






实验一 迁移学习
一、实验目的
- 掌握python编程语言
- 熟悉 pytorch深度学习框架
- 掌握卷积神经网络的原理
- 掌握卷积神经网络用于图像分类问题的解决方案
二、实验内容
1.在小型数据集上从头开始训练一个卷积神经网络实现猫狗分类
2. 采用使用数据增强的方法提高其准确率
3.使用预训练的卷积神经网络并采用数据增强
4. 微调模型并采用数据增强
三、实验环境
Python + pytorch
四、P实验要求
1. img_size=(32, 32, 3)
2. 小数据集下测试
3. 预训练中可以选择任何典型的卷积神经网络
4. 微调时,写清楚微调的层
五、实验过程与总结
1.对于在小型数据集上从头开始训练一个卷积神经网络(CNN)实现猫狗分类的任务,可以按照以下步骤进行:
数据准备:
-
- 收集包含猫和狗图像的小型数据集作为训练和验证集。确保每个类别都有足够数量的图像。
- 对图像进行预处理,例如调整大小、裁剪或旋转以增加数据集的多样性。
- 将标签进行二值化编码,将猫标记为1,将狗标记为0。
构建 CNN 模型:
-
- 导入所需的深度学习库,如TensorFlow或PyTorch。
- 定义CNN模型的结构,包括卷积层、池化层、全连接层等。
- 根据任务需求选择合适的网络深度和层数。
定义损失函数和优化器:
-
- 选择适当的损失函数,如交叉熵损失函数。
- 使用随机梯度下降(SGD)或其他优化算法来更新模型的参数。
模型训练:
-
- 将数据集划分为训练集和验证集。
- 迭代训练模型,使用训练集上的数据进行前向传播和反向传播,并计算损失。
- 使用优化器根据计算出的损失来更新模型的参数。
- 在验证集上评估模型的性能,并根据需要进行调整。
模型评估和调优:
-
- 使用测试集评估经过训练的模型的性能。
- 根据评估结果对模型进行调整和改进,例如调整超参数、增加正则化项等。
最终模型部署:
-
- 将训练好的模型保存到文件或部署到服务器上,以便在实际应用中使用。
- 准备好输入数据,并将其传递给模型进行预测,获取猫狗分类的结果。
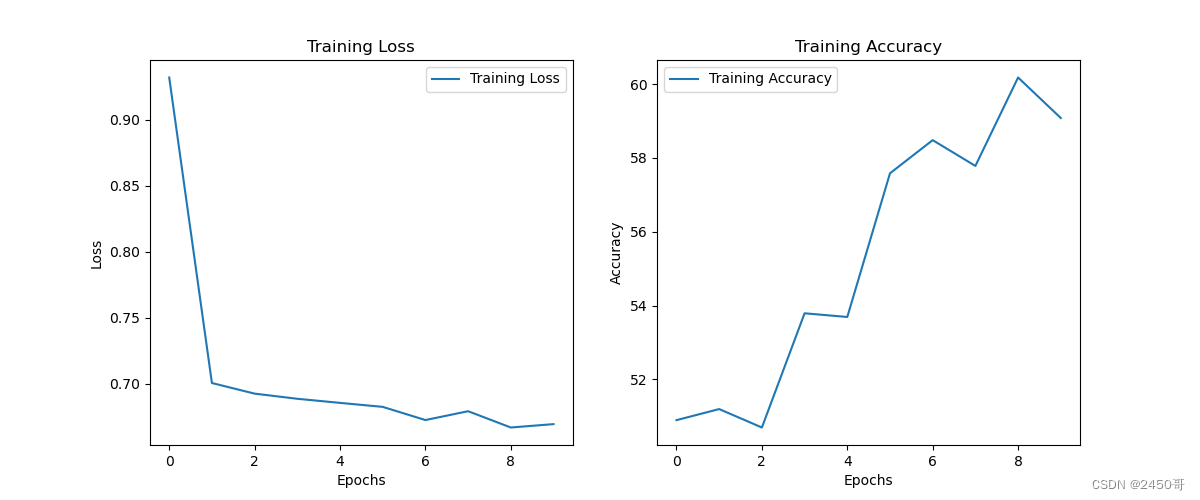
运行结果:
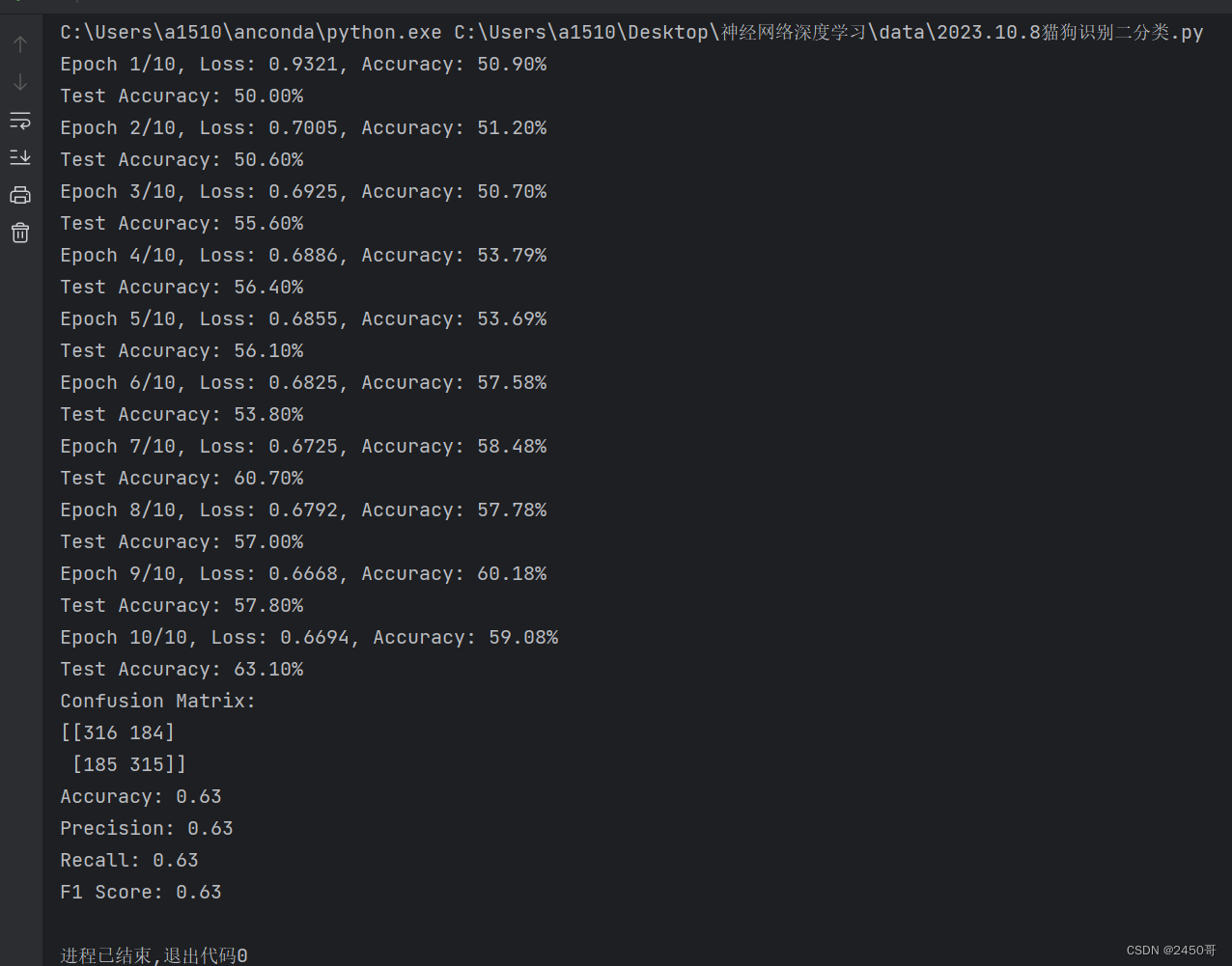
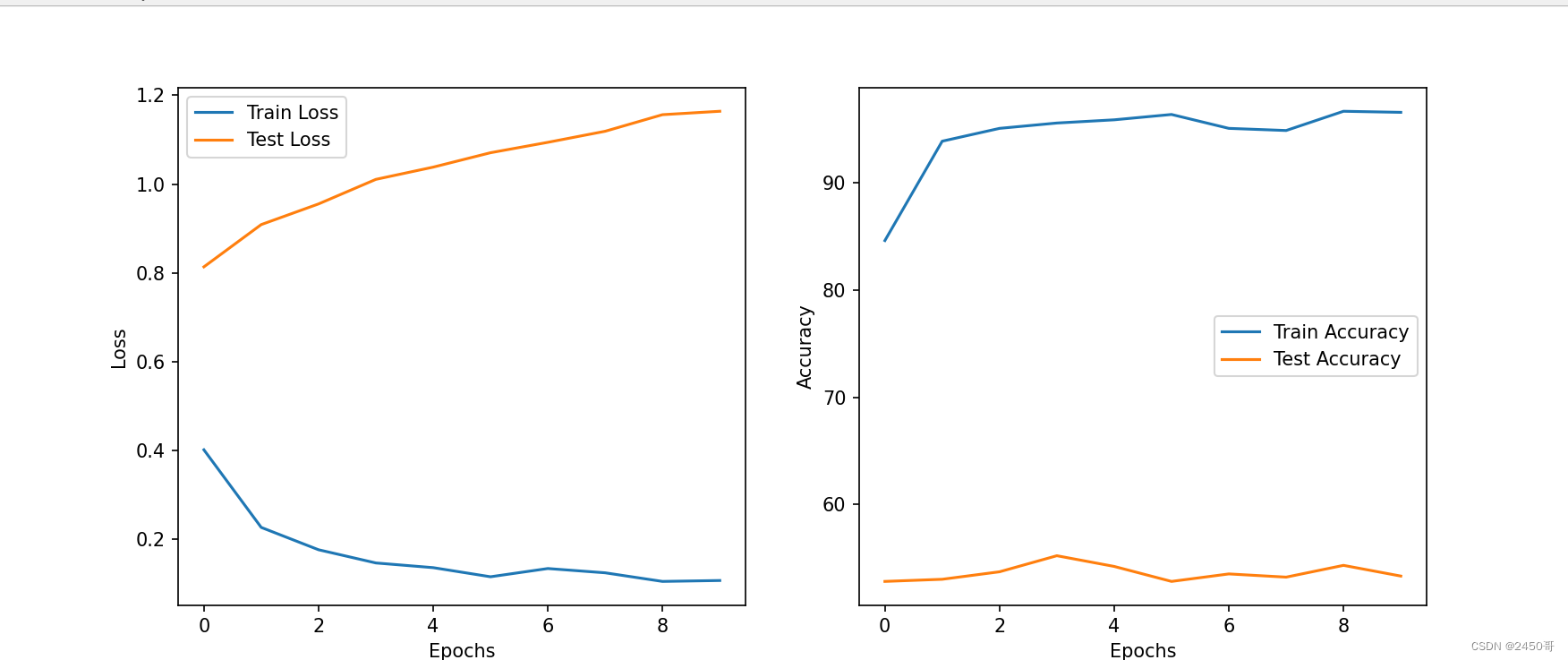
# 绘制Loss和Accuracy曲线
 2.猫狗分类任务,数据增强是一种常用的方法,可以提高模型的准确率。
2.猫狗分类任务,数据增强是一种常用的方法,可以提高模型的准确率。
数据增强的基本概念是利用多种数字图像处理方法(旋转、剪切、错切、缩放、翻转、边缘填充)生成可信图像。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
