







网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,为客户提供稳定流畅、低时延、高并发的视频直播、录制、存储、转码及点播等音视频的PaaS服务。在线教育、远程医疗、娱乐秀场、在线金融等各行业及企业用户只需经过简单的开发即可打造在在线音视频平台。
LRUBlockCache
LRUBlockCache是HBase目前默认的BlockCache机制,实现机制比较简单。它使用一个ConcurrentHashMap管理BlockKey到Block的映射关系,缓存Block只需要将BlockKey和对应的Block放入该HashMap中,查询缓存就根据BlockKey从HashMap中获取即可。同时该方案采用严格的LRU淘汰算法,当Block Cache总量达到一定阈值之后就会启动淘汰机制,最近最少使用的Block会被置换出来。在具体的实现细节方面,需要关注三点:
1. 缓存分层策略
HBase在LRU缓存基础上,采用了缓存分层设计,将整个BlockCache分为三个部分:single-access、mutil-access和inMemory。需要特别注意的是,HBase系统元数据存放在InMemory区,因此设置数据属性InMemory = true需要非常谨慎,确保此列族数据量很小且访问频繁,否则有可能会将hbase.meta元数据挤出内存,严重影响所有业务性能。
2. LRU淘汰算法实现
系统在每次cache block时将BlockKey和Block放入HashMap后都会检查BlockCache总量是否达到阈值,如果达到阈值,就会唤醒淘汰线程对Map中的Block进行淘汰。系统设置三个MinMaxPriorityQueue队列,分别对应上述三个分层,每个队列中的元素按照最近最少被使用排列,系统会优先poll出最近最少使用的元素,将其对应的内存释放。可见,三个分层中的Block会分别执行LRU淘汰算法进行淘汰。
3. LRU方案优缺点
LRU方案使用JVM提供的HashMap管理缓存,简单有效。但随着数据从single-access区晋升到mutil-access区,基本就伴随着对应的内存对象从young区到old区,晋升到old区的Block被淘汰后会变为内存垃圾,最终由CMS回收掉(Conccurent Mark Sweep,一种标记清除算法),然而这种算法会带来大量的内存碎片,碎片空间一直累计就会产生臭名昭著的Full GC。尤其在大内存条件下,一次Full GC很可能会持续较长时间,甚至达到分钟级别。大家知道Full GC是会将整个进程暂停的(称为stop-the-wold暂停),因此长时间Full GC必然会极大影响业务的正常读写请求。也正因为这样的弊端,SlabCache方案和BucketCache方案才会横空出世。
BucketCache
相比LRUBlockCache,BucketCache实现相对比较复杂。它没有使用JVM 内存管理算法来管理缓存,而是自己对内存进行管理,因此不会因为出现大量碎片导致Full GC的情况发生。本节主要介绍BucketCache的具体实现方式(包括BucketCache的内存组织形式、缓存写入读取流程等)以及如何配置使用BucketCache。
内存组织形式
下图是BucketCache的内存组织形式图,其中上面部分是逻辑组织结构,下面部分是对应的物理组织结构。HBase启动之后会在内存中申请大量的bucket,如下图中黄色矩形所示,每个bucket的大小默认都为2MB。每个bucket会有一个baseoffset变量和一个size标签,其中baseoffset变量表示这个bucket在实际物理空间中的起始地址,因此block的物理地址就可以通过baseoffset和该block在bucket的偏移量唯一确定;而size标签表示这个bucket可以存放的block块的大小,比如图中左侧bucket的size标签为65KB,表示可以存放64KB的block,右侧bucket的size标签为129KB,表示可以存放128KB的block。
