






作者:WiseAgent 小而美智能体架构师
过去这一年,我见过太多死在 Demo 阶段的 Agent 项目。老板在会议室看 POC(概念验证)演示时,掌声雷动:Agent 能够流畅地查询数据库、写代码、甚至还能讲个笑话。大家觉得,“这事儿成了,下周上线。”
作为技术负责人,这时候我通常会泼一盆冷水:“现在的完成度只有 20%,剩下的 80% 是为了填补‘概率’与‘工程’之间的深渊。”
POC 和生产环境(Production)之间,隔着的不是几个 Prompt 的优化,而是从“概率性艺术”到“确定性工程”的范式转移。在我的工程实践中,我发现这个断层主要集中在三个维度:架构的解耦、边界的收敛、以及评估的量化。
断层一:架构的解耦——别把 GPT-4 当万能胶
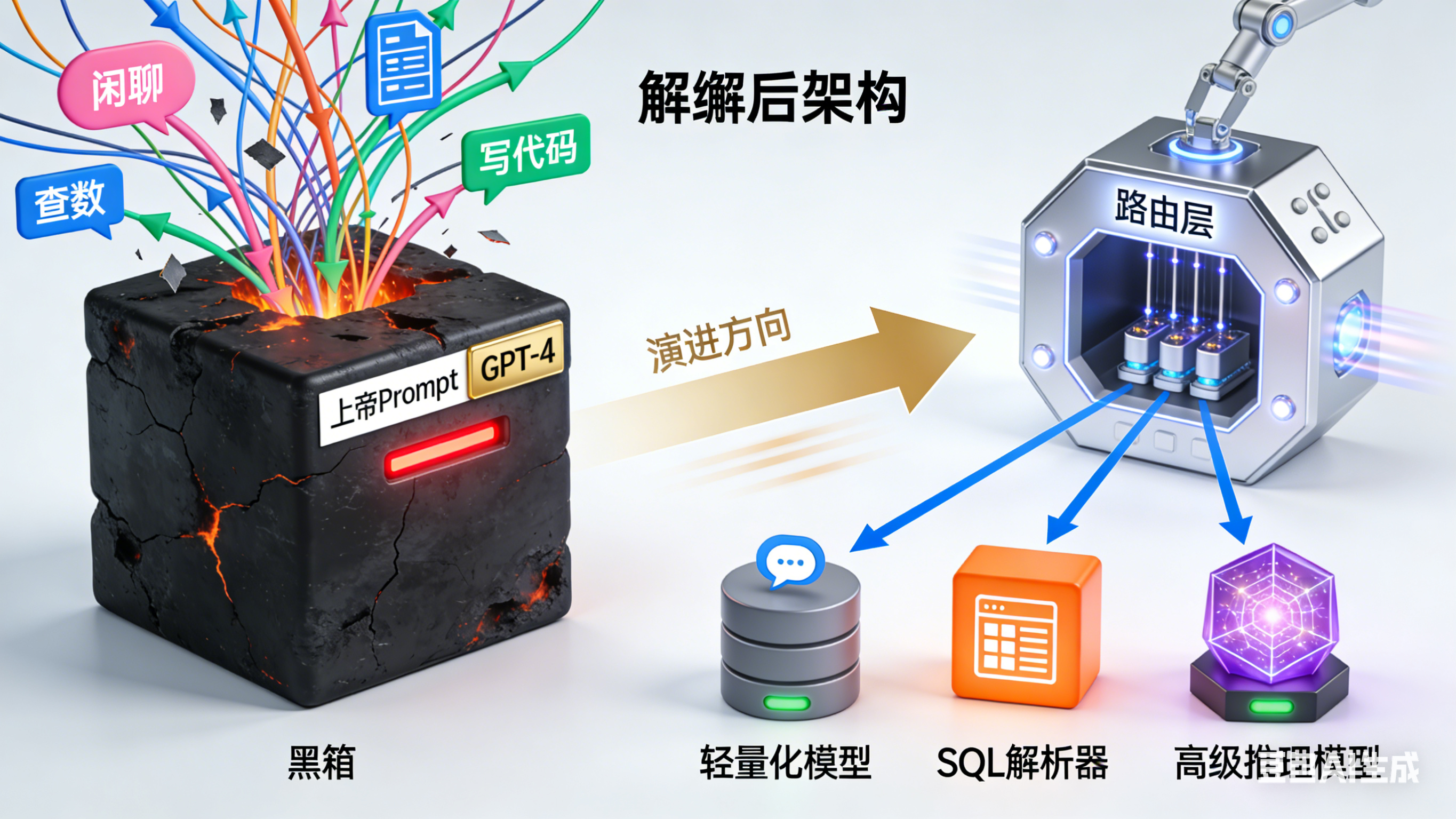
在 POC 阶段,为了快速出效果,最常见的做法是写一个几千字的“上帝 Prompt”(God Prompt),然后挂载十几个 Tools,直接扔给 GPT-4。
这种做法在生产环境是灾难性的。
-
成本与延迟的不可承受: 每次用户说个“你好”,你都要带着几千字的 System Prompt 去跑一遍 GPT-4。Token 费用在燃烧,用户在转圈等待。
-
注意力涣散: 当工具超过 5 个,或者 Prompt 超过一定长度,模型的指令遵循能力会非线性下降。它开始胡乱调用工具,或者忽略你的安全指令。
工程化解法:拆解与路由
上线前,我做的第一件事通常是**“把大模型拆小”**。
-
分层架构: 引入一个极轻量的 Router(路由)层。用户进来先用小模型(甚至关键词匹配)判断意图。是闲聊?是查数?还是写代码?
-
专人专事:
-
闲聊 -> 路由给 7B 参数的小模型或微调模型。
-
简单查询 -> 路由给专门的 SQL Agent。
-
复杂推理 -> 才舍得调用 GPT-4 或 Claude 3.5。
-
-
Prompt 模块化: 没有任何一个 Prompt 应该超过 1000 tokens。Agent 的记忆里只加载当前任务必须的上下文,而不是把祖宗十八代的聊天记录都塞进去。
一句话总结: POC 是用一个天才解决所有问题;生产环境是用一群流水线工人配合一个专家来解决问题。

