹配成功的字符 let value = ''; // 匹配字符(变量/保留字)、字符加数字(参数类型) while (LETTERS.test(char) || NUMBER.test(char)) { // 追加字符 value += char; // 移动指针 char = line[++current]; } if (KEYWORD.indexOf(value) !== -1) { // 匹配保留关键字 tokens.push({ type: TYPE.KEYWORD, value: value }); } else { // 匹配变量名、类型 tokens.push({ type: TYPE.VARIABLE, value: value }); } continue; } // 匹配符号 { } ( ) = @ if (SYMBOL.indexOf(char) !== -1) { tokens.push({ type: TYPE.SYMBOL, value: char }); // 匹配@ 参数位置符号 if (char === '@') { char = line[++current]; // 匹配参数位置 0-9 if (NUMBER.test(char)) { // 定义参数位置字符串,用来存储连续匹配成功的参数位置 let index = ''; // 匹配参数位置 0-9 while (NUMBER.test(char)) { // 追加参数位置 `1`+`2`=`12` index += char; char = line[++current]; } tokens.push({ type: TYPE.INDEX, value: index }); } continue; } current++; continue; } current++; } // 跳过注释 if (isContinue) return false; }); return tokens; }语法分析
得到上面的词法分析的 token 后,我们就可以对该 token 做语法分析,我们需要最终生成的 AST 的格式如下:
{ "type": "Program", "body": [ { "type": "StructDeclaration", "name": "service", "value": "testService", "params": [ { "type": "StructDeclaration", "name": "method", "value": "ping", "params": [ { "type": "Identifier", "value": "reqMsg" }, { "type": "Identifier", "value": "resMsg" } ] } ] }, { "type": "StructDeclaration", "name": "struct", "value": "reqMsg", "params": [ { "type": "VariableDeclaration", "name": "@", "value": "1", "params": [ { "type": "Identifier", "value": "age" }, { "type": "DataType", "value": "Int16" } ] }, { "type": "VariableDeclaration", "name": "@", "value": "2", "params": [ { "type": "Identifier", "value": "name" }, { "type": "DataType", "value": "Text" } ] } ] }, { "type": "StructDeclaration", "name": "struct", "value": "resMsg", "params": [ { "type": "VariableDeclaration", "name": "@", "value": "1", "params": [ { "type": "Identifier", "value": "age" }, { "type": "DataType", "value": "Int16" } ] }, { "type": "VariableDeclaration", "name": "@", "value": "2", "params": [ { "type": "Identifier", "value": "name" }, { "type": "DataType", "value": "Text" } ] } ] } ]}看上图我们能友好的得到结构、参数、数据类型、函数之间的依赖和关系,步骤:
- 遍历词法分析得到的 token 数组,通过调用分析函数提取 token 之间的依赖节点
- 分析函数内部定义 token 提取规则,比如:
- 服务保留字 服务名 { 函数保留字 函数名 ( 入参,返回参数 ) }
- 参数结构保留字 结构名 { 参数位置 参数名 参数数据类型 }
- 递归调用分析函数提取对应节点依赖关系,将节点添加到 AST 中
代码如下:
[parser] (tokens) { // 声明 ast 对象,作为分析过程中的节点存储器 const ast = { type: 'Program', body: [] }; // 定义 token 数组指针变量 let current = 0; // 定义函数、用例递归分析节点之间的依赖和存储 function walk() { // 当前指针位置的 token 节点 let token = tokens[current]; // 检查变量、数据类型 if (token.type === TYPE.VARIABLE) { current++; return { type: EXP.VARIABLE, struct: tokens[current].value === '=' ? false : true, value: token.value }; } // 检查符号 if (token.type === TYPE.SYMBOL) { // 检查@,添加参数位置绑定 if (token.value === '@') { // 移动到下一个 token, 通常是个数值,也就是参数位置 token = tokens[++current]; // 定义参数节点,用来存储位置、变量名、数据类型 let node = { type: EXP.VAR_DECLARATION, name: '@', value: token.value, params: [] }; // 移动到下一个 token, 准备开始读取参数变量名和数据类型 token = tokens[++current]; // 每个参数节点以;符号结束 // 这个循环中会匹配参数变量名和参数数据类型并把他们添加到当前的参数节点上 while (token.value !== ';') { // 递归匹配参数变量名、数据类型 node.params.push(walk()); // 指定当前指针的 token token = tokens[current]; } // 移动 token 数组指针 current++; // 返回参数节点 return node; } // 检查=,匹配该符号右边的参数数据类型 if (token.value === '=') { // 移动到下一个 token token = tokens[++current]; current++; return { type: EXP.TYPE, value: token.value }; } current++; } // 检查保留字 if (token.type === TYPE.KEYWORD) { // 检查 service、struct if (['struct', 'service'].indexOf(token.value) !== -1) { // 缓存保留字 let keywordName = token.value; // 移动到下一个 token,通常是结构名 token = tokens[++current]; // 定义结构节点,用来储存结构保留字、结构名、结构参数数组 let node = { type: EXP.STRUCT_DECLARATIONL, // 保留字 name: keywordName, // 结构名 value: token.value, // 参数数组 params: [] }; // 移动到下一个 token token = tokens[++current]; // 匹配符号且是{,准备解析{里的参数 if (token.type === TYPE.SYMBOL && token.value === '{') { // 移动到下一个 token token = tokens[++current]; // 等于}是退出参数匹配,完成参数储存 while (token.value !== '}') { // 递归调用分析函数,获取参数数组 node.params.push(walk()); // 移动 token 到当前指针 token = tokens[current]; } current++; } // 返回结构节点 return node; } if (token.value === 'method') { // 检查 method,匹配请求函数名 token = tokens[++current]; // 定义请求函数节点,用来储存函数入参和返回参数 let node = { type: EXP.STRUCT_DECLARATIONL, name: 'method', value: token.value, params: [] }; // 移动到下一个 token token = tokens[++current]; // 匹配(符号,准备储存入参和返回参数 if (token.type === TYPE.SYMBOL && token.value === '(') { // 移动到入参 token token = tokens[++current]; // 等于)时退出匹配,完成函数匹配 while (token.value !== ')') { // 递归调用分析函数 node.params.push(walk()); token = tokens[current]; } current++; } // 返回函数节点 return node; } } // 抛出未匹配到的错误 throw new TypeError(token.type); } // 遍历 token 数组 while (current < tokens.length) { ast.body.push(walk()); } // 返回 ast return ast; }转换器
得到了语法分析的AST后我们需要进一步对AST转换为更易操作的js 对象。格式如下:
{ testService: { ping: { [Function] param: { reqMsg: { age: 'Int16', name: 'Text' }, resMsg: { age: 'Int16', name: 'Text' } } } } }通过上面这个格式,我们可以更容易的知道有几个service、service里有多少个函数以及函数的参数。
代码如下:
// 转换器 [transformer] (ast) { // 定义汇总的 service const services = {}; // 定义汇总的 struct,用来储存参数结构,以便最后和 service 合并 const structs = {}; // 转换数组 function traverseArray(array, parent) { // 遍历数组 array.some((child) => { // 分治转换单个节点 traverseNode(child, parent); }); } function traverseNode (node, parent) { switch (node.type) { case 'Program': // 根节点 traverseArray(node.body, parent); break; case 'StructDeclaration': // 匹配 service、struct、method 类型节点 if (node.name === 'service') { // 