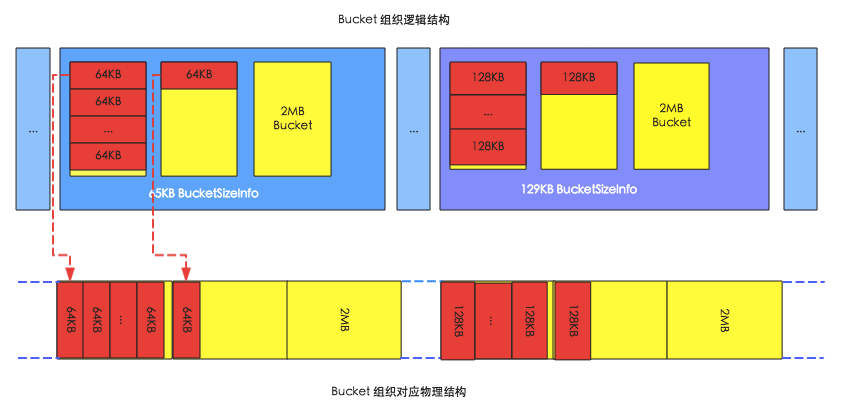
HBase中使用BucketAllocator类实现对Bucket的组织管理:
1. HBase会根据每个bucket的size标签对bucket进行分类,相同size标签的bucket由同一个BucketSizeInfo管理,如上图,左侧存放64KB block的bucket由65KB BucketSizeInfo管理,右侧存放128KB block的bucket由129KB BucketSizeInfo管理。
2. HBase在启动的时候就决定了size标签的分类,默认标签有(4+1)K、(8+1)K、(16+1)K … (48+1)K、(56+1)K、(64+1)K、(96+1)K … (512+1)K。而且系统会首先从小到大遍历一次所有size标签,为每种size标签分配一个bucket,最后所有剩余的bucket都分配最大的size标签,默认分配(512+1)K,如下图所示:
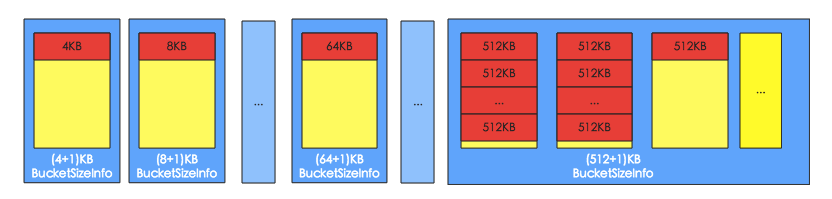
3. Bucket的size标签可以动态调整,比如64K的block数目比较多,65K的bucket被用完了以后,其他size标签的完全空闲的bucket可以转换成为65K的bucket,但是至少保留一个该size的bucket。
Block缓存写入、读取流程
下图是block写入缓存以及从缓存中读取block的流程示意图,图中主要包括5个模块,其中RAMCache是一个存储blockkey和block对应关系的HashMap;WriteThead是整个block写入的中心枢纽,主要负责异步的写入block到内存空间;BucketAllocator在上一节详细介绍过,主要实现对bucket的组织管理,为block分配内存空间;IOEngine是具体的内存管理模块,主要实现将block数据写入对应地址的内存空间;BackingMap也是一个HashMap,用来存储blockKey与对应物理内存偏移量的映射关系,用来根据blockkey定位具体的block;其中紫线表示cache block流程,绿线表示get block流程。
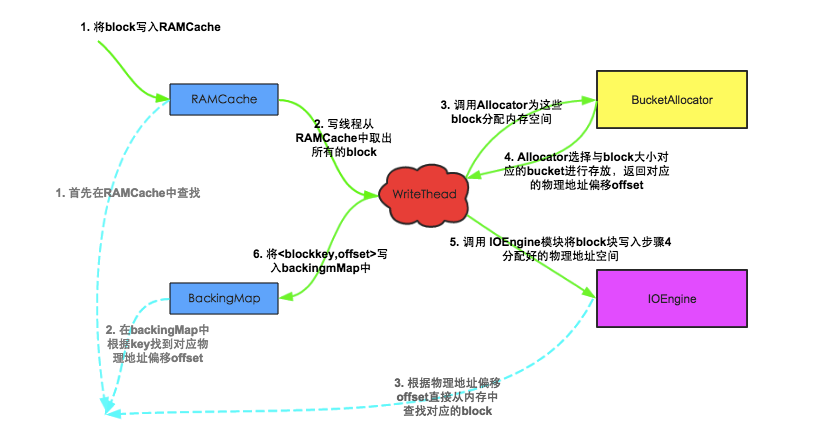
Block缓存写入流程
1. 将block写入RAMCache。实际实现中,HBase设置了多个RAMCache,系统首先会根据blockkey进行hash,根据hash结果将block分配到对应的RAMCache中;
2. WriteThead从RAMCache中取出所有的block。和RAMCache相同,HBase会同时启动多个WriteThead并发的执行异步写入,每个WriteThead对应一个RAMCache;
3. 每个WriteThead会将遍历RAMCache中所有block数据,分别调用bucketAllocator为这些block分配内存空间;
4. BucketAllocator会选择与block大小对应的bucket进行存放(具体细节可以参考上节‘内存组织形式’所述),并且返回对应的物理地址偏移量offset;
5. WriteThead将block以及分配好的物理地址偏移量传给IOEngine模块,执行具体的内存写入操作;
6. 写入成功后,将类似<blockkey,offset>这样的映射关系写入BackingMap中,方便后续查找时根据blockkey可以直接定位;
Block缓存读取流程
1. 首先从RAMCache中查找。对于还没有来得及写入到bucket的缓存block,一定存储在RAMCache中;
2. 如果在RAMCache中没有找到,再在BackingMap中根据blockKey找到对应物理偏移地址offset;
3. 根据物理偏移地址offset可以直接从内存中查找对应的block数据;
BucketCache工作模式
BucketCache默认有三种工作模式:heap、offheap和file;这三种工作模式在内存逻辑组织形式以及缓存流程上都是相同的,参见上节讲解。不同的是三者对应的最终存储介质有所不同,即上述所讲的IOEngine有所不同。