断层二:边界的收敛——把 LLM 的输出视为“不可信输入”
POC 阶段,我们测试的是 Happy Path(快乐路径)。测试人员很配合,问的问题都很标准,Agent 表现得很完美。
生产环境,我们面对的是 Corner Case(极端情况)和恶意攻击。用户会输入乱码、会诱导攻击,或者 API 刚好超时了。这时候,完全依赖 LLM 自愈是不现实的。
最大的断层在于:开发者依然把 LLM 当作“函数”来用,默认它返回的一定是合法的 JSON。
工程化解法:防御性编程与强校验
在我的代码里,LLM 的输出地位等同于**“用户提交的表单”**——默认是脏的、不可信的。
-
结构化强校验: 不要只在 Prompt 里写“请返回 JSON”。必须在代码层用 Pydantic 或 Zod 做强类型校验。如果字段类型不对,直接抛错或触发重试,绝对不能透传给下游业务。
-
有限状态机(FSM)兜底: 我反复强调,Agent 的流程控制不能全靠 LLM 的“脑补”。
-
POC 做法: 让 LLM 决定下一步干嘛。
-
上线做法: 代码里写死状态机(State Machine)。如果当前是“支付中”,LLM 就算想去“查天气”,代码逻辑也要把它按住,强制它留在支付流程里。
-
-
熔断机制: 当 Agent 陷入死循环(比如反复调用同一个工具报错)时,必须有计数器强制熔断,转人工客服或返回标准错误提示。
一句话总结: 永远不要相信概率模型能 100% 遵守规则。用代码的硬逻辑(Hard Logic)去包裹模型的软逻辑(Soft Logic)。
断层三:评估的量化——告别“体感测试”
这是最隐蔽、也最致命的断层。在 POC 阶段,评估通常是“凭感觉”(Vibe Check)。开发者测了 10 个 Case,觉得“挺聪明”,就通过了。
当你为了修复 Case A 修改了 Prompt,结果导致 Case B、C、D 全部崩坏时,你就会意识到“回归测试”的重要性。没有自动化评估体系的 Agent 项目,上线就是裸奔。
工程化解法:构建黄金数据集与自动化 Eval
在我的团队,没有通过 Eval 跑分的 Prompt 变更,禁止上线。
-
建立黄金数据集(Golden Dataset): 收集 50-100 个真实的、覆盖各种边缘情况的“输入-输出”对。这是你的基准线。
-
自动化评分:
-
确定性指标: JSON 格式是否正确?工具调用参数是否准确?(用代码断言判断)。
-
语义性指标: 回答是否包含幻觉?语气是否得体?(用另一个高智商 LLM 作为 Judge 来打分)。
-
-
CI/CD 集成: 每次 Prompt 或代码提交,自动跑一遍测试集。如果准确率从 95% 掉到 90%,构建失败。
一句话总结: 软件工程里“无法度量就无法优化”的铁律,在 AI 时代依然有效。别相信你的直觉,相信数据。

尊重工程的复杂性
从 POC 到上线,本质上是一场“去魅”的过程。我们必须承认,目前的 LLM 依然是一个不稳定的推理引擎。Agent 工程化的核心,不是去追求模型有多聪明,而是通过架构设计、容错机制和评估体系,在一个不稳定的地基上,搭建出一座相对稳固的房子。
-
架构上,做减法,拆解巨型 Prompt。
-
流程上,做加法,引入状态机和强校验。
-
测试上,做乘法,用自动化矩阵覆盖人工盲区。
当你不再为 Agent 偶尔的一句“神回复”而沾沾自喜,开始为它如何处理一次“JSON 解析错误”而绞尽脑汁时,恭喜你,你终于跨过了那个断层,进入了真正的 Agent 工程化世界。

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









