






Trident是对基于Storm做实时计算的高层抽象。它可以使得高吞吐量、有状态的流处理与低延迟的分布式查询无缝衔接。如果你熟悉高水平的批处理工具如Pig/Cascading,那么Trident的概念将易于理解。Trident具有joins、aggregations、grouping、functions和filters。除此之外,Trident增加了基于任何数据库或持久化存储的有状态、持续处理。Trident具有consisten、exactly-once语义。
实例
此实例做两件事:
-
对输入流的句子进行单词计数的流式计算
-
实现对一组单词计数的查询
此例将在如下source中持续不断的读入句子:
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true);
上述spout循环输出一组sentences以产生stream,单词计数的流计算代码:
//创建TridentTopology,为构建Trident计算提供接口
TridentTopology topology = new TridentTopology(); //newStream方法创建一个数据流,读取输入源,此处为以上定义的FixedBatchSpout。输入源也可以是诸如Kestrel或者Kafka等queue brokers。Trident在 Zookeeper中为每一输入源记录少量的状态信息 , "spout1" 具体化Zookeeper 中的node, Trident将元数据保留在那里。 TridentState wordCounts = topology.newStream("spout1", spout) .each(new Fields("sentence"), new Split(), new Fields("word")) .groupBy(new Fields("word")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")) .parallelismHint(6);
Trident以小批量tuple来处理stream,比如上述输入流中的句子将被划分为batches:
