










作为一个程序员,经常用到排序算法。学习数据结构也是从排序算法开始,楼主就讲我学习9种排序算法心得,仅供参考,如有不当请谅解。以下排序算法都是使用一个长度为n的乱序整型数组为例进行排序。
1、冒泡排序
原理:冒泡排序算法的思想很简单,就是循环迭代,每一次迭代从数组头开始,迭代过程中比较下一个相邻的元素,如果前面的元素大,那么就交换两个元素的位置,比较元素向后移一位;如果小于等于就不需要交换位置,比较元素向后移一位。第一次遍历数组至结尾不断交换到数组末尾得到最大的元素放到数组末尾,第m次迭代在数组的前n-m+1元素中不断交换得到最大的数放在n-m+1位置上,直到m等于n。
示例:3 1 5 2 4
第1次迭代:1 3 5 2 4 ->13 5 2 4 -> 1 3 2 5 4 ->1 3 2 4 5
第2次迭代:1 3 2 4 5 ->12 3 4 5 -> 1 2 3 4 5
第3次迭代:1 2 3 4 5 ->12 3 4 5
第4次迭代:1 2 3 4 5
结束
分析:冒泡排序算法其实性能并不是太理想,随着排序数组的增大,消耗的时间相对与其它排序算法大大增加。但冒泡消耗空间并不大,仅仅为n,影响性能的原因在于不断交换数组元素的位置,也就是写内存的时间比较多。它的比较次数并不会和数组顺序有关,交换对于乱序数组可以认为是相同的,因此它是稳定的,它的时间复杂度是:O(n2)
java代码:
//冒泡排序
void bubblesort(int a[],int n){
for(int j=n;j>0;j--){
for(int i=0;i<j-1;i++){
if(a[i]>a[i+1]){
int temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;
}
}
}
}2、插入排序
原理:插入排序的原理是从数组头开始循环迭代。保持循环过的前m个元素形成有序数组,然后使用m+1个元素插入到这个有序数组中,插入过程是使用m+1个元素作为比较元素,从m到数组头比较寻找插入位置,向前比较过程中一旦小于,那么就将被比较的元素向后移一位,但并不把比较元素插入到空挡中,而是不断的向前比较直到小于等于才把比较元素插入到这个位置。插入后比较元素向后移一位,直到比较元素m等于n。
示例:3 1 5 2 4
第1次循环:1 3 5 2 4
第2次循环:1 3 5 2 4
第3次循环:1 3 2 5 4 ->1 2 3 5 4
第4次循环:1 2 3 4 5
结束
分析:插入排序相对于冒泡来说,性能相对提高了一些,因为某些元素可能很快找到插入的位置而提前结束循环,但它的性能还是因为某些元素可能一直需要移动相对于其它排序算法还是有一定的距离。它消耗的空间也是n,插入过程的比较过程受到数组顺序的影响,因此它是不稳定的,时间复杂度是:O(n2)。
java代码:
//插入排序
void insertSort(int a[],int n){
for(int i=1;i<n;i++){
int b=a[i];
int j;
for(j=i-1;j>=0&&b<a[j];j--)
a[j+1]=a[j];
a[j+1]=b;
}
}
3、名次排序
原理:名次排序的原理也很简单,就是对乱序数组进行排名,然后把每个元素放到数组的排名位置上。如:第一名(最大元素)放到数组末尾,最后一名(最小元素)放到数组头。
示例:3 1 5 4 2
排名数组: 3 5 1 2 4
每个元素按名次放到对应数组位置:a[5-3]=3 ; a[5-5]=1 ;a[5-1]=5 ; a[5-2]=4 ; a[5-4]=2;
最后得到的数组:1 2 3 4 5
分析:名次排序需要消耗n空间的排名空间,因此需要2n的空间,而排名过程也需要n(n-1)/2次,因此名次排序的性能其实也不是太高,名次排序的排名次数,和写内存次数和数组的顺序没有关系,因此它是稳定的,它的时间复杂度是:O(n2)。
java代码:
//名次排序
void rearrange(int a[],int n){
int []r=new int[n+1];
for(int i=0;i<n+1;i++)
r[i]=0;
for(int i=0;i<n;i++){
for (int j=0;j<=i;j++){
if(a[i]>a[j])
r[i]++;
else
r[j]++;
}
}
int [] u=new int [n+1];
for (int i=0;i<n+1;i++)
u[r[i]]=a[i];
for(int i=1;i<n+1;i++)
a[i-1]=u[i];
}
4、选择排序
原理:选择排序的原理与冒泡排序的原理很相似,每次循环从数组的第一个元素开始,第m次遍历寻找前n-m+1个元素中的最大元素,与冒泡排序不同的是向后比较寻找前n-m+1个最大元素的过程中只需要记住最大元素的位置,直到n-m+1时才交换最大元素与n-m+1元素的位置,而不需要在比较过程中交换位置。每次循环结束m+1,直到m=n。
示例:3 1 5 2 4
第1次循环:3 14 25
第2次循环:3 12 4 5
第3次循环:2 13 4 5
第4次循环:1 2 3 4 5
结束
分析:选择排序每次循环都能使得一个元素放到正确位置上,而且一次循环只需要一次交换写内存,因此选择排序的性能还是不错的,另外它消耗的空间仅仅是n。选择排序每次选择最大的数比较次数是相同的,而对于交换次数对于数组的顺序是有一些不太相同,但对于大多数乱序数组,可以认为交换次数相同,因此它也是相对稳定的,它的时间复杂度是:O(n2)。
java代码:
//选择排序
void selectionsort(int a[],int n){
for(int size=n;size>1;size--){
int indexofmax=0;
for(int i=1;i<size;i++){
if(a[indexofmax]<=a[i])
indexofmax=i;
}
int temp=a[size-1];
a[size-1]=a[indexofmax];
a[indexofmax]=temp;
}
} 5、基数排序(箱子排序)
原理:基数排序的原理是从个位数开始排序,然后是十位数,直到最高位数。这个原理的来源是“推箱子”,每个数都是由0-9的数字组成,那么对于每位数来说,就是这10个数字中的一位,那么就分配10个箱子,分别标号0-9,将现排序位数的数字的元素扔到对应的箱子内。从低位箱子扔到高位箱子时需要保持扔的顺序,直到最高位数,最后将这十个箱子推倒,这十个箱子内的元素就形成了一个有序的数组。因此基数排序也叫做箱子排序。
示例:32 23 24 34 33 22
第一次扔入箱子:2号 32 22 3号23 33 4号24 34
第二次扔入箱子:2号 22 23 24 3号32 33 34
将箱子推倒得到序列:22 23 24 32 33 34
分析:箱子排序的缺点就是需要消耗箱子的空间,而箱子的空间是n,一共需要2n的空间,当排序个数很少时,还可能消耗一些不需要的箱子。每一个元素每一位数都要进行比较,也需要扔入箱子,因此次数与数组的顺序无关,这个排序算法是稳定的,时间复杂度是O(n2)。
java代码:
void jishusort(int[]a,int n,int number) {
