







实验目的
1.能够清楚表述主要内部排序方法的设计思路。
2.能够用高级语言编写主要内部排序算法在计算机中的实现。
3.能够分析比较主要的内部排序方法之间的性能特点。
实验内容
编程实现统计直接插入排序、冒泡排序、简单选择排序、希尔排序、快速排序和归并排序算法在运行时的比较次数和移动次数。
实验要求
1.输入同样一组整型数据,作为待排序记录的关键字序列。
2.在进行直接插入排序、冒泡排序、简单选择排序的同时统计在排序过程中对关键字的比较次数和移动次数,并分别输出排序前的数据序列和排序后的数据序列及其统计结果。
3.在进行希尔排序、快速排序和归并排序的同时统计在排序过程中对关键字的比较次数和移动次数,并分别输出排序前的数据序列和排序后的数据序列及其统计结果。
4.在主程序中设计一个菜单,使用户可选择执行其中的任何一种或几种排序,并查看排序结果。
六种排序方法细解
直接插入排序


直接插入排序算法就是先将第一个元素认为有序,然后后面的元素与第一个有序元素比较,若比它小则插到前面,若大则位不置变,此时有序序列由一个元素扩充为两个,以此类推。
冒泡排序

每一趟排序都会将最大或最小的元素沉到底部或冒泡到顶部。以第一趟为例,43与21比较,43较大所以下沉,然后43与89比较,89较大所以位置不变,89再与15比较,89较大,所以89下沉,89再与28比较,89较大继续下沉,89再与43比较,89依然较大所以继续下沉,此时一轮结束找到最大的元素89.
简单选择排序



一第一趟为例,引入一个下标min,假设第一个元素最小,min=1,r[min]与r[2]~r[6]的所有元素逐一比较,发现最小的仍是r[1]则此时r[1]进入有序队列,然后将剩下的元素再进行选择排序。
希尔排序


希尔排序的特点是只跟距离为d的元素进行比较,如d=5时,59只跟23比较,发现23更小,则交换位置,48跟37比较,37较小所以交换位置,以此类推。
快速排序


先向前搜索,high所指的元素先于r[0]进行比较,发现并没有比r[0]小所以high往前移动。

high指向37发现比r[0]来的小,所以high所指的元素就移到low所指的位置。

此时向后搜索,low的位置往右移一位,指向r[2],此时r[2]接着与r[0]比较发现比r[0]小,low继续右移一位,指向r[3],r[3]比r[0]大所以r[3]的元素移到high所指的位置。





最终low=high这个位置就是59的最终位置。快速排序的特点就是每一轮会找到一个中间位置,当待排序序列基本有序时,快速排序就失效。
归并排序
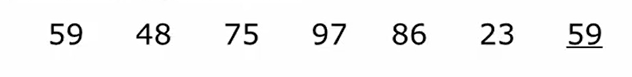

特点就是两两归并,先把每一个元素都看成一个只含有自身的有序队此时有七个,然后两两归并成为一个变成4个有序队,其中59因为第一趟时没有归并对象所以就继续自成一队,
然后四个有序队接着归并,变成两个有序队,最后变成一个有序队。
六种排序好坏分析

代码段
下面展示六个排序的代码段(内附比较次数和交换次数)。
#include <stdio.h>
#include <malloc.h>
#include <string.h>
#define TRUE 1
#define FALSE 0
#define MAXSIZE 80 //顺序表的最大长度
typedef int KeyType; // 将关键字类型定义为整型
typedef int InfoType; // 将其它数据项类型也定义为整型
typedef struct {
KeyType key; // 关键字项
InfoType otherinfo; // 其它数据项
} RedType; // 记录类型
typedef struct {
RedType r[MAXSIZE+1]; //一般情况将r[0]闲置
int length; // 顺序表长度
} SqList; //顺序表的类型
struct {
int cpn; //记录比较次数
int mvn; //记录移动次数
} cm[6]; //全局变量
void Sort_Insert(SqList &L)
//带监视哨的直接插入排序算法
{
int i,j;
for(i=2; i<=L.length; ++i)
if (cm[0].cpn++, L.r[i].key < L.r[i-1].key) { //比较关键字值时,比较次数加1
L.r[0]=L.r[i]; //将待插入的第i条记录暂存在r[0]中充当监视哨
cm[0].mvn++; //移动次数加1
for(j=i-1; j>0&&cm[0].cpn++,L.r[0].key<L.r[j].key; --j) { //在比较关键字值时,比较次数要加1
L.r[j+1]=L.r[j]; //后移
cm[0].mvn++; //移动次数加1
}
L.r[j+1]=L.r[0]; // 将L.r[i]插入到第j+1个位置
cm[0].mvn++; //移动次数加1
}//if
printf("比较次数为%d\n",cm[0].cpn);
printf("移动次数为%d\n",cm[0].mvn);
}
void Sort_Bubble(SqList &L)
//对顺序表L进行冒泡排序
{
int i,j,change;
RedType temp;
change=TRUE; //设置交换标志变量,初值为真
for (i=L.length; i>1&&change; --i) { //控制做n-1趟排序
change=FALSE; //每趟排序开始时设置交换标志变量值为假
for(j=1; j<i; ++j)
if (cm[1].cpn++,L.r[j].key>L.r[j+1].key) { //比较关键字值时,比较次数加1
temp=L.r[j]; //相邻的两个记录交换
L.r[j]=L.r[j+1];
L.r[j+1]=temp;
cm[1].mvn+=3; //移动次数加3
change=TRUE;
}//if
}// for i
printf("比较次数为%d\n",cm[1].cpn);
printf("移动次数为%d\n",cm[1].mvn);
}
void Sort_Select(SqList &L)
//对表L进行直接选择排序
{
for(int i=1; i<L.length; ++i) { //控制n-1趟排
int min=i; //假设无序子表中的第一条记录的关键字最小
for(int j=i+1; j<=L.length; ++j)
if (cm[2].cpn++,L.r[j].key<L.r[min].key)//比较关键字值时,比较次数加1
min=j;
if (min!=i) { //如果最小关键字记录不在无序子表的第一个位置,则交换
RedType temp=L.r[i]; //将最小关键字记录与无序子表中第一个记录交换
L.r[i]=L.r[min];
L.r[min]=temp;
cm[2].mvn+=3; //移动次数加3
}//if
} //for i
printf("比较次数为%d\n",cm[2].cpn);
printf("移动次数为%d\n",cm[2].mvn);
}
void bianli(SqList &L) {
printf("排序后所得序列为:\n");
for(int i=1; i<=L.length; i++) {
printf("%d ",L.r[i].key);
}
}
void Sort_Shell(SqList &L, int dk )
//对表L做一趟希尔排序,增量为dk
{
int i,j;
for(i=1+dk; i<=L.length; i++)
if (cm[3].cpn++,L.r[i].key < L.r[i-dk].key) { //将 L.r[i]插入有序增量子表
L.r[0]=L.r[i]; //将待插入的第i个记录暂存在r[0]中,同时r[0]为监视哨
cm[3].mvn++;
for(j=i-dk; j>0&&cm[3].cpn++,L.r[0].key<L.r[j].key; j-=dk) {
L.r[j+dk]=L.r[j]; // 将前面的较大者L.r[j+dk]后移
cm[3].mvn++;
}
L.r[j+dk]=L.r[0];
cm[3].mvn++; // 将L.r[i]插入第j+dk个位置
}
}
int Partition(SqList &L,int low,int high) { //对L中的子表L.r[low..high]做一趟快速排序
L.r[0]=L.r[low]; //将无序区低下标的记录设置为枢轴,并暂存在r[0]中
cm[4].mvn++;
KeyType privotkey=L.r[low].key;//将枢轴记录的关键字暂存在变量pivotkey中
while(low<high) { // 当low==high时,结束本趟排序
while(cm[4].cpn++,L.r[high].key>=privotkey&&low<high) //向前搜索
--high;
if(low<high) {
L.r[low++]=L.r[high]; //将比枢轴小的记录移至低端low的位置 ,然后low后移一位
cm[4].mvn++;
}
while(cm[4].cpn++,L.r[low].key<=privotkey&&low<high) //向后搜索