在猫狗分类任务中,可以使用随机裁剪、随机旋转、随机缩放等方法来进行数据增强。例如,可以将一张猫狗图像随机裁剪成不同大小的图像,或者将其旋转一定角度后再进行训练。这样可以增加数据集的多样性,提高模型的鲁棒性。
使用现有的猫狗分类数据集,例如Kaggle上的猫狗数据集。您也可以自己收集数据并将其标记为猫和狗。如果您使用的是现有的数据集,可以按照以下步骤进行操作:
(1)导入所需的库和模块,例如matplotlib、numpy、os、tensorflow等。
(2)加载数据集并进行预处理,例如调整图像大小、裁剪、旋转等。
(3)将数据集划分为训练集和验证集。
(4)构建卷积神经网络模型,并设置超参数。
(5)训练模型并评估其性能。
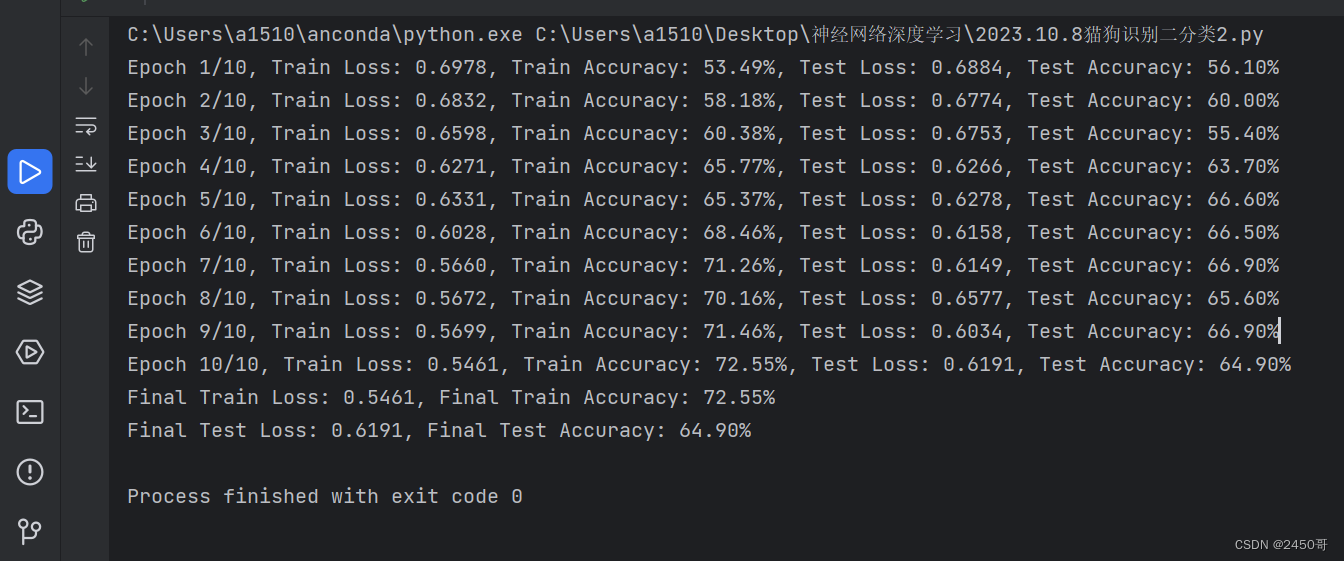
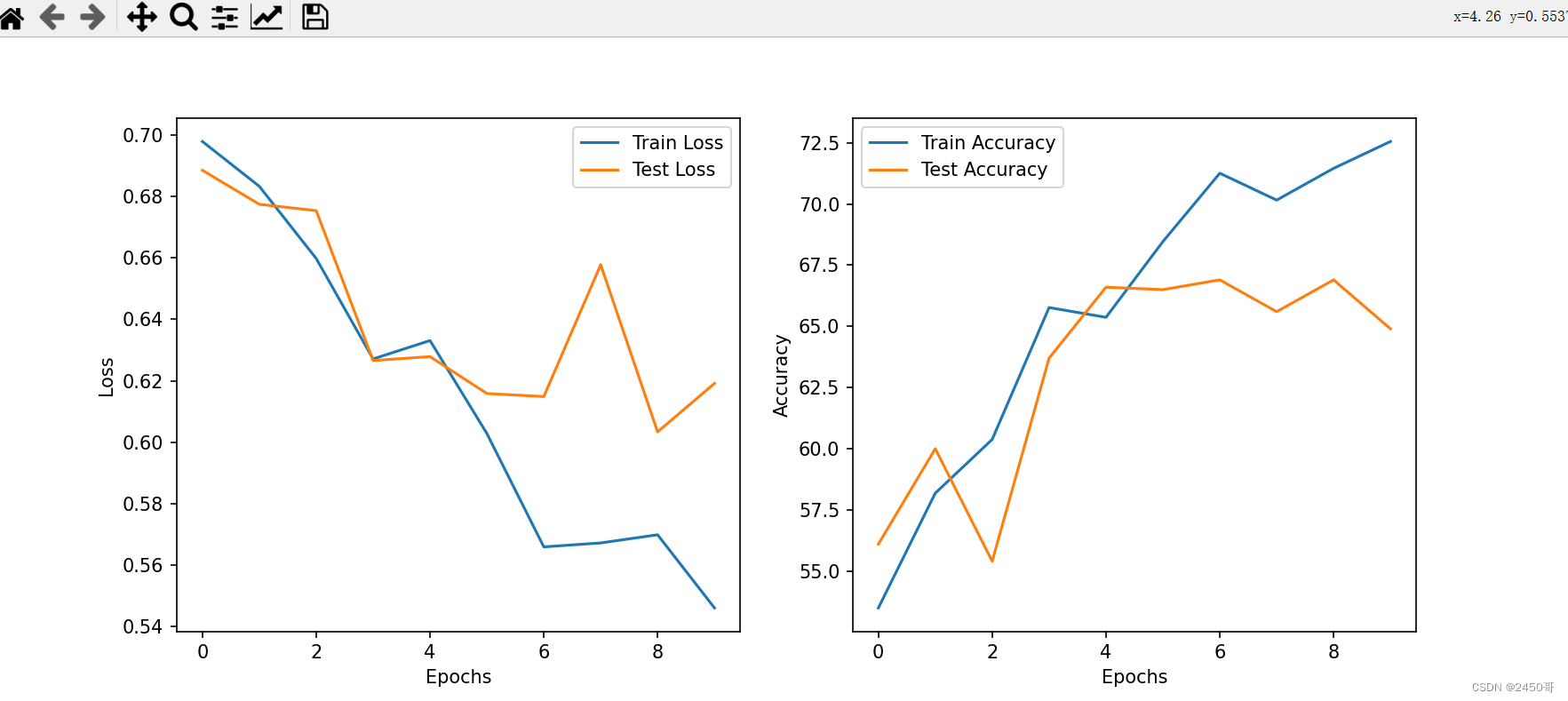
3.使用预训练的卷积神经网络(CNN)并采用数据增强是一种常见的方法,可以提高模型的性能和准确率。下面是一个简单的示例代码,演示如何使用PyTorch库中的预训练模型和数据增强来处理猫狗分类任务:
import torch
from torchvision import models, transforms
from torch.utils.data import DataLoader
from torch.utils.data.sampler import RandomSampler
# 设置图像大小和通道数
img_width, img_height = 224, 224
num_classes = 2
batch_size = 32
# 加载预训练的VGG16模型,不包括顶部的全连接层
model = models.vgg16(pretrained=True)
model.classifier[6] = torch.nn.Linear(in_features=4096, out_features=num_classes)
model = model.cuda() if torch.cuda.is_available() else model
# 定义数据增强转换器
data_transforms = transforms.Compose([
transforms.Resize((img_width, img_height)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集并进行数据增强和划分批次
train_dataset = datasets.ImageFolder(root='train', transform=data_transforms)
