







这里写自定义目录标题
下载Jupyter Notebook
conda install jupyter notebook
遇到第一个问题
出错UnavailableInvalidChannel: The channel is not accessible or is invalid
据说是镜像问题
然后解决方法也是百度
首先用conda config --show channels
命令看一下都有什么镜像
然后使用conda config --remove-key channels
命令恢复默认配置
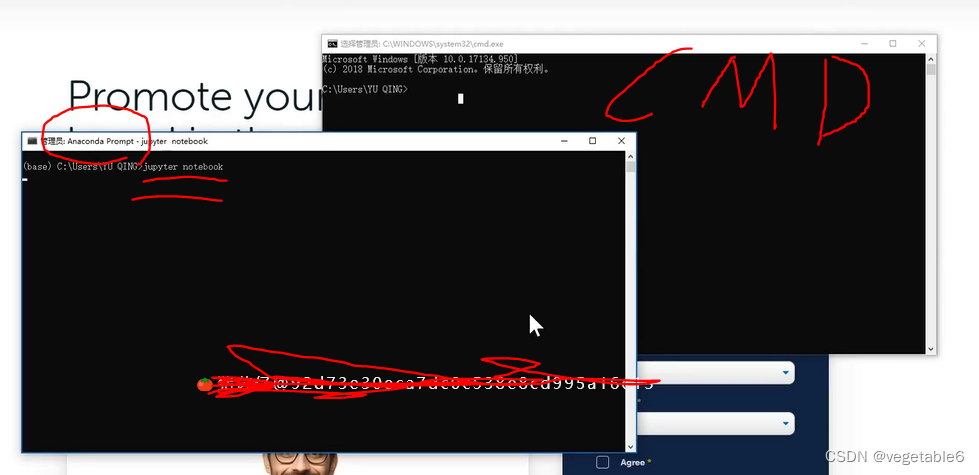
2.打开cmd,然后输入pip install jupyter
还是不行
导入数据
conda常用的命令。
1 ) conda list确认安装了哪个软件包。
2 ) conda env list或conda info -e确认当前存在什么虚拟环境
3 ) conda update conda检查更新当前conda
4.进入那个环境conda activate +,,,,
下载数据
https://www.kaggle.com/c/titanic/overview
导入数据
import numpy as np
import panda as pd
import os
2.
相对路径
df=pd.read_csv(‘train.csv’)
这时候的数据类型是dataframe
可以用head
规格
df.shape
转置
df.T
十分钟入门panda
https://ericfu.me/10-minutes-to-pandas/
找到绝对路径
Path=os.path.abspath(‘train.csv’)
df=pd.read_csv(path)默认制表符为逗号
Read_table是以制表符\t作为数据的标志
df=pd.read_table (path,sep=’,’)两个结果就是一样的了
3.逐块读取
df=pd.read_csv(‘train.csv’,chunksize=1000)
结果不显示
这时候的数据类型是textfilereader,适用于迭代的object
不能用head
所以可以使用
df.get_chunk()
4.修改Dataframe列名的两种方法
df.columns=[‘乘客ID’,‘B’,‘C’]
这样套上去
表头直接被替换掉了
PassengerId => 乘客ID
Survived => 是否幸存
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
或者是
df=pd.read_csv(‘train.csv’,names=[‘A’,‘B’,‘C’])
直接重命名,这个改掉之后表头没有被替换而是变成了下一行
1.2最后查看数据的基本信息
参考
df.info(): # 打印摘要
df.describe(): # 描述性统计信息
df.values: # 数据
df.to_numpy() # 数据 (推荐)
df.shape: # 形状 (行数, 列数)
df.columns: # 列标签
df.columns.values: # 列标签
df.index: # 行标签
df.index.values: # 行标签
df.head(n): # 前n行
df.tail(n): # 尾n行
pd.options.display.max_columns=n: # 最多显示n列
pd.options.display.max_rows=n: # 最多显示n行
df.memory_usage(): # 占用内存(字节B)
————————————————
原文链接:https://blog.csdn.net/qq_37975685/article/details/107953941
判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull()
1.3保存数据
df.to_csv(‘train_chinese.csv’)















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









