







1. 深度学习
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习典型应用为图像识别和语音识别。(由于本人不是深度学习专业人士,对深度学习理论知识不多介绍,说多了就班门弄斧了,后面主要介绍下这些深度学习算法如何进行并行化设计和优化)
2. CPU+GPU异构协同计算简介
近年来,计算机图形处理器(GPU,GraphicsProcess Unit)正在以大大超过摩尔定律的速度高速发展(大约每隔半年 GPU 的性能增加一倍),远远超过了CPU 的发展速度。
CPU+GPU异构协同计算模式(图1),利用CPU进行复杂逻辑和事务处理等串行计算,利用 GPU 完成大规模并行计算,即可以各尽其能,充分发挥计算系统的处理能力。
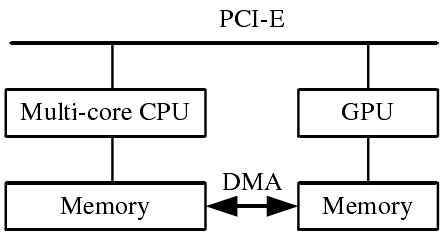
图1 CPU+GPU异构体系结构
目前,主流的GPU具有强大的计算能力和内存带宽,如图2所示,无论性能还是内存带宽,均远大于同代的CPU。对于GPU, Gflop/$和Gflops/w均高于CPU。

图2 GPU计算能力
3. 深度学习中的CPU+GPU集群架构
CPU+GPU集群工作模式(图3),每个节点内采用CPU+GPU异构模式,并且每个节点可以配置多块GPU卡。节点间采用高速InfiniBand网络互连,速度可以达到双向56Gb/s,实测双向5GB/s。后端采用并行文件系统。采用数据划分、任务划分的方式对应用进行并行化,适用于大规模数据并行计算。
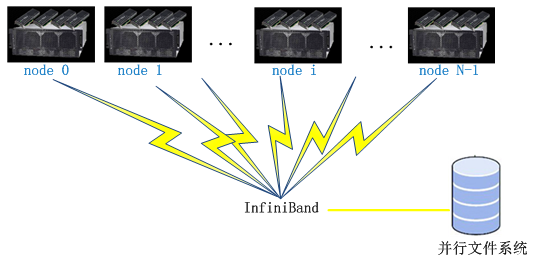
图3 CPU+GPU集群架构
4. 利用GPU加速深度学习算法
4.1. 单GPU并行
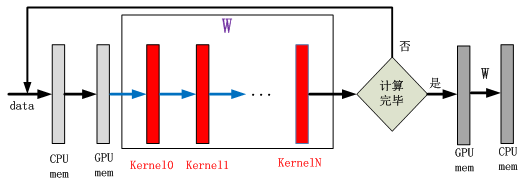
图4 单GPU计算流程
针对每次训练数据,模型内计算通过多次GPU 内核的调用完成计算。权重W值一直存在GPU内存中,直到所有训练数据计算完毕之后回传到系统内存中。Data为图像或语音数据。
4.2. 多GPU卡并行
多GPU并行计算时,各GPU有自己独立的内存,卡之间的并行属于分布式计算模式。针对深度学习算法,采用多GPU卡计算可以采用两种并行方法:数据并行和模型并行。
4.2.1. 数据并行