定义 service 的父节点为对象,为了更好的添加属性 parent[node.value] = {}; // 调用数组转换函数解析,并把父节点传入以便添加子节点 traverseArray(node.params, parent[node.value]); } else if (node.name === 'method') { // 定义一个空函数给 method 节点 parent[node.value] = function () {}; // 在该函数下挂载一个 param 属性作为函数的参数列表 parent[node.value].param = {}; traverseArray(node.params, parent[node.value].param); } else if (node.name === 'struct') { // 定义 struct 的父节点为一个对象 structs[node.value] = {}; // 解析 struct traverseArray(node.params, structs[node.value]); } break; case 'Identifier': // 定义参数变量 parent[node.value] = {}; break; case 'VariableDeclaration': // 解析参数数组 traverseArray(node.params, parent); break; case 'DataType': // 参数数据类型 parent[Object.keys(parent).pop()] = node.value; break; default: // 抛出未匹配到的错误 throw new TypeError(node.type); } } traverseNode(ast, services); // 合并 service 和 struct const serviceKeys = Object.getOwnPropertyNames(services); serviceKeys.some(service => { const methodKeys = Object.getOwnPropertyNames(services[service]); methodKeys.some(method => { Object.keys(services[service][method].param).some(p => { if (structs[p] !== null) { services[service][method].param[p] = structs[p]; delete structs[p]; } }); }); }); return services; }传输协议
RPC协议有多种,可以是json、xml、http2,相对于 http1.x 这种文本协议,http2.0 这种二进制协议更适合作为RPC的应用层通信协议。很多成熟的RPC框架一般都会定制自己的协议已满足各种变化莫测的需求。
比如Thrift的TBinaryProtocol、TCompactProtocol等,用户可以自主选择适合自己的传输协议。
大多数计算机都是以字节编址的(除了按字节编址还有按字编址和按位编址),我们这里只讨论字节编址。每个机器因为不同的系统或者不同的 CPU 对内存地址的编码有不一样的规则,一般分为两种字节序:大端序和小端序。
大端序: 数据的高字节保存在低地址
小端序: 数据的低字节保存在高地址
举个栗子:
比如一个整数:258,用 16 进制表示为0x0102,我们把它分为两个字节0x01和ox02,对应的二进制为0000 0001和0000 0010。在大端序的电脑上存放形式如下:

小端序则相反。为了保证在不同机器之间传输的数据是一样的,开发一个通讯协议时会首先约定好使用一种作为通讯方案。java 虚拟机采用的是大端序。在机器上我们称为主机字节序,网络传输时我们称为网络字节序。网络字节序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节序采用大端排序方式。
我们这里就不造新应用层协议的轮子了,我们直接使用MQTT协议作为我们的默认应用层协议。MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的“轻量级”通讯协议,采用大端序的网络字节序传输,该协议构建于TCP/IP协议上。
实现通讯
先贴下实现完的代码调用流程,首先是 server 端:
'use strict';const pRPC = require('..');const path = require('path');const kiritoProto = './protocol/test.kirito';const server = new pRPC.Server();// 解析 kirito 文件生成 js 对象const proto = pRPC.load(path.join(__dirname, kiritoProto));// 定义 client 端可以调用的函数function test(call, cb) { cb(null, {age: call.age, name: call.name});}// 加载 kirito 解析出来的对象和函数绑定,这里声明了 ping 的执行函数 testserver.addKiritoService(proto.testService, {ping: test});server.listen(10003);client 端:
'use strict';const pRPC = require('..');const path = require('path');const kiritoProto = './protocol/test.kirito';// 解析 kirito 文件生成 js 对象const proto = pRPC.load(path.join(__dirname, kiritoProto));// 分配一个 client 实例绑定 kirito 解析的对象并连接 serverconst client = new pRPC.Client({host: 'localhost', port: 10003}, proto.testService);// 调用 server 端的函数client.ping({age: 23, name: 'ricky 泽阳'}, function (err, result) { if (err) { throw new Error(err.message); } console.log(result);});无论是 server 端定义函数或者 client 端调用函数都是比较简洁的步骤。接下来我们慢慢剖析具体的逻辑实现。