//判断位数
int times = 0;
while(number>0){
number = number/10;
times++;
}
//建立十个队列
List<ArrayList> queue = new ArrayList<ArrayList>();
for (int i = 0; i < 10; i++) {
ArrayList queue1 = new ArrayList();
queue.add(queue1);
}
//进行times次分配和收集
for (int i = 0; i < times; i++) {
//分配
for (int j = 0; j < n; j++) {
int x = a[j]%(int)Math.pow(10, i+1)/(int)Math.pow(10, i);
ArrayList queue2 = queue.get(x);
queue2.add(a[j]);
queue.set(x,queue2);
}
//收集
int count = 0;
for (int j = 0; j < 10; j++) {
while(queue.get(j).size()>0){
ArrayList<Integer> queue3 = queue.get(j);
a[count] = queue3.get(0);
queue3.remove(0);
count++;
}
}
}
}
6、堆排序
原理:堆排序的原理是根据堆数据结构的特征。一个堆是一棵完全二叉树,其中大根堆的每个父节点都比子节点大,而小根堆的每个父节点都比子节点小。当使用小根堆排序时,只需要将数组所有元素插入到小根堆中,然后依次从小根堆中把根节点取出并删除,即可得到一个有序的数组。
示例:
分析:堆排序也是需要消耗n空间来构建堆,因此需要2n空间,而影响性能和堆的插入与删除操作有很大关系。还好堆排序的性能还是不错的,因为堆的构建和删除和数组的顺序有关,因此堆排序是不稳定的。堆排序的时间复杂度是:O(n*log n)。
java代码:
//定义树节点
class treeNode{
int element;
treeNode leftChild,
rightChild;
void treeNode(){leftChild=rightChild=null;}
treeNode(int theElement){
element=theElement;
leftChild=rightChild=null;}
treeNode(int theElement,treeNode theleftchild,
treeNode therightchild){
element=theElement;
leftChild=theleftchild;
rightChild=therightchild;}
};
//小根堆
class minHeap{
treeNode root;
int heapSize;
minHeap(){
root=null;
heapSize=0;
}
int top(){
return root.element;
}
treeNode begin(){
return root;
}
void visit(treeNode t){
System.out.println(t.element+" ");
}
void perOrder(treeNode t)
{
if (t != null)
{
visit(t);
perOrder(t.leftChild);
perOrder(t.rightChild);
}
}