++low;
if (low<high) {
L.r[high--]=L.r[low]; //将比枢轴小的记录移至低端low的位置 ,然后high前移一位
cm[4].mvn++;
}
}
L.r[low]=L.r[0]; //枢轴记录移至最后位置
cm[4].mvn++;
return low; //返回枢轴所在的位置
}//算法7-5结束
void Q_Sort(SqList &L,int low,int high) { //对表r[low..high]采用递归形式的快速排序算法
if (low<high) { //如果无序表长大于1
int pivotloc=Partition(L,low,high);//完成一次划分,确定枢轴位置
Q_Sort(L,low,pivotloc-1); //递归调用,完成左子表的排序
Q_Sort(L,pivotloc+1,high); //递归调用,完成右子表的排序
}
}//算法7-6结束
void Sort_Quick(SqList &L) {
Q_Sort(L,1,L.length);
printf("比较次数为%d\n",cm[4].cpn);
printf("移动次数为%d\n",cm[4].mvn);
}//算法7-7结束
void Merge(RedType SR[],RedType TR[],int i,int m,int n)
//将两个相邻有序表SR[i .. m] 与SR[m+1.. n]归并为有序表TR[i .. n]
{
int j=m+1,k=i;
while(i<=m&&j<=n) { // 将SR中两个相邻有就有序子表由小到大并入TR中
if(cm[5].cpn++,SR[i].key<=SR[j].key)
TR[k++]=SR[i++];
else TR[k++]=SR[j++];
cm[5].mvn++;
}
while (i<=m) {
TR[k++]=SR[i++];//将前一有序子表的剩余部分复制到TR
cm[5].mvn++;
}
while (j<=n) {
TR[k++]=SR[j++];//将后一有序子表的剩余部分复制到TR
cm[5].mvn++;
}
}//算法7-10
void M_Sort(RedType SR[],RedType TR1[],int s,int t)
// 将SR[s..t]归并排序为TR[s..t]
{
RedType TR2[MAXSIZE+1];
if(s==t) TR1[s]=SR[s];
else {//待排序的记录序列只含一条记录
int m=(s+t)/2; // 以m为分界点,将无序表分成前、后两部分
M_Sort(SR,TR2,s,m);//对前部分递归归并为有序子表TR2[s..m]
M_Sort(SR,TR2,m+1,t);//对后部分递归归并为有序子表TR2[m+1..t]
Merge(TR2,TR1,s,m,t);//将TR2[s..m]与TR2[s..m]归并成有序表TR1[s..t]
}
}//算法7-11
void Sort_Merge(SqList &L) {
M_Sort(L.r,L.r,1,L.length);
printf("比较次数为%d\n",cm[5].cpn);
printf("移动次数为%d\n",cm[5].mvn);
}//算法7-12
int main() {
int i;
int x;
SqList L, L1; //L存储原始待排序的记录 ,L1存储排序后的记录
for (i=0; i<6; i++) { //比较和移动次数的计数变量赋初值0
cm[i].cpn=0;
cm[i].mvn=0;
}
printf("输入待排序的记录个数\n"); ///提示输入待排序的记录个数
scanf("%d",&L.length);
printf("输入待排序的记录的关键字序列\n"); //提示输入待排序记录的关键字序列
for(i=1; i<=L.length; i++)
scanf("%d",&L.r[i].key);
printf("please input the choose!(1-4):\n");
while(1) {
printf("//---------排序菜单-----------//\n");
printf("1.插入排序\n");
printf("2.冒泡排序\n");
printf("3.选择排序\n");
printf("4.希尔排序\n");
printf("5.快速排序\n");
printf("6.归并排序\n");
printf("7.退出\n") ;
printf("//---------排序菜单-----------//\n");
scanf("%d",&x);
switch(x) {
case 1:
L1=L;
Sort_Insert(L1);
bianli(L1);
break;
case 2:
L1=L;
Sort_Bubble(L1);
bianli(L1);
break;
case 3:
L1=L;
Sort_Select(L1);
bianli(L1);
break;
case 4:
L1=L;
int dk;
printf("请输入希尔排序增量dk值\n");
scanf("%d",&dk);
for(int k=dk; k>=1; k--) {
Sort_Shell (L1,k);
}
printf("比较次数为%d\n",cm[3].cpn);
printf("移动次数为%d\n",cm[3].mvn);
bianli(L1);
break;
case 5:
L1=L;
Sort_Quick(L1);
bianli(L1);
break;
case 6:
L1=L;
Sort_Merge(L1);
bianli(L1);
break;
case 7:
return 0;
default:
printf("ERROR!\n");
printf("请重新输入\n");
break;
}
printf("\n");
}
return 1;
}
运行结果




整理不易,希望对大家有帮助,别忘了收藏点赞加关注ˋ( ° ▽、° ) !!!















 6718
6718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