贴下具体的调用流程架构图:
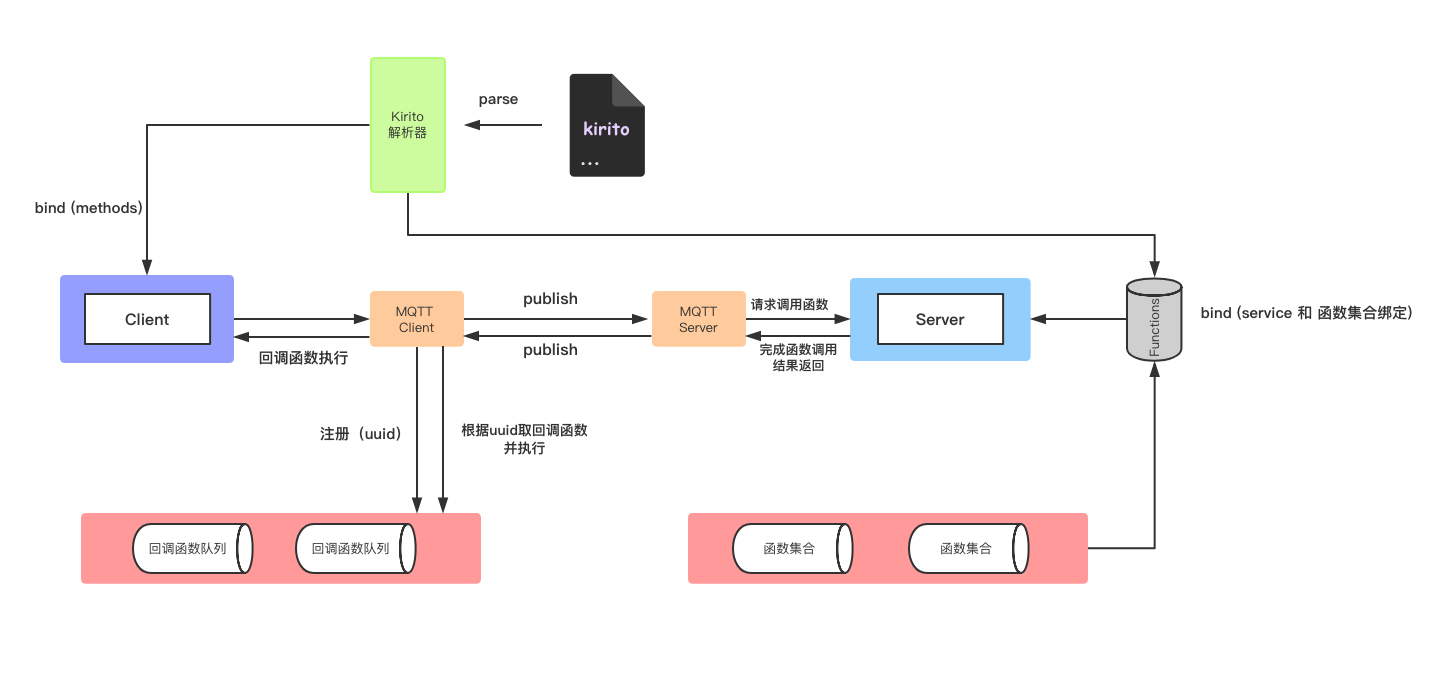
调用流程总结:
- client 端解析 kirito 文件,绑定 kirito 的 service 到 client 对象
- server 端解析 kirito 文件,将 kiritod 的 service 与调用函数绑定添加到 server 对象
- client 端调用 kirito service 里定义的函数,注册回调事件,发起 MQTT 请求
- server 端接收 MQTT 请求,解析请求 body,调用对应的函数执行完后向 client 端发起 MQTT 请求
- client 端接收到 MQTT 请求后,解析 body 和 error,并从回调事件队列里取出对应的回调函数并赋值执行
说完了调用流程,现在开始讲解具体的实现。
server:
// protocol/mqtt.js'use strict';const net = require('net');const debug = require('debug')('polix-rpc:mqtt');const EventEmitter = require('events').EventEmitter;const mqttCon = require('mqtt-connection');// 定义 server 类,继承 EventEmitter 是为了更好的将模块解耦class MQTT extends EventEmitter { constructor () { super(); // 是否已经开启服务 this.inited = false; // 函数集合 this.events = {}; } // 监听端口并开启服务 listen (port, cb) { // 已经初始化了就不用再次 init if (this.inited) { cb && cb(new Error('already inited.', null)); return; } // 赋值当前作用域上下文的指针给 self 对象,用来在非当前作用的函数执行当前作用域的代码 const self = this; // 设置初始化 this.inited = true; // 实例化一个 net 服务 this.server = new net.Server(); this.port = port || 10003; // 监听端口 this.server.listen(this.port); debug('MQTT Server is started for port: %d', this.port); // 监听 error 事件 this.server.on('error', (err) => { debug('rpc server is error: %j', err.stack); self.emit('error', err); }); // 监听连接事件 this.server.on('connection', (stream) => { // 实例化 mqtt 对象 const socket = mqttCon(stream); debug('=========== new connection ==========='); // 监听 mqtt 服务 connect 事件 socket.on('connect', () => { debug('connected'); socket.connack({ returnCode: 0 }); }); socket.on('error', (err) => { debug('error : %j', err); socket.destroy(); }); socket.on('close', () => { debug('=========== close ============'); socket.destroy(); }); socket.on('disconnect', () => { debug('=========== disconnect ============'); socket.destroy(); }); // 监听 mqtt 服务 publish 事件,接收 client 端请求 socket.on('publish', (pkg) => { // 消费 client 端的请求 self.consumers(pkg, socket); }); }); } // 消费 client 端的请求 consumers (pkg, socket) { // 赋值当前作用的指针给 self 对象 const self = this; // 将 client 的数据包转成 json 字符,字节序不同的处理已经在 mqtt 的底层转换好了 let content = pkg.payload.toString(); debug(content); content = JSON.parse(content); // 定义响应数据包 const respMsg = { msgId: content.msgId }; // 如果请求调用的函数不存在则加上错误消息响应回去 client 端 if (this.events[content.method] === null) { // 定义调用错误消息 respMsg.error = { message: `not found ${content.method} method` }; // 推送到 client 端 self.response(socket, {messageId: pkg.messageId, body: respMsg}); } else { // 