数据并行是指不同的GPU计算不同的训练数据,即把训练数据划分给不同的GPU进行分别计算,由于训练是逐步训练的,后一个训练数据的计算需要前一个训练数据更新的W,数据并行改变了这个计算顺序,多GPU计算需要进行W的互相通信,满足训练的特点,使训练可以收敛。
数据并行如图5所示,多GPU训练不同的数据,每训练一次需要同步W,使得后面的训练始终为最新的W。
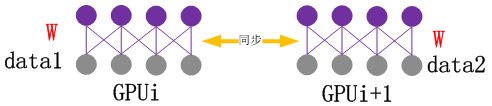
图5 数据并行
数据并行的特点:
1) 优点
a) 实现比较容易,也比较容易扩展
b) 只需要进行W的通信,模型内的数据不需要通信
2) 缺点
a) 当模型较大时,GPU内存无法满足存储要求,无法完成计算
根据多GPU卡之间的W通信,下面介绍两种通信方法:主从模式和令牌环模式。
1) 主从模式
主从模式:选择一个进程或线程作为主进程或线程,各个GPU把每次训练得到的ΔW发给主进程或线程,主进程或线程进行W更新,然后再发送给GPU,GPU再进行下一个数据的训练。如图6所示。
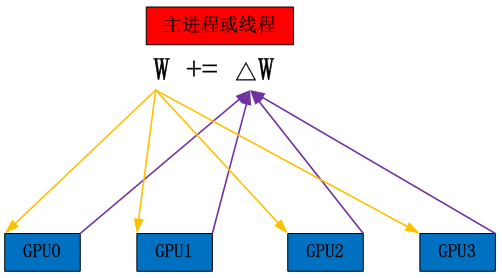
图6 主从模式
2) 令牌环模式
令牌环模式:每个GPU把自己训练得到的ΔW更新到W上,并且发送到下一个GPU,保证令牌环上的W始终为最新的W。如图7所示。
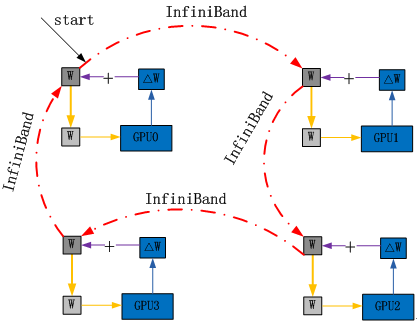
图7 令牌环模式
两种模式对比如表1
表1 主从模式和令牌环模式对比
| 模式 | 优点 | 缺点 |
| 主从模式 | 收敛速度更快 | GPU计算需要等待,影响GPU计算;主进程或线程压力较大 |
| 令牌环模式 | GPU计算不需要等待通信,性能更好 | 通信速度影响收敛的速度 |
4.2.2. 模型并行
模型并行是指多个GPU同时计算同一个训练数据,多个GPU对模型内的数据进行划分,如图8所示。Kernel计算和通信流程如图9所示,在一次训练数据多层计算过程中,每个GPU内核计算之后需要互相交换数据才能进行下一次的计算。
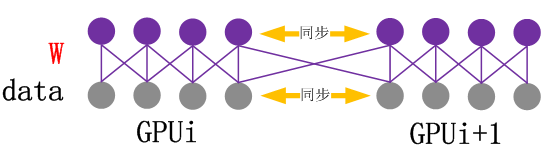
图8 模型并行
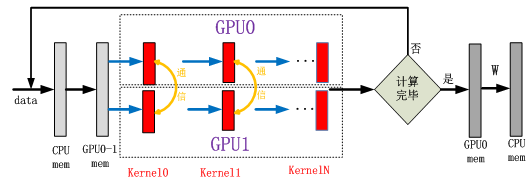
图9 模型并行:多GPU计算内核和通信示意图
模型并行特点:
1) 优点
a) 可以处理大模型的情况
2) 缺点
a) 需要更频繁的通信,增加通信压力
b) 实现难度较大
4.3. GPU集群并行