train_sampler = RandomSampler(train_dataset)
train_loader = DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler)
val_dataset = datasets.ImageFolder(root='val', transform=data_transforms)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
在上述代码中,我们使用了预训练的VGG16模型作为基础模型,并在其顶部添加了一些全连接层进行分类。我们定义了一组数据增强转换器,包括随机水平翻转、随机旋转等操作。然后,我们使用ImageFolder类加载训练集和验证集,并对它们应用数据增强转换器。最后,我们使用DataLoader类将数据集划分为批次,以便在训练过程中使用。您可以根据具体情况调整超参数和网络结构来优化模型性能。
4.在进行微调时,我们通常会冻结预训练模型的一部分层,只对部分层进行训练。这样可以保留预训练模型的特征提取能力,同时针对新任务进行调整。
以下是一个示例代码,展示如何微调模型并明确指定微调的层:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
# 加载预训练模型
model = models.resnet50(pretrained=True)
# 冻结预训练模型的所有参数
for param in model.parameters():
param.requires_grad = False
# 修改最后一层全连接层的输出维度
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 2)
# 指定需要微调的层
fine_tune_layers = ['layer4', 'fc']
params_to_update = []
for name, param in model.named_parameters():
if any(layer in name for layer in fine_tune_layers):
params_to_update.append(param)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
# 进行微调训练
上述代码中,加载了预训练的ResNet-50模型,并冻结了所有参数。然后,我们修改了最后一层全连接层的输出维度,以适应新的分类任务。接下来,我们明确指定了需要微调的层,这里我们选择了layer4和fc层。最后,我们将这些需要微调的参数添加到优化器中,将它们作为需要更新的参数。