如果存在有效的函数则准备调用 const fn = this.events[content.method].method; // 设置调用函数的回调事件,用来处理调用函数完成后的参数返回 const callback = function (err, result) { // 获取调用完后的参数结果 respMsg.body = result; // 推送到 client 端 self.response(socket, {messageId: pkg.messageId, body: respMsg}); }; // 执行调用参数 fn.call(fn, content.body, callback); } } // 推送调用结果数据包给 client 端 response (socket, result) { socket.publish({ topic: 'rpc', qos: 1, messageId: result.messageId, payload: JSON.stringify(result.body) }); } // 绑定 kirito 定义的函数集合 addEvent (events) { const eventKeys = Object.getOwnPropertyNames(events); eventKeys.some(event => { this.events[event] = { method: events[event].method, param: events[event].param }; }); }}module.exports.create = function () { return new MQTT();};定义 protocol 接口,加上这一层是为了以后的多协议,mqtt 只是默认使用的协议:
// protocol.js'use strict';const mqtt = require('./protocol/mqtt');module.exports.create = function (opts = {}) { return mqtt.create(opts);};接下来是 server 端的暴露出去的接口:
// index.js'use strict';const protocol = require('./protocol.js');class Server { constructor () { // 实例化协议对象 this.server = protocol.create(); } // 将 kirito 定义的接口和函数集合绑定 addKiritoService (service, methods) { const serviceKeys = Object.getOwnPropertyNames(service); const methodKeys = Object.getOwnPropertyNames(methods); const events = {}; serviceKeys.some(method => { let idx = -1; if ((idx = methodKeys.indexOf(method)) !== -1) { events[method] = { method: methods[method], param: service[method].param }; methodKeys.splice(idx, 1); } }); if (Object.keys(events).length > 0) { this.server.addEvent(events); } } listen (port) { this.server.listen(port); }}module.exports = Server;client:
// protocol/mqtt.js'use strict';const net = require('net');const debug = require('debug')('polix-rpc:mqtt');const EventEmitter = require('events').EventEmitter;const mqttCon = require('mqtt-connection');class MQTT extends EventEmitter { constructor (server) { super(); // 获取 server 端连接信息 this.host = server.host || 'localhost'; this.port = server.port || 10003; // 是否服务已连接 this.connected = false; // 是否服务已关闭 this.closed = false; } // 连接 server 服务 connect (cb) { // 连接了就不用再次执行连接 if (this.connected) { cb && cb (new Error('mqtt rpc has already connected'), null); return; } // 复制当前作用域上下文的指针给 self 变量 const self = this; // 获取 net 服务连接流 const stream = net.createConnection(this.port, this.host); // 初始化 mqtt 服务 this.socket = mqttCon(stream); // 监听 conack 事件 this.socket.on('connack', (pkg) => { debug('conack: %j', pkg); }); // 监听 error 事件 this.socket.on('error', function (err) { debug('error: %j', err); }); // 监听 publish 事件,接收 server 端调用函数结果的返回数据 this.socket.on('publish', (pkg) => { // 将数据包转成 json 字符 const content = pkg.payload.toString(); debug(content); // 将数据转发到 