








接上文 : web自动化测试系列-selenium css_selector定位方法详解(七)-CSDN博客
前面已经介绍了8种定位方法 ,大多数情况下我们都会优先使用这8种方法 。
但有的时候在你选择定位元素时 ,会出现多个同样的定位属性和值 。而且你能选择定位也就这一种情况 。这种情况你只能使用它来进行定位 。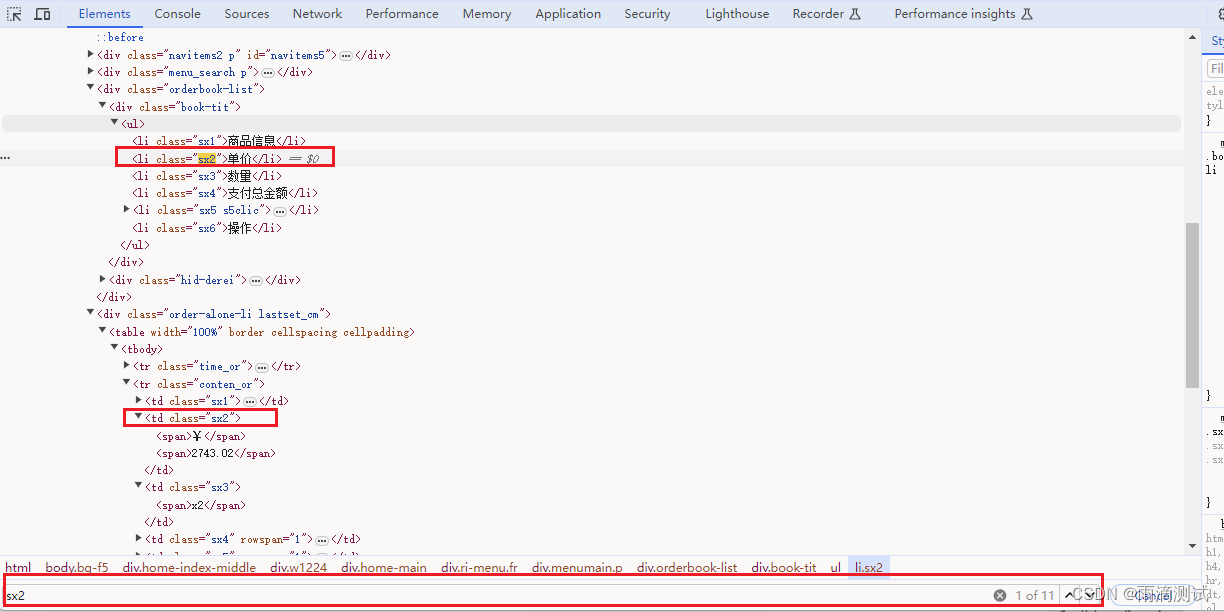
图中的这个元素只能使用class='sx2'定位 ,但是使用它来定位的话,就会出现定位到多个值的情况 。怎么办呢 ?
selenium提供了8种定位这种重复值的方法 。
1.find_elements的八种定位方法
谈到这8种方法 ,你就不得不了解前面的八种方法 ,通过对比我们可以看出它们的不同 。

总结以上方法,有以下3点需要注意 :
-
用法上和find_elment完全相同 ,虽然方法名有所不同 ,但用法上和find_element对应方法完全相同 ,可随意切换 。
-
定位后返回列表 :使用find_elements系列的方法定位 , 一般会返回多个元素 。而将这些元素都放在一个列表中 。所以 ,当获取其中的某一个元素时 ,就必须使用列表中的索引来获取 :list[index] .
-
它的使用场景:正常情况下 ,能使用find_element定位到的 ,就不会使用find_elements方法 ,它只是在find_element系列方法定位不到的情况下才会考虑使用 。
2.具体案例
需求:通过selenium完成对tpshop的登录操作,具体如下 :
-
进入首页,点击登录按钮 ,进入到登录页面
-
使用find_elements系方法定位用户名输入框,并输入账号,如13988888888
-
使用find_elements系方法定位确认密码输入框,并输入123456 。
-
使用find_elements系方法定位验证码输入框,并输入8888
-
点击登录按钮 ,进入我的账户页面 。
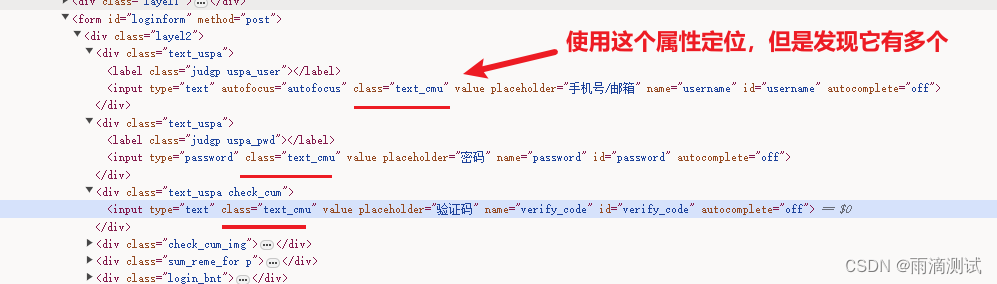
# 使用find_elements定位 ,返回的都是多个值,存放在列表汇中
from selenium import webdriver
import time
# 1. 创建浏览器对象
driver = webdriver.Chrome()
driver.maximize_window()
# 2. 输入地址 :http://localhost
driver.get("http://localhost")
driver.find_element_by_link_text("登录").click()
time.sleep(3)
# 通过class属性获取到多个元素,这里的elem_lst是一个列表 ,列表中放了三个元素,分别为用户名、密码、验证码
elem_lst = driver.find_elements_by_class_name("text_cmu")
print("元素集:{}".format(elem_lst))
# 输入用户名 :从列表中取第一个元素
elem_lst[0].send_keys("13988888888")
# 输入密码 :从列表中取第二个元素
elem_lst[1].send_keys("123456")
# 输入验证码 :从列表中取第三个元素
elem_lst[2].send_keys("8888")
driver.find_element_by_class_name("J-login-submit").click()














 2010
2010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









