






| 一、实验目的 |
| 通过实现LSTM模型对MNIST数据集进行分类,掌握使用PyTorch进行深度学习任务的基本流程和操作。 |
| 二.实验环境 |
|
| 三、实验内容与步骤 1.导入所需的库和模块: 2.定义LSTM模型 3.加载MNIST数据集: 4.定义训练函数和测试函数: 5.定义模型、优化器和损失函数,并进行模型训练和测试: |
| 四、实验过程与分析
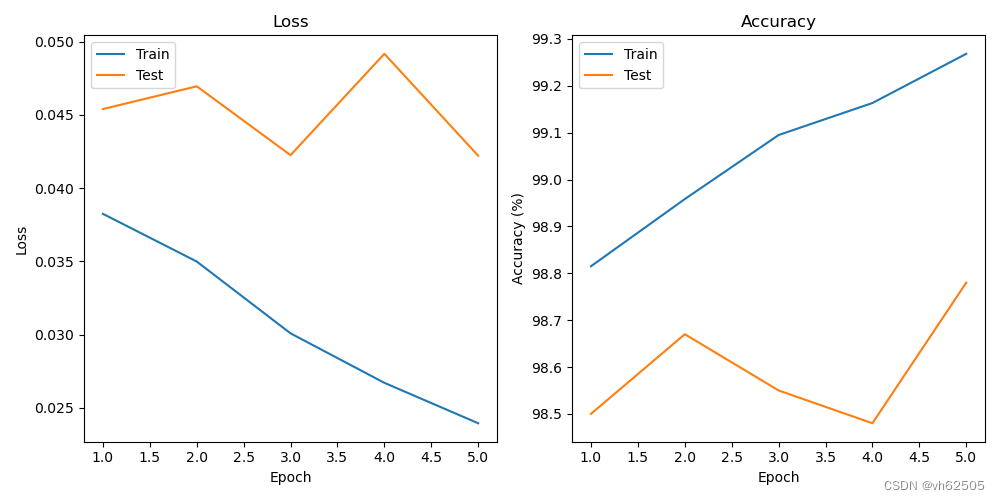
Loss-Acc 图:
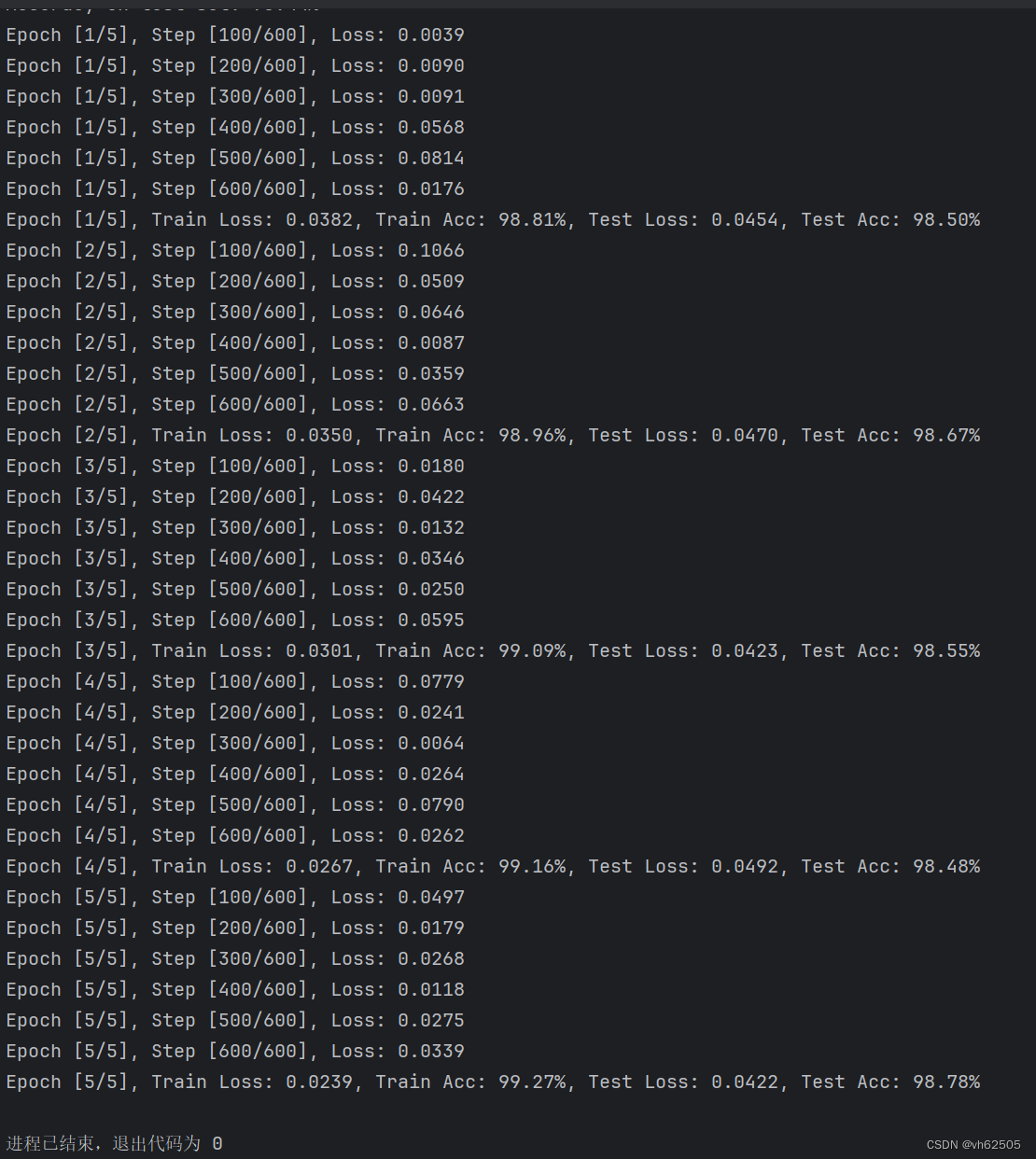
运行结果:
|
| 五、实验总结 本实验通过利用LSTM模型对MNIST数据集进行分类,使用PyTorch完成了模型的构建、数据加载、训练和测试等步骤。实验结果表明,LSTM模型在MNIST数据集上能够取得良好的分类效果。通过本实验,您深入了解了PyTorch框架的基本操作和流程,以及LSTM模型在序列数据上的应用。此外,您还可以进一步优化模型和调整超参数,以获得更好的性能和准确率。 在LSTM中提高准确率,可以考虑以下几个方面的改进: 1.增加LSTM层的数量:通过增加LSTM层的数量,可以增加模型的复杂度和表达能力。尝试添加更多的LSTM层,但要注意避免过拟合。 2.调整隐藏状态维度:LSTM的隐藏状态维度对模型的表达能力有重要影响。尝试增加隐藏状态维度,使其能够更好地捕捉输入序列的特征。 3.使用双向LSTM:双向LSTM可以同时考虑前向和后向的上下文信息,有助于提高模型的准确率。将LSTM层设置为双向模式。 4.添加正则化技术:正则化技术可以减少过拟合,提高模型的泛化能力。尝试添加L2正则化、Dropout或Batch Normalization等正则化技术。 5.调整学习率和优化算法:学习率和优化算法对模型的训练和收敛速度有重要影响。尝试不同的学习率和优化算法,找到一个合适的组合。 6.增加训练数据量或进行数据增强:增加训练数据量可以提高模型的泛化能力。如果可行,尝试收集更多的训练数据。另外,可以使用数据增强技术生成更多的训练样本。 |















03-29
 5791
5791
5791
12-29
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