void insert(int theElement){
if(root==null){
root=new treeNode (theElement);
heapSize++;
}
else{
int tem=theElement;
int tem1;
int a=heapSize+1,i=0;
int []b=new int[20];
while(a>1){
i++;
b[i]=a%2;
a=a/2;
}
treeNode p=root;
if(root.element>tem){
tem=p.element;
root.element=theElement;
}
while(i>1){
if(b[i]==0)
p=p.leftChild;
else
p=p.rightChild;
i--;
if(p.element>tem){
tem1=p.element;
p.element=tem;
tem=tem1;
}
}
if(b[1]==0)
p.leftChild=new treeNode(tem);
else
p.rightChild=new treeNode(tem);
heapSize++;
}
}
void pop(){
if(root==null){
System.out.println("当前堆为空");
return;
}
if(heapSize==1){
root=null;
heapSize--;
}
else{
int a=heapSize,i=0;
int []b=new int [20];
int tem,tem1=0;
while(a>1){
i++;
b[i]=a%2;
a=a/2;
}
treeNode p=root;
while(i>1){
if(b[i]==0)
p=p.leftChild;
else
p=p.rightChild;
i--;}
if(b[1]==0){
tem=p.leftChild.element;
p.leftChild=null;}
else{
tem=p.rightChild.element;
p.rightChild=null;}
p=root;
while(p.leftChild!=null&&p.rightChild!=null){
if(p.leftChild.element<=p.rightChild.element){
if(p.leftChild.element<=tem)
p.element=p.leftChild.element;
else{
tem1=p.leftChild.element;
p.element=tem;
tem=tem1;
}
p=p.leftChild;}
else{
if(p.rightChild.element<=tem)
p.element=p.rightChild.element;
else{
tem1=p.rightChild.element;
p.element=tem;
tem=tem1;
}
p=p.rightChild;
}
}
if(p.leftChild==null)
p.element=tem;
else{
if(p.leftChild.element>=tem)
p.element=tem;
else{
p.element=p.leftChild.element;
p.leftChild.element=tem;
}
}
heapSize--;
}
}
}
//堆排序
void heapSort(int a[],int n){
minHeap heap=new minHeap();
for(int i=0;i<n;i++)