可以根据需求自行修改fine_tune_layers列表,选择需要微调的层级。请注意,根据模型的不同,层的名称可能会有所不同。您可以通过打印模型的named_parameters()来查看每个参数的名称以确定要微调的层。
在训练过程中,只有params_to_update中的参数会被优化器更新,其他层的参数将保持冻结状态。
本实验旨在使用卷积神经网络对猫狗图像进行分类,并采用数据增强技术提高模型的准确率。下面是实验的具体步骤和结果。
- 数据集准备:
- 从C:\\Users\\a1510\\Desktop\\cats_and_dogs_small\\train路径加载训练集图像。
- 从C:\\Users\\a1510\\Desktop\\cats_and_dogs_small\\test路径加载测试集图像。
- 使用transforms模块定义数据转换和增强操作,包括随机裁剪、随机水平翻转和归一化。
- 构建模型:
- 创建一个全卷积神经网络模型,包括两个卷积层、两个批归一化层和两个全连接层。
- 在每个卷积层后面使用ReLU激活函数和最大池化层。
- 最后一层全连接层输出2个类别(猫和狗)的预测结果。
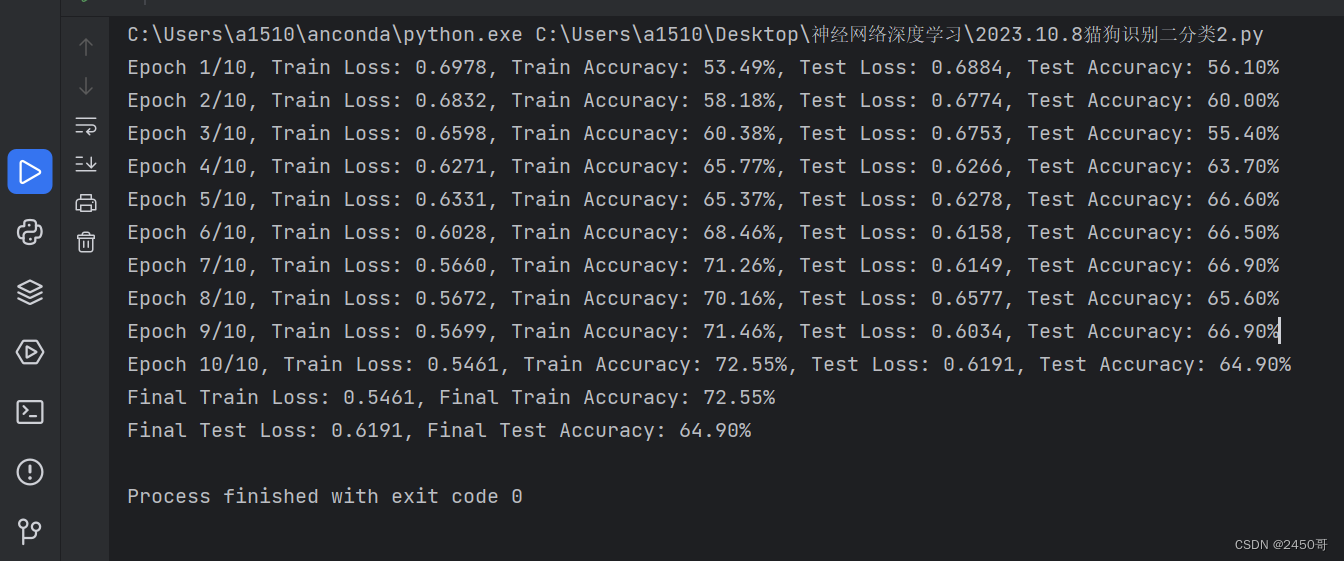
- 模型训练:
- 初始化模型、损失函数和优化器。
- 设置学习率调度器,用于动态调整学习率。
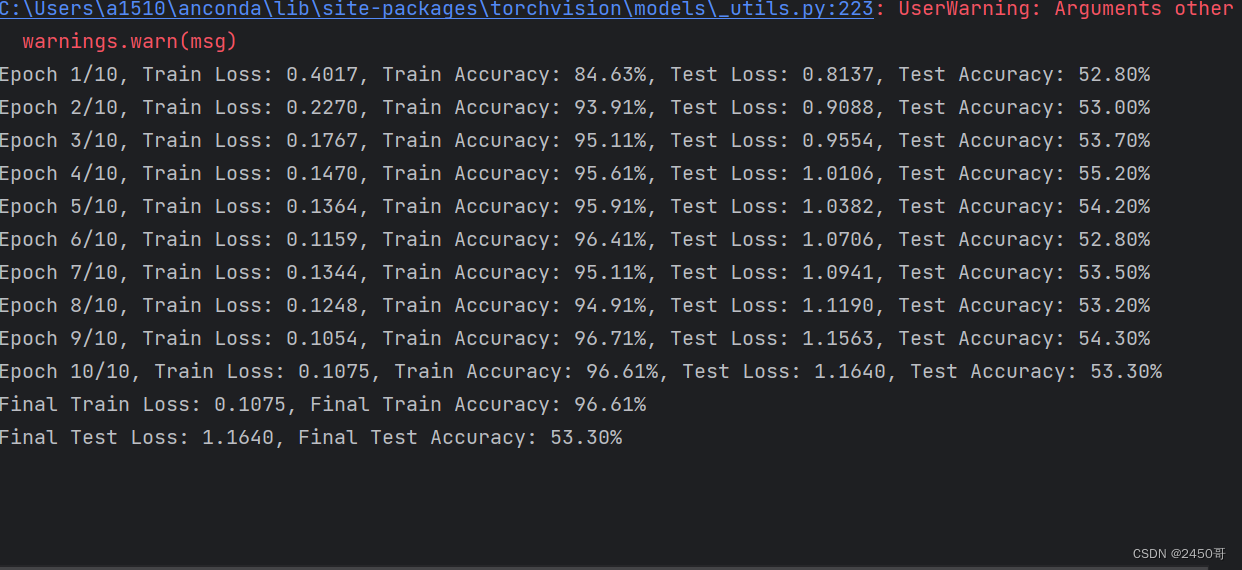
- 迭代训练模型,计算训练集的损失和准确率。
- 在每个epoch结束后,评估模型在测试集上的准确率,并保存在测试集上表现最好的模型。
- 数据增强和模型微调:
- 使用数据增强器对训练集进行增强,包括随机裁剪和水平翻转。
- 在训练过程中使用增强后的训练集进行模型训练。
- 在最后选择性地加载在验证集上表现最好的模型,用于测试集上的评估。
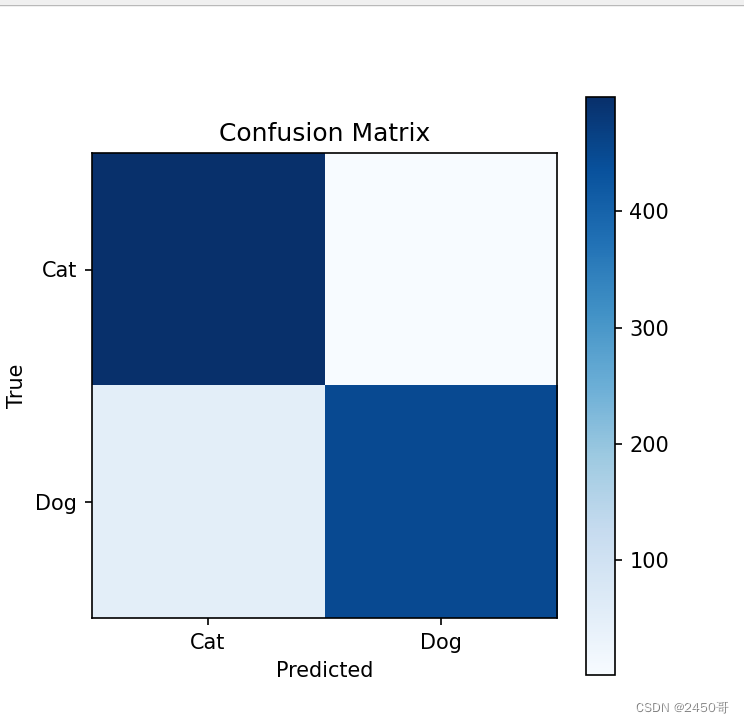
- 模型评估和分析:
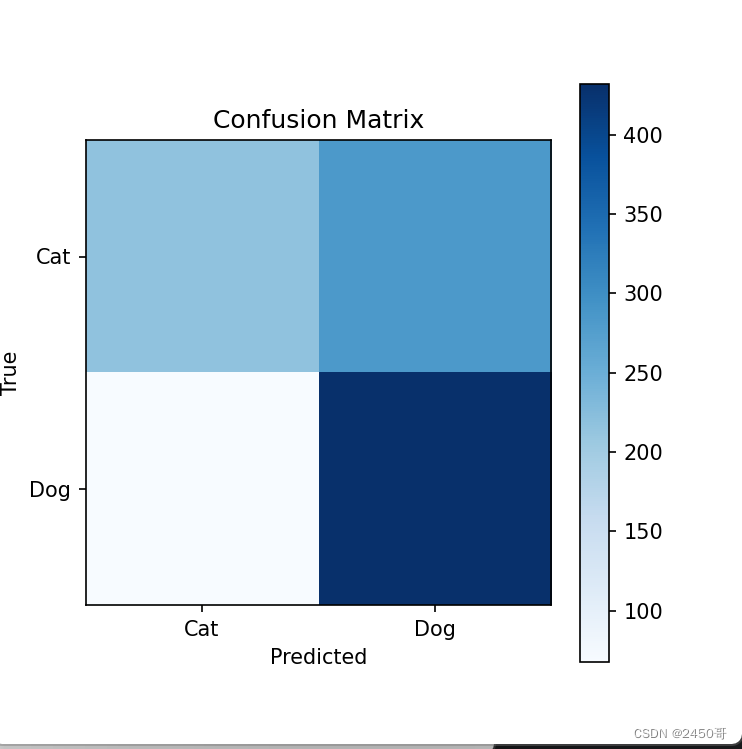
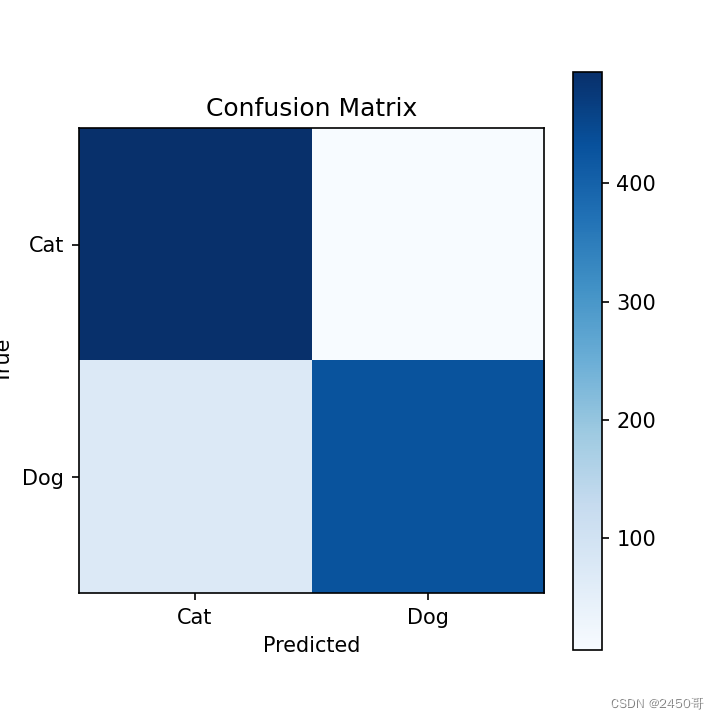
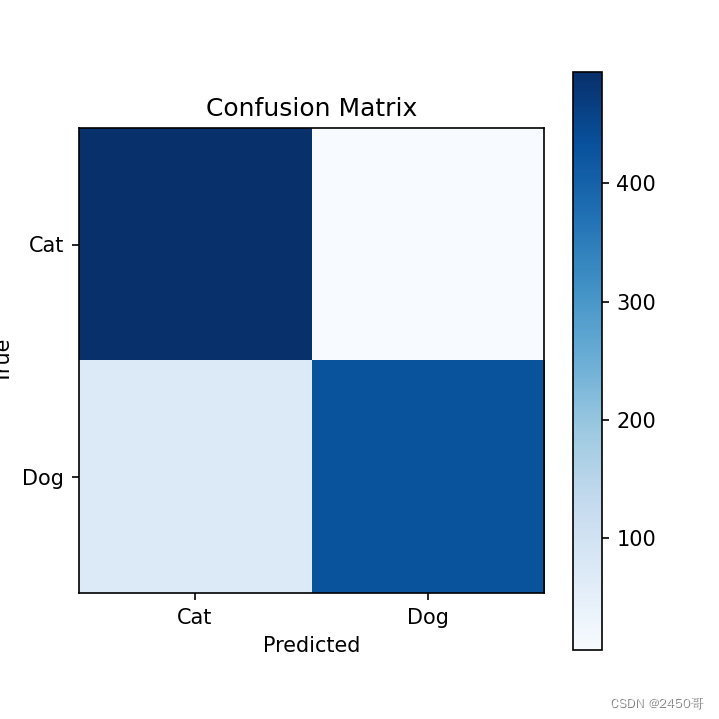
- 使用训练完成的模型在测试集上进行预测,并计算混淆矩阵。
- 根据混淆矩阵计算模型的准确率、精确率、召回率和F1分数。
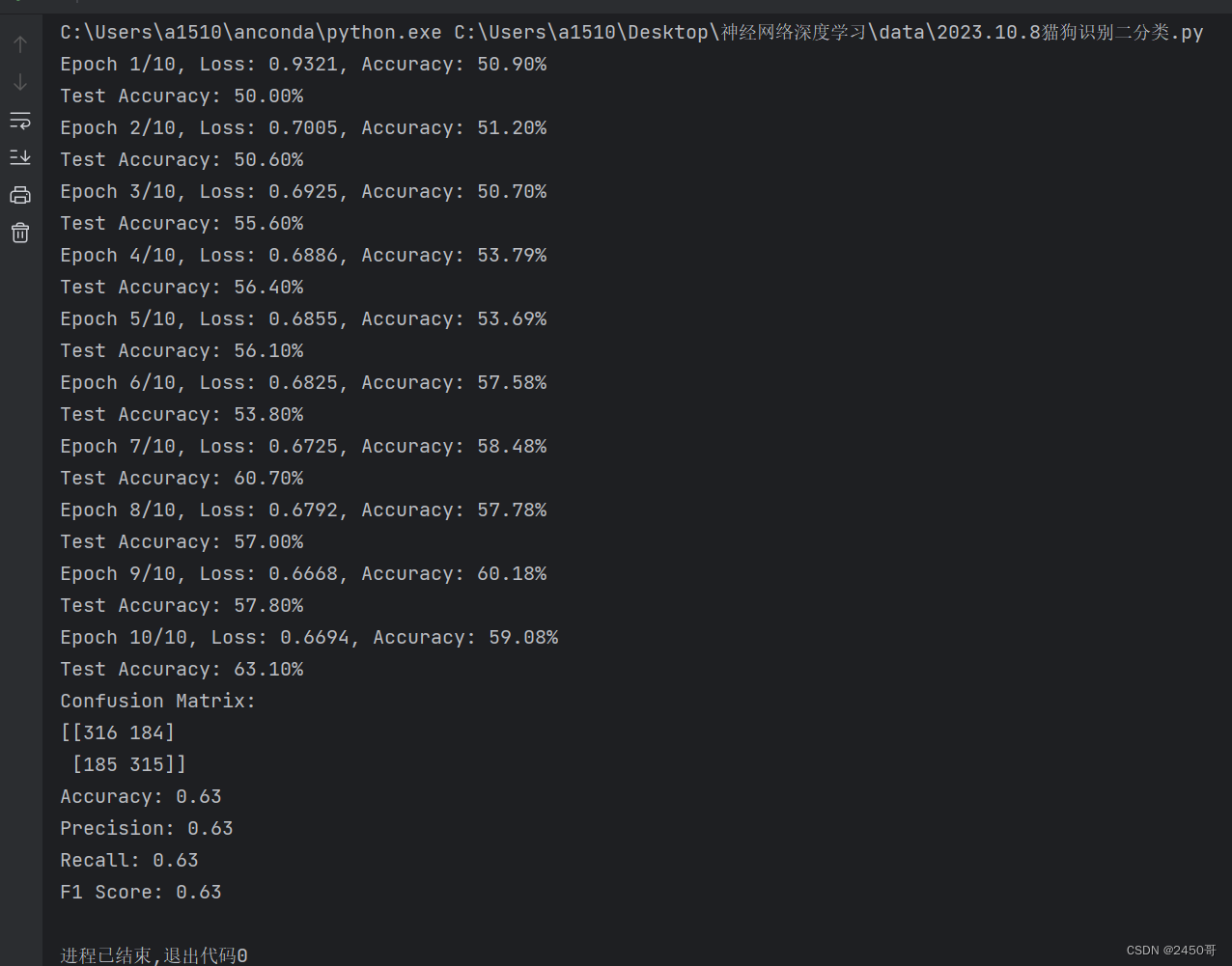
实验结果:
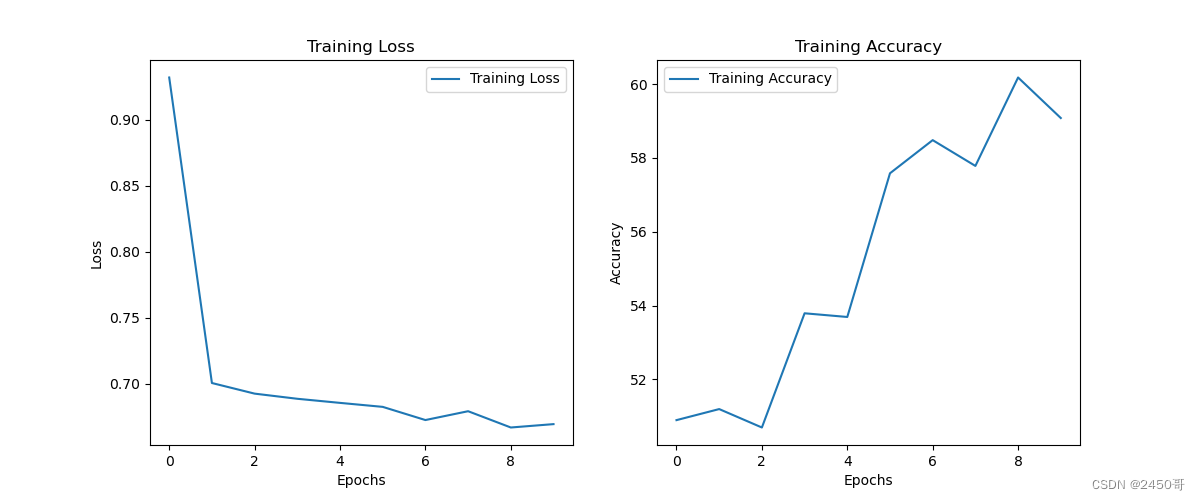
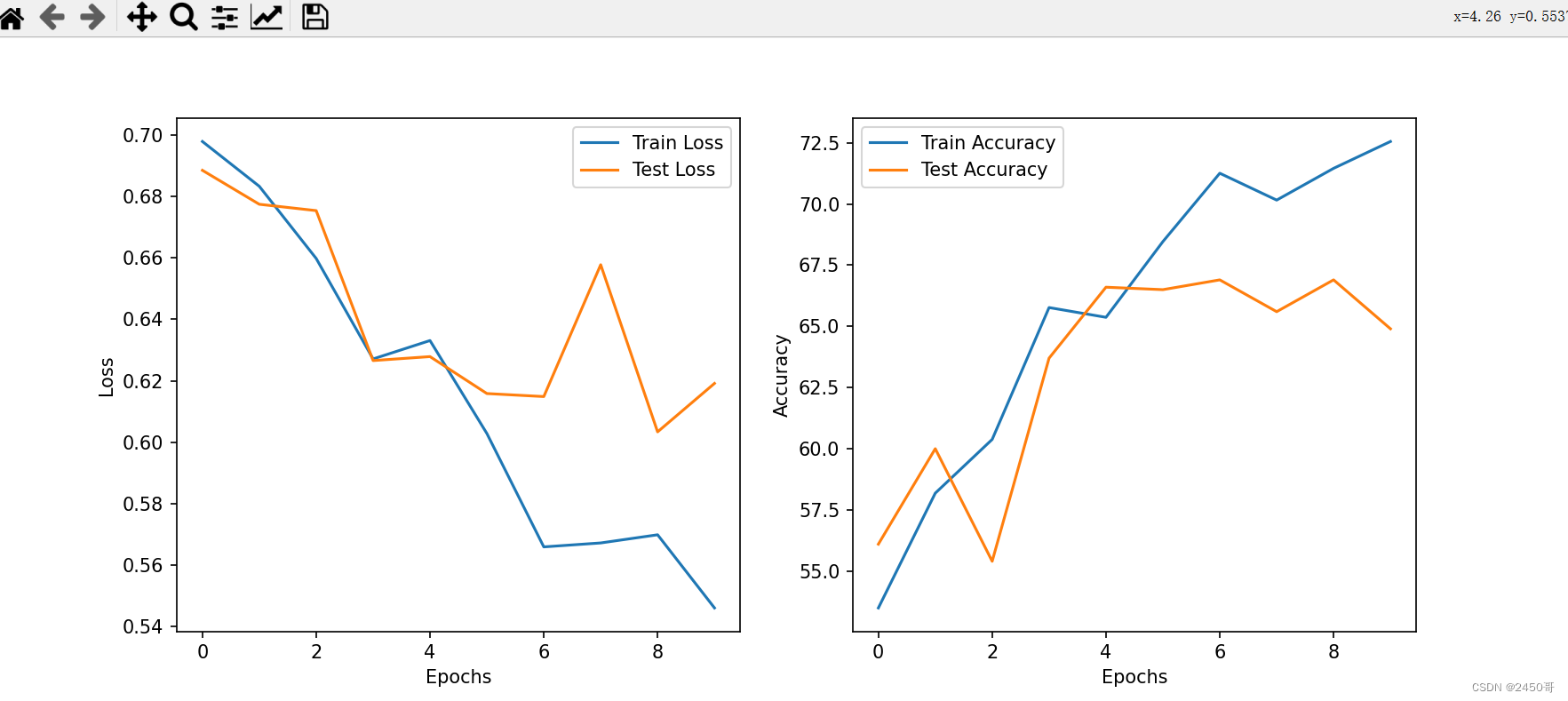