MQTT 的对象事件上 this.emit('data', JSON.parse(content)); }); // 监听 puback 事件 this.socket.on('puback', (pkg) => { debug('puback: %j', pkg); }); // 发起连接 this.socket.connect({ clientId: 'MQTT_RPC_' + Math.round(new Date().getTime() / 1000) }, () => { if (self.connected) { return; } // 设置已连接 self.connected = true; cb && cb(null, {connected: self.connected}); }); } // 发起调用函数请求 send (param) { this.socket.publish({ topic: 'rpc', qos: 1, messageId: 1, payload: JSON.stringify(param || {}) }); } // 关闭连接 close () { if (this.closed) { return; } this.closed = true; this.connected = false; this.socket.destroy(); }}module.exports.create = function (server) { return new MQTT(server || {});};定义 protocol 接口:
// protocol.js'use strict';const mqtt = require('./protocol/mqtt');module.exports.create = function (opts = {}) { return mqtt.create(opts);};最后是 client 端暴露的接口:
'use strict';const protocol = require('./protocol.js');const connect = Symbol.for('connect');const uuid = require('uuid/v1');class Client { constructor(opts, service) { // 声明 client 实例 this.client = void(0); // 调用协议连接接口 this[connect](opts, service); // 定义回调参数集合 this.callQueues = {}; } // 连接 server [connect] (opts, service) { // 初始化协议服务 this.client = protocol.create(opts); // 发起连接 this.client.connect((err) => { if (err) { throw new Error(err); } }); // 复制当前作用域的上下文指针给 self 对象 const self = this; // 监听协议 data 时间,接收协议转发 server 端响应的数据 this.client.on('data', function (result) { // 听过 msgId 取出回调函数 const fn = self.callQueues[result.msgId]; // 如果有调用错误信息,则直接回调错误 if (result.error) { return fn.call(fn, result.error, null); } // 执行回调 fn.call(fn, null, result.body); }); // 绑定 kirito 定义的接口参数到协议对象中 const serviceKeys = Object.getOwnPropertyNames(service); serviceKeys.some(method => { // 增加 client 端的函数,对应 server 端的调用函数 self[method] = function () { // 取出发送的数据 const reqMsg = arguments[0]; // 取出回调函数 const fn = arguments[1]; const paramKey = Object.getOwnPropertyNames(service[method].param); paramKey.some((param) => { if (reqMsg[param] === null) { throw new Error(`Parameters '${param}' are missing`); } // todo 类型判断及转换 }); // 为每个请求标记 const msgId = uuid(); // 注册该请求的回调函数到回调队列中 self.callQueues[msgId] = fn; // 发起调用函数请求 self.client.send({method, msgId, body: reqMsg}); }; }); }}module.exports = Client;就这样,一个简单的 IDL+RPC 框架就这样搭建完成了。这里只是描述 RPC 的原理和常用的调用方式,要想用在企业级的开发上,还得加上服务发现、注册,服务熔断,服务降级等,读者如果有兴趣可以在 Github 上 fork 下来或者提 PR 来改进这个框架,有什么问题也可以提 Issue, 当然 PR 是最好的 : ) 。
仓库地址:
RPC: https://github.com/polixjs/polix-rpc
IDL: https://github.com/rickyes/kiritobuf
阅读全文: http://gitbook.cn/gitchat/activity/5e860bc9556c644e2c73363d
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。















 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