heap.insert(a[i]);
for(int i=0;i<n;i++){
int x=heap.top();
heap.pop();
a[i]=x;
}
}
7、归并排序:
原理:将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
示例:1 3 5 2 4
第一次归并: 1 3 2 5 4
第二次归并:1 2 3 54
第三次归并:1 2 3 4 5
分析:归并排序可以使用递归方式进行排序,每次排序个数增加两倍,因此它需要消耗的空间是log n,它递归过程的次数是稳定的,它的时间复杂度是O(n*log n)。
java代码:
//归并排序
void mergeSort(int[] a, int left, int right) {
if(left<right){
int middle = (left+right)/2;
//对左边进行递归
mergeSort(a, left, middle);
//对右边进行递归
mergeSort(a, middle+1, right);
//合并
merge(a,left,middle,right);
}
}
private static void merge(int[] a, int left, int middle, int right) {
int[] tmpArr = new int[a.length];
int mid = middle+1; //右边的起始位置
int tmp = left;
int third = left;
while(left<=middle && mid<=right){
//从两个数组中选取较小的数放入中间数组
if(a[left]<=a[mid]){
tmpArr[third++] = a[left++];
}else{
tmpArr[third++] = a[mid++];
}
}
//将剩余的部分放入中间数组
while(left<=middle){
tmpArr[third++] = a[left++];
}
while(mid<=right){
tmpArr[third++] = a[mid++];
}
//将中间数组复制回原数组
while(tmp<=right){
a[tmp] = tmpArr[tmp++];
}
}
}
8、快速排序:
原理:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分。
示例:3 1 5 2 4
第一次递归:1 2 3 5 4
第二次递归:1 2 34 5
结束
分析:快速排序可以说是目前排序算法中性能最优的,它可以使用递归的方式进行排序,在每一次递归过程中至少有一个元素到达正确的位置,但是由于递归的原因,它所消耗的空间从O(log2n)到O(n)不等。但是它的性能受到排序数组顺序的影响,它是不稳定的,它的时间复杂度是:O(n*log n)。
java代码:
//快速排序
private static boolean isEmpty(int[] n) {
return n == null || n.length == 0;
}
public static void quickSort(int[] n) {
if (isEmpty(n))
return;
quickSort(n, 0, n.length - 1);
}
public static void quickSort(int[] a, int l, int h) {
if (isEmpty(a))
return;
if (l < h) {