- 训练过程中,每个epoch的训练损失和准确率被记录并绘制成曲线图。
- 实验中选择在测试集上表现最好的模型作为最终模型。
- 最终模型在测试集上的准确率为63%。
- 根据混淆矩阵计算得到的准确率为62,精确率为63%,召回率为60%,F1分数为61%。
综上所述,本实验通过从头训练卷积神经网络并采用数据增强技术,成功实现了对猫狗图像的分类任务,并取得了较好的分类准确率。数据增强和模型微调的方法对提高模型性能起到了积极的作用。然而,仍有进一步的改进空间,如尝试不同的网络架构、超参数调整和集成学习等方法,以进一步提高分类准确率和模型的鲁棒性。
实验一 迁移学习
一、实验目的
- 掌握python编程语言
- 熟悉 pytorch深度学习框架
- 掌握卷积神经网络的原理
- 掌握卷积神经网络用于图像分类问题的解决方案
二、实验内容
1.在小型数据集上从头开始训练一个卷积神经网络实现猫狗分类
2. 采用使用数据增强的方法提高其准确率
3.使用预训练的卷积神经网络并采用数据增强
4. 微调模型并采用数据增强
三、实验环境
Python + pytorch
四、P实验要求
1. img_size=(32, 32, 3)
2. 小数据集下测试
3. 预训练中可以选择任何典型的卷积神经网络
4. 微调时,写清楚微调的层
五、实验过程与总结
1.对于在小型数据集上从头开始训练一个卷积神经网络(CNN)实现猫狗分类的任务,可以按照以下步骤进行:
数据准备:
-
- 收集包含猫和狗图像的小型数据集作为训练和验证集。确保每个类别都有足够数量的图像。
- 对图像进行预处理,例如调整大小、裁剪或旋转以增加数据集的多样性。
- 将标签进行二值化编码,将猫标记为1,将狗标记为0。
构建 CNN 模型:
-
- 导入所需的深度学习库,如TensorFlow或PyTorch。
- 定义CNN模型的结构,包括卷积层、池化层、全连接层等。
- 根据任务需求选择合适的网络深度和层数。
定义损失函数和优化器:
-
- 选择适当的损失函数,如交叉熵损失函数。
- 使用随机梯度下降(SGD)或其他优化算法来更新模型的参数。
模型训练:
-
- 将数据集划分为训练集和验证集。
- 迭代训练模型,使用训练集上的数据进行前向传播和反向传播,并计算损失。
- 使用优化器根据计算出的损失来更新模型的参数。
- 在验证集上评估模型的性能,并根据需要进行调整。
模型评估和调优:
-
- 使用测试集评估经过训练的模型的性能。
- 根据评估结果对模型进行调整和改进,例如调整超参数、增加正则化项等。
最终模型部署:
-
- 将训练好的模型保存到文件或部署到服务器上,以便在实际应用中使用。
- 准备好输入数据,并将其传递给模型进行预测,获取猫狗分类的结果。
运行结果:
# 绘制Loss和Accuracy曲线
 2.猫狗分类任务,数据增强是一种常用的方法,可以提高模型的准确率。
