






众所周知,计算机只认识0和1两个数,我们操作计算机做的任何事,都需要先转换成0或1的串,然后计算机才认识,才可以有所反应。

这就好比计算机是一个外国人,这个国家的人只认识0和1的串,我们想要和它沟通让它帮我们做事,就需要先了解他们的语言,也就是各种0和1的串,这就是机器语言。
比如0001可以看成是前进,0010可以看成是后退,那我们就可以通过提供0001或0010来控制它前进或后退。但这种串对于我们来说记忆起来太复杂,所以我们给这些串起了别名,比如fmove对应0001,bmove对应0010,这样我们就可以很直观的应用别名来控制计算机了,这个别名的集合就是最底层的汇编语言。
汇编对于我们来说还是太繁琐,要编写一个程序,我们不但要理清楚程序要实现的逻辑,还需要了解汇编的运行逻辑(要操作寄存器、内存读写等的各种硬件),各种逻辑混杂导致汇编写程序相当的难。此时,第一代C语言编译器就应运而生,它是通过汇编完成的,让我们不用再特意关注汇编的运行逻辑,尽量多的将注意力可以放在理清楚程序要实现的逻辑。
C语言之后,又逐渐发展出了更多的语言,像C++,Java,Python等,他们都比C语言拥有更多或高级、或灵活、或有趣的设计,能让我们更关注于理清楚程序要实现的逻辑,所以他们开发效率更高、开发的程序更大。

我们总结一下刚才的描述,第一代语言是机器语言,第二代语言是汇编语言,第三代语言是高级语言,此时就诞生了让人眼花缭乱的语言。像面向过程的C、Fortran、COBOL等;面向对象的C++,Java,C#等。
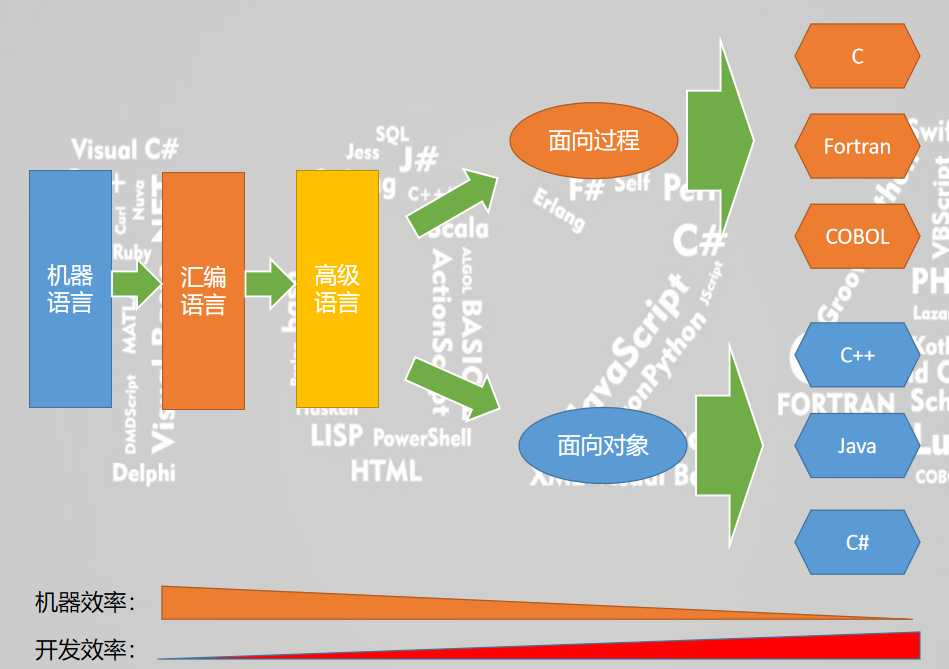
编译语言的发展,实际就是运行效率和开发效率的博弈。随着编译语言的发展,机器的效率逐渐的降低,而开发效率也逐渐的提高。所以在面对不同的应用场景时,高手们总是会选择合适的编译语言,而不会过分依赖某一种语言。















 3230
3230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