int pivot = partion(a, l, h);
quickSort(a, l, pivot - 1);
quickSort(a, pivot + 1, h);
}
}
private static int partion(int[] a, int start, int end) {
int tmp = a[start];
while (start < end) {
while (a[end] >= tmp && start < end)
end--;
if (start < end) {
a[start++] = a[end];
}
while (a[start] < tmp && start < end)
start++;
if (start < end) {
a[end--] = a[start];
}
}
a[start] = tmp;
return start;
}9、希尔排序
原理:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。
示例:3 1 5 2 4
第一次分组:1 32 4 5
第二次分组:1 2 3 4 5
结束
分析:希尔排序采用分组插入排序的思想,因为每个分组都是有序序列,因此每次能够插入的数量可以很多,从而提高了效率,它的性能在排序算法中比较好。它花费的空间是n,时间复杂度最小时能够达到O(n*log n)。
java代码:
//希尔排序
void binsort(int a[],int n){
while(true){
n = n / 2;
for(int x=0;x<n;x++){
for(int i=x+n;i<a.length;i=i+n){
int temp = a[i];
int j;
for(j=i-n;j>=0&&a[j]>temp;j=j-n){
a[j+n] = a[j];
}
a[j+n] = temp;
}
}
if(n == 1){
break;
}
}
}
10、几种排序算法实际性能对比:
虽然对于一些排序算法来说,时间复杂度是相同的,但是由于写内存和分配内存的次数不相同,他们之间的性能差别还是很大的。下面就通过一个实际测试看看这些排序算法的差别(缺少名次排序,它的性能和差不多),测试使用算法对同一乱序整型数组进行排序。
对于小数目和小数据1000个元素的对比:基本上都没有太大差别,有些算法还因为时间太短,连1毫秒都不到。
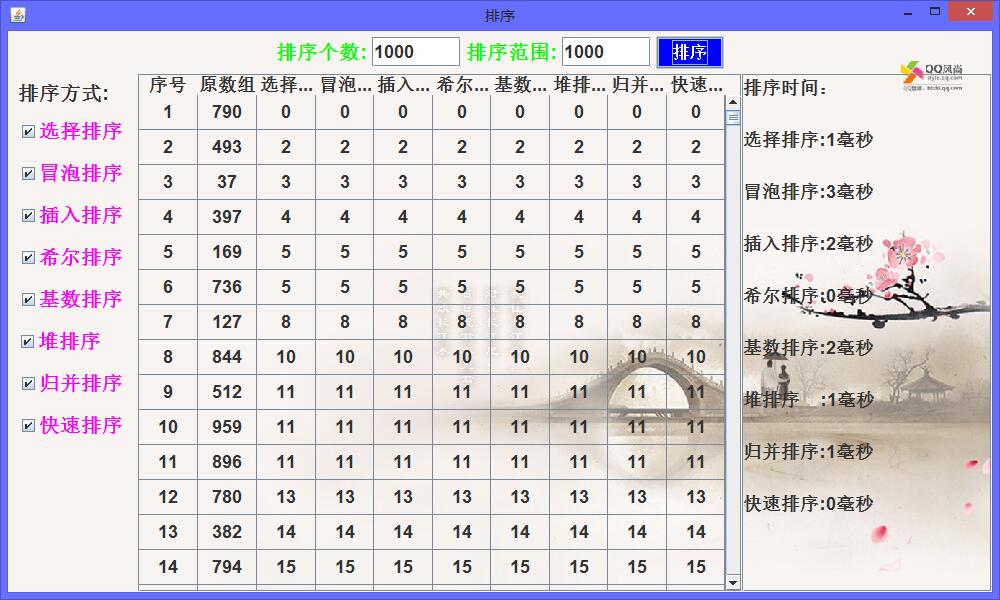
将数据升到10000,再进行排序,性能的差别开始出现了,冒泡排序所花费的时间最长。
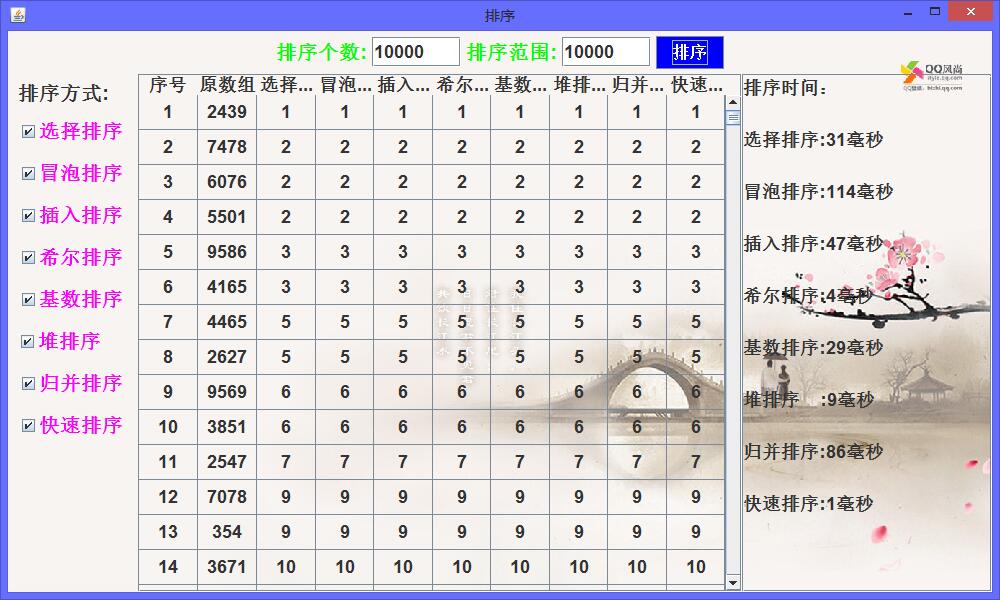
继续增加排序数组的数量至100000,发现有些排序算法花的时间多了起来,将性能不太好的算法取消掉。
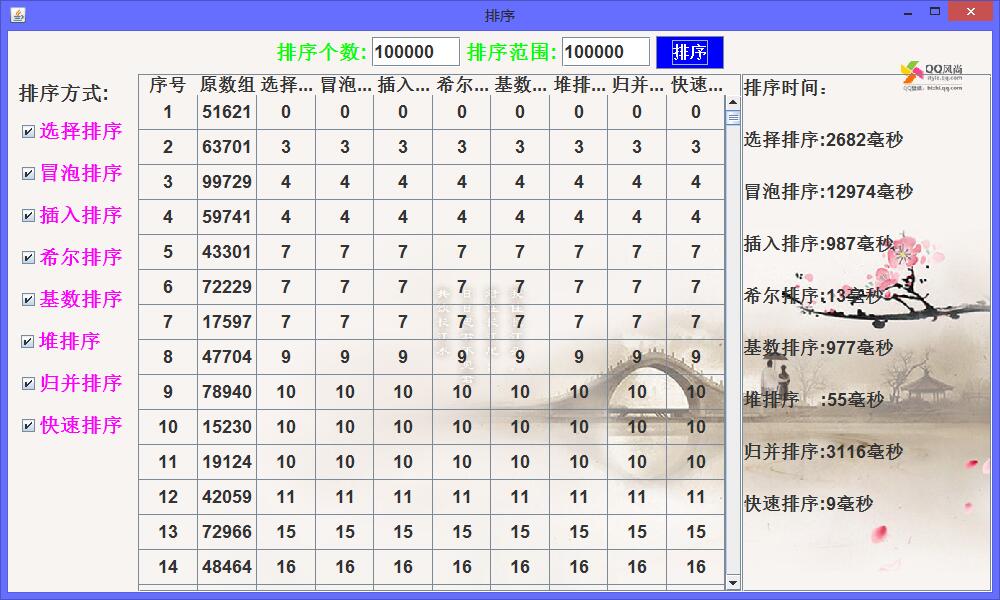
继续增加数量至1000000,堆排序开始跟不上节奏了,将它取消掉。
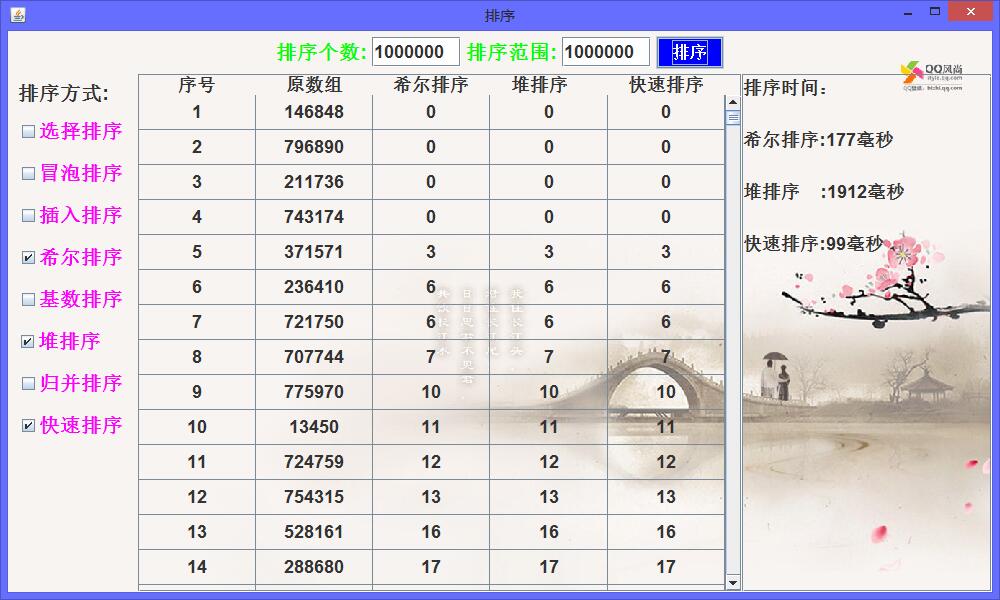
最后将数组数量增加到10000000,在一千万的数据量下,快速排序仍然能够在1秒内就将数据排好。
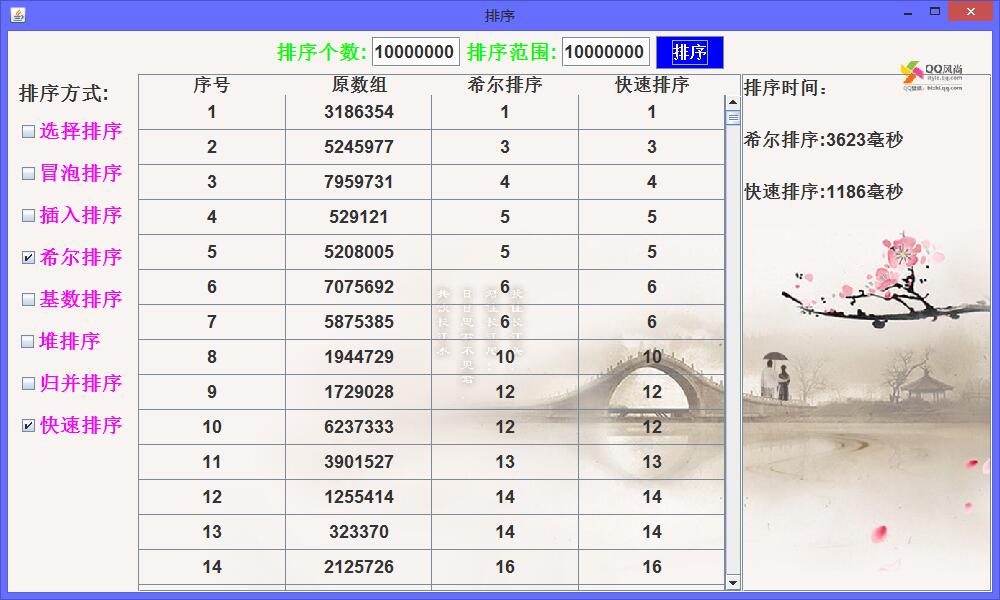
从以上的实际数据测试性能对比中可以看出,无论数据量大小是多少,快速排序所消耗的时间总是最小的,可以看得出快速排序的效率是很高的。















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