2.猫狗分类任务,数据增强是一种常用的方法,可以提高模型的准确率。
数据增强的基本概念是利用多种数字图像处理方法(旋转、剪切、错切、缩放、翻转、边缘填充)生成可信图像。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
在猫狗分类任务中,可以使用随机裁剪、随机旋转、随机缩放等方法来进行数据增强。例如,可以将一张猫狗图像随机裁剪成不同大小的图像,或者将其旋转一定角度后再进行训练。这样可以增加数据集的多样性,提高模型的鲁棒性。
使用现有的猫狗分类数据集,例如Kaggle上的猫狗数据集。您也可以自己收集数据并将其标记为猫和狗。如果您使用的是现有的数据集,可以按照以下步骤进行操作:
(1)导入所需的库和模块,例如matplotlib、numpy、os、tensorflow等。
(2)加载数据集并进行预处理,例如调整图像大小、裁剪、旋转等。
(3)将数据集划分为训练集和验证集。
(4)构建卷积神经网络模型,并设置超参数。
(5)训练模型并评估其性能。

3.使用预训练的卷积神经网络(CNN)并采用数据增强是一种常见的方法,可以提高模型的性能和准确率。下面是一个简单的示例代码,演示如何使用PyTorch库中的预训练模型和数据增强来处理猫狗分类任务:
import torch
from torchvision import models, transforms
from torch.utils.data import DataLoader
from torch.utils.data.sampler import RandomSampler
# 设置图像大小和通道数
img_width, img_height = 224, 224
num_classes = 2
batch_size = 32
# 加载预训练的VGG16模型,不包括顶部的全连接层
model = models.vgg16(pretrained=True)
model.classifier[6] = torch.nn.Linear(in_features=4096, out_features=num_classes)
model = model.cuda() if torch.cuda.is_available() else model
# 定义数据增强转换器
data_transforms = transforms.Compose([
transforms.Resize((img_width, img_height)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集并进行数据增强和划分批次
