







 本文介绍了在海外部署集群过程中使用Falcon遇到的问题及解决方案。通过引入nodata组件解决了监控机器宕机报警难题,并讨论了如何利用基础监控策略进行扩展,如增加机器宕机报警和Zookeeper监控。
本文介绍了在海外部署集群过程中使用Falcon遇到的问题及解决方案。通过引入nodata组件解决了监控机器宕机报警难题,并讨论了如何利用基础监控策略进行扩展,如增加机器宕机报警和Zookeeper监控。
前两天,我们在海外部署了一个集群,整体架构中包括了zk、mq、haproxy等一些列开源软件,我们的做法是每一类新建一个template,然后分别挂载不同的hosts,这样做起来比较清晰。
但是,今天我在学习nodata的时候,突然发现,falcon有一个硬伤,就是监控机器宕机有点困难,不过在nodata组件出现之后也就不那么难了。本质是,falcon的监控原理: 当有数值上报,而且数值上报与我设定的玉质相匹配之下,我才会做出报警的举动,如果连数据都没有进行上报,当然也就无法报警的说法了。
基于上述原理,我们是不是可以有这么一个假设,假设我有一个基础监控如下:

如果我们想增加机器宕机报警如何增加来,这个时候我们要用到nodata组件,
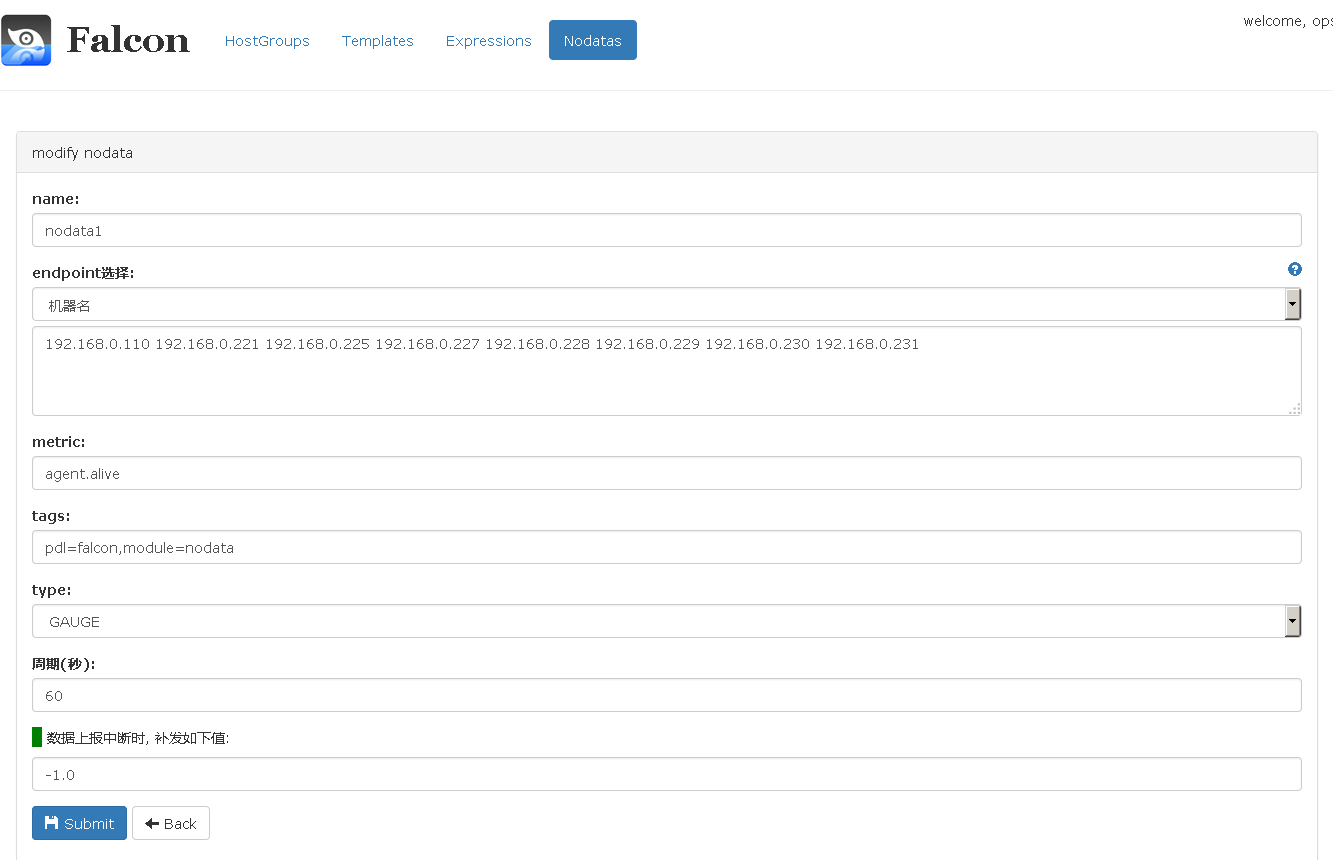
接下来,我们在报警模板中添加如下内容,这样当有机器宕机的时候,或者agent掉线的时候,我们就会有报警了。

如果我们再增加一个需求,监控zk怎么搞:
过去我们的做法是新建一个template策略模板(在闭着看来,策略模板和报警模板相似,读者不要迷糊哈),现在我们直接在基础监控里面加上就可以了,只要机器运行了zk,那么就会上报,上报就会有阈值进行judge;如果机器本身没有部署zk当然也就无从报警了。这么做看起来有点复杂,但是确实是可以工作的哦。
有一个例外,就是端口监控和cmdline监控,因为这个是需要被agent拿到client端运行的,如果我们写了3个端口放在基础监控里面,那么大家都会进行判断,噼里啪啦的报警也就来了,所以如果是端口监控,还是老老实实去配置单个的template吧。
不过写完之后,还是觉得,分开监控还是更加清晰一些,虽然有些麻烦。

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