GPU集群并行模式即为多GPU并行中各种并行模式的扩展,如表2所示。节点间采用InfiniBand通信,节点间的GPU通过RMDA通信,节点内多GPU之间采用P2P通信。
表2 GPU集群并行模式
| 模式 | 节点间 | 节点内 | 特点 |
| 模式1 | 令牌环 | 单一模式的缺点放大 | |
| 模式2 | 主从 | ||
| 模式3 | 模型并行 | ||
| 模式4 | 令牌环 | 主从 | 结合各种模式的有点,避免某一模式的缺点放大 |
| 模式5 | 主从 | 令牌环 | |
| 模式6 | 令牌环 | 模型并行 | |
| 模式7 | 主从 | 模型并行 | |
4.4. 性能分享
4.4.1. 基于GPU集群的Caffe并行加速
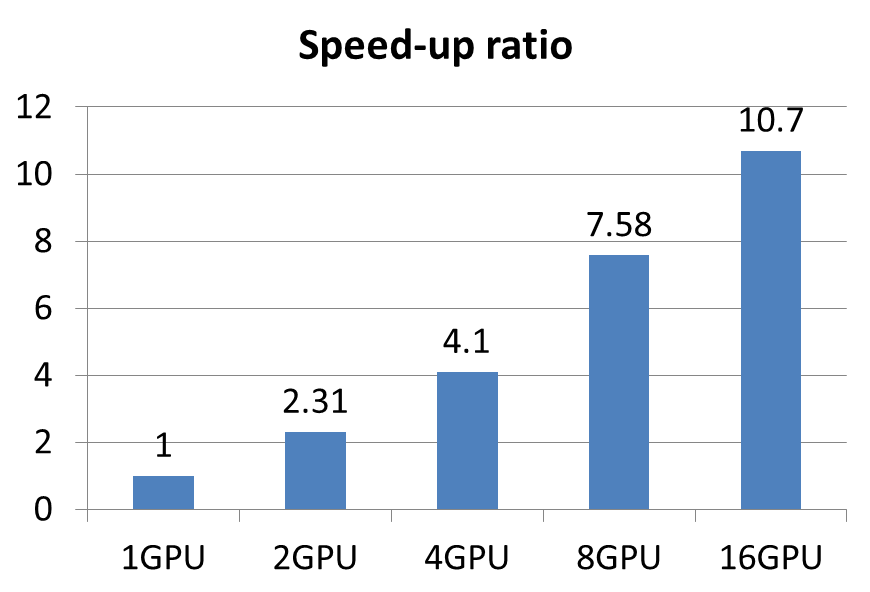
图10 Caffe性能
8节点GPU服务器,2 K20mGPU/节点,56Gb/s InfiniBand网络,Lustre并行文件系统
4.4.2. 基于GPU集群的DNN并行加速
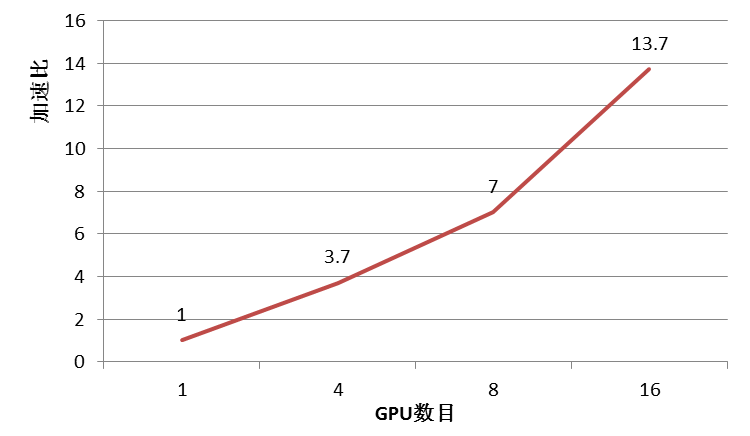
图11 DNN测试性能
4节点GPU服务器,4 K20mGPU/节点,56Gb/s InfiniBand网络
5. CPU+FPGA协同计算加速线上计算
相对于训练计算,线上识别的计算是小而众多的任务计算,每次请求的计算比较小,但请求的任务数十分庞大,GPU计算虽然获得很好的性能,但功耗仍然是个严峻的问题。
目前主流的FPGA卡功耗只有主流GPU的十分之一,性能相差2-3倍,FPGA相对于GPU具有更高的GFlops/W。
利用FPGA解决线上识别计算可以采用分布式+FPGA计算的模式,如图12所示,上层可以采用Hadoop或Spark调度,底层利用FPGA进行计算。
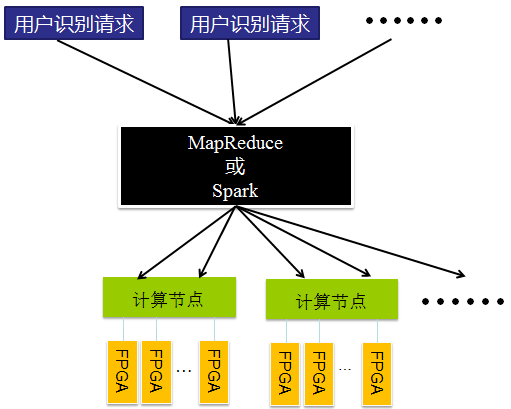
图12 分布式计算+FPGA计算
目前,FPGA已开始支持高级语言,如AlteraFPGA支持OpenCL,Xilinx FPGA支持HLS,这对程序员利用FPGA开发减低了难度。这些新平台的支持还有很多问题,也许后面会支持的越来越好。
备注:由于对深度学习算法了解比较肤浅,以上内容难免无误,请大家理解并提出修改意见。
QQ:331526010
Email:zhang03_11@163.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









