







一 写在前面
由于科研需要,最近在学习循环神经网络(RNN)和LSTM算法,学完LSTM就写了个程序,顺带练练手。之前在看文献的时候看到别人的论文中提到使用深度神经网咯LSTM进行驾驶分心(这是我目前主要研究的内容)的识别,但是根据我的了解得知,LSTM对于处理序列问题比较有优势,对于我这个研究课题我还不知道是不是序列问题(刚刚接触,小白一个),这个我以后在仔细研究以下,有知道的同学可以共同探讨下。然后,反正都是分类问题,我就是用CIFAR10数据集进行了测试,结果……
二 算法实现
2.1 模型搭建
class Lstm(nn.Module):
def __init__(self) -> None:
super(Lstm,self).__init__()
self.lstm=nn.LSTM(32*3,128,batch_first=True,num_layers=5)
self.line1=nn.Linear(128,128)
self.line2=nn.Linear(128,10)
def forward(self,x):
out,(h_n,c_n)=self.lstm(x)
out=self.line1(out[:,-1,:])
out=self.line2(out)
return out2.2 数据加载
transform=transforms.Compose([transforms.RandomCrop(32,padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])]) #数据增强(实验结果表明,加入数据增强对于测试集准确率有较小的提升)
#数据加载
trian_set=datasets.CIFAR10(root='./data',train=True,download=False,transform=transform)
train_loader=DataLoader(trian_set,batch_size=batch_size,shuffle=True)
test_set=datasets.CIFAR10(root='./data',train=False,transform=transform,download=False)
test_loader=DataLoader(test_set,batch_size=batch_size,shuffle=True)
2.3 训练模型
device=torch.device('cuda')
#将下面内容放到GPU上进行训练
model=Lstm().to(device)
criteon=nn.CrossEntropyLoss().to(device)
optimizer=optim.Adam(model.parameters(),lr=LR)
for epoch in range(EPOCH):
for step,(data,label) in enumerate(train_loader):
data,label=data.to(device),label.to(device)
data=data.view(-1,32,32*3)
out=model(data)
loss=criteon(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("eopch: ",epoch,"Loss: ",loss.item())
if epoch %1 == 0:
test_acc=evaluate(model,test_loader)
print("Accuracy: ",test_acc)
print("-"*30)
if test_acc>best_acc:
best_acc=test_acc
best_epoch=epoch
torch.save(model.state_dict(),"Best_CIFAR10.mdl") #保存最好的模型
print("Best Epoch: ",best_epoch)
print("Best Accuracy: ",best_acc)三 完整代码
from optparse import Option
from turtle import forward
from matplotlib import transforms
from matplotlib.pyplot import title
import torch
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision import transforms
import torch.nn as nn
from torch.autograd import Variable
from torch import no_grad, optim
import visdom
class Lstm(nn.Module):
def __init__(self) -> None:
super(Lstm,self).__init__()
self.lstm=nn.LSTM(32*3,128,batch_first=True,num_layers=5)
self.line1=nn.Linear(128,128)
self.line2=nn.Linear(128,10)
def forward(self,x):
out,(h_n,c_n)=self.lstm(x)
out=self.line1(out[:,-1,:])
out=self.line2(out)
return out
#全局变量设置
batch_size=500
EPOCH=15
LR=1e-3
device=torch.device('cuda')
def evaluate(model,test_loader):
total_correct=0
total_num=0
for step,(data,label) in enumerate(test_loader):
data,label=data.to(device),label.to(device)
data=data.view(-1,32,32*3)
out=model(data)
pred=out.argmax(dim=1)
total_correct +=torch.eq(pred,label).float().sum().item()
total_num += data.size(dim=0)
acc=total_correct/total_num
return acc
viz=visdom.Visdom() #训练可视化
def main():
transform=transforms.Compose([transforms.RandomCrop(32,padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])])
model=Lstm().to(device)
criteon=nn.CrossEntropyLoss().to(device)
optimizer=optim.Adam(model.parameters(),lr=LR)
#数据加载
trian_set=datasets.CIFAR10(root='./data',train=True,download=False,transform=transform)
train_loader=DataLoader(trian_set,batch_size=batch_size,shuffle=True)
test_set=datasets.CIFAR10(root='./data',train=False,transform=transform,download=False)
test_loader=DataLoader(test_set,batch_size=batch_size,shuffle=True)
best_epoch,best_acc=0,0
global_step=0
viz.line([0],[-1],win='loss',opts=dict(title="Loss"))
viz.line([0],[-1],win='Test_acc',opts=dict(title="Test_acc"))
#训练数据集
for epoch in range(EPOCH):
for step,(data,label) in enumerate(train_loader):
data,label=data.to(device),label.to(device)
data=data.view(-1,32,32*3)
out=model(data)
loss=criteon(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()],[global_step],win="loss",update='append')
global_step +=1
print("eopch: ",epoch,"Loss: ",loss.item())
if epoch %1 == 0:
test_acc=evaluate(model,test_loader)
print("Accuracy: ",test_acc)
print("-"*30)
if test_acc>best_acc:
best_acc=test_acc
best_epoch=epoch
torch.save(model.state_dict(),"Best_CIFAR10.mdl")
viz.line([test_acc],[global_step],win='Test_acc',update='append')
print("Best Epoch: ",best_epoch)
print("Best Accuracy: ",best_acc)
if __name__=='__main__':
main()结果:
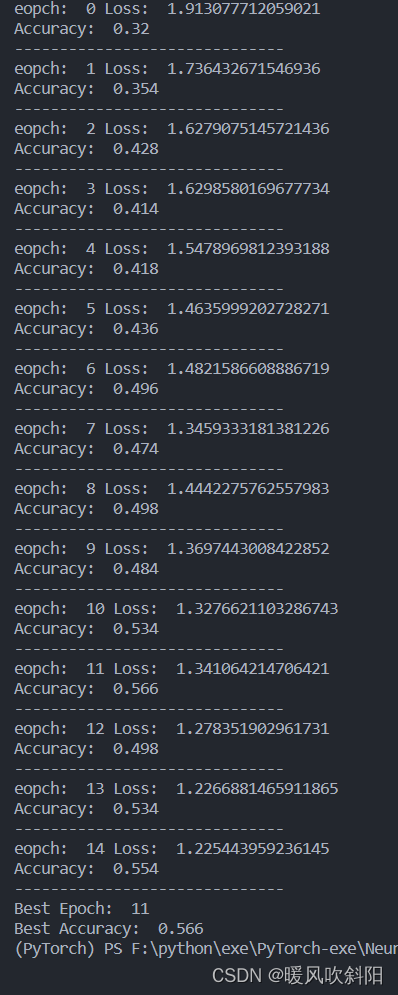

发现LSTM对于CIFAR10数据集的训练结果并不理想,问同学他说LSTM不擅长处理图片分类的问题。希望大神指点迷津……















 6523
6523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