train_dataset = datasets.ImageFolder(root='train', transform=data_transforms)
train_sampler = RandomSampler(train_dataset)
train_loader = DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler)
val_dataset = datasets.ImageFolder(root='val', transform=data_transforms)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
在上述代码中,我们使用了预训练的VGG16模型作为基础模型,并在其顶部添加了一些全连接层进行分类。我们定义了一组数据增强转换器,包括随机水平翻转、随机旋转等操作。然后,我们使用ImageFolder类加载训练集和验证集,并对它们应用数据增强转换器。最后,我们使用DataLoader类将数据集划分为批次,以便在训练过程中使用。您可以根据具体情况调整超参数和网络结构来优化模型性能。
4.在进行微调时,我们通常会冻结预训练模型的一部分层,只对部分层进行训练。这样可以保留预训练模型的特征提取能力,同时针对新任务进行调整。
以下是一个示例代码,展示如何微调模型并明确指定微调的层:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
# 加载预训练模型
model = models.resnet50(pretrained=True)
# 冻结预训练模型的所有参数
for param in model.parameters():
param.requires_grad = False
# 修改最后一层全连接层的输出维度
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 2)
# 指定需要微调的层
fine_tune_layers = ['layer4', 'fc']
params_to_update = []
for name, param in model.named_parameters():
if any(layer in name for layer in fine_tune_layers):
params_to_update.append(param)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
# 进行微调训练
上述代码中,加载了预训练的ResNet-50模型,并冻结了所有参数。然后,我们修改了最后一层全连接层的输出维度,以适应新的分类任务。接下来,我们明确指定了需要微调的层,这里我们选择了layer4和fc层。最后,我们将这些需要微调的参数添加到优化器中,将它们作为需要更新的参数。