其中heap模式和offheap模式都使用内存作为最终存储介质,内存分配查询也都使用Java NIO ByteBuffer技术,不同的是,heap模式分配内存会调用byteBuffer.allocate方法,从JVM提供的heap区分配,而后者会调用byteBuffer.allocateDirect方法,直接从操作系统分配。这两种内存分配模式会对HBase实际工作性能产生一定的影响。影响最大的无疑是GC ,相比heap模式,offheap模式因为内存属于操作系统,所以基本不会产生CMS GC,也就在任何情况下都不会因为内存碎片导致触发Full GC。除此之外,在内存分配以及读取方面,两者性能也有不同,比如,内存分配时heap模式需要首先从操作系统分配内存再拷贝到JVM heap,相比offheap直接从操作系统分配内存更耗时;但是反过来,读取缓存时heap模式可以从JVM heap中直接读取,而offheap模式则需要首先从操作系统拷贝到JVM heap再读取,显得后者更费时。
file模式和前面两者不同,它使用Fussion-IO或者SSD等作为存储介质,相比昂贵的内存,这样可以提供更大的存储容量,因此可以极大地提升缓存命中率。
BucketCache配置使用
BucketCache方案的配置说明一直被HBaser所诟病,官方一直没有相关文档对此进行介绍。本人也是一直被其所困,后来通过查看源码才基本了解清楚,在此分享出来,以便大家学习。需要注意的是,BucketCache三种工作模式的配置会有所不同,下面也是分开介绍,并且没有列出很多不重要的参数:
heap模式
<hbase.bucketcache.ioengine>heap</hbase.bucketcache.ioengine>
//bucketcache占用整个jvm内存大小的比例
<hbase.bucketcache.size>0.4</hbase.bucketcache.size>
//bucketcache在combinedcache中的占比
<hbase.bucketcache.combinedcache.percentage>0.9</hbase.bucketcache.combinedcache.percentage>
offheap模式
<hbase.bucketcache.ioengine>offheap</hbase.bucketcache.ioengine>
<hbase.bucketcache.size>0.4</hbase.bucketcache.size>
<hbase.bucketcache.combinedcache.percentage>0.9</hbase.bucketcache.combinedcache.percentage>
file模式
<hbase.bucketcache.ioengine>file:/cache_path</hbase.bucketcache.ioengine>
//bucketcache缓存空间大小,单位为MB
<hbase.bucketcache.size>10 * 1024</hbase.bucketcache.size>
//高速缓存路径
<hbase.bucketcache.persistent.path>file:/cache_path</hbase.bucketcache.persistent.path>
总结
HBase中缓存的设置对随机读写性能至关重要,本文通过对LRUBlockCache和BucketCache两种方案的实现进行介绍,希望能够让各位看官更加深入地了解BlockCache的工作原理。BlockCache系列经过两篇内容的介绍,基本已经解析完毕,那在实际线上应用中到底应该选择哪种方案呢?下一篇文章让我们一起看看HBase社区发布BlockCache报告!
更多技术分享,请关注网易视频云官方网站或者网易视频云官方微信(vcloud163)进行交流与咨询














 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