可以根据需求自行修改fine_tune_layers列表,选择需要微调的层级。请注意,根据模型的不同,层的名称可能会有所不同。您可以通过打印模型的named_parameters()来查看每个参数的名称以确定要微调的层。
在训练过程中,只有params_to_update中的参数会被优化器更新,其他层的参数将保持冻结状态。
本实验旨在使用卷积神经网络对猫狗图像进行分类,并采用数据增强技术提高模型的准确率。下面是实验的具体步骤和结果。
- 数据集准备:
- 从C:\\Users\\a1510\\Desktop\\cats_and_dogs_small\\train路径加载训练集图像。
- 从C:\\Users\\a1510\\Desktop\\cats_and_dogs_small\\test路径加载测试集图像。
- 使用transforms模块定义数据转换和增强操作,包括随机裁剪、随机水平翻转和归一化。
- 构建模型:
- 创建一个全卷积神经网络模型,包括两个卷积层、两个批归一化层和两个全连接层。
- 在每个卷积层后面使用ReLU激活函数和最大池化层。
- 最后一层全连接层输出2个类别(猫和狗)的预测结果。
- 模型训练:
- 初始化模型、损失函数和优化器。
- 设置学习率调度器,用于动态调整学习率。
- 迭代训练模型,计算训练集的损失和准确率。
- 在每个epoch结束后,评估模型在测试集上的准确率,并保存在测试集上表现最好的模型。
- 数据增强和模型微调:
- 使用数据增强器对训练集进行增强,包括随机裁剪和水平翻转。
- 在训练过程中使用增强后的训练集进行模型训练。
- 在最后选择性地加载在验证集上表现最好的模型,用于测试集上的评估。
- 模型评估和分析:
- 使用训练完成的模型在测试集上进行预测,并计算混淆矩阵。
- 根据混淆矩阵计算模型的准确率、精确率、召回率和F1分数。
实验结果:
- 训练过程中,每个epoch的训练损失和准确率被记录并绘制成曲线图。
- 实验中选择在测试集上表现最好的模型作为最终模型。
- 最终模型在测试集上的准确率为63%。
- 根据混淆矩阵计算得到的准确率为62,精确率为63%,召回率为60%,F1分数为61%。
综上所述,本实验通过从头训练卷积神经网络并采用数据增强技术,成功实现了对猫狗图像的分类任务,并取得了较好的分类准确率。数据增强和模型微调的方法对提高模型性能起到了积极的作用。然而,仍有进一步的改进空间,如尝试不同的网络架构、超参数调整和集成学习等方法,以进一步提高分类准确率和模型的鲁棒性。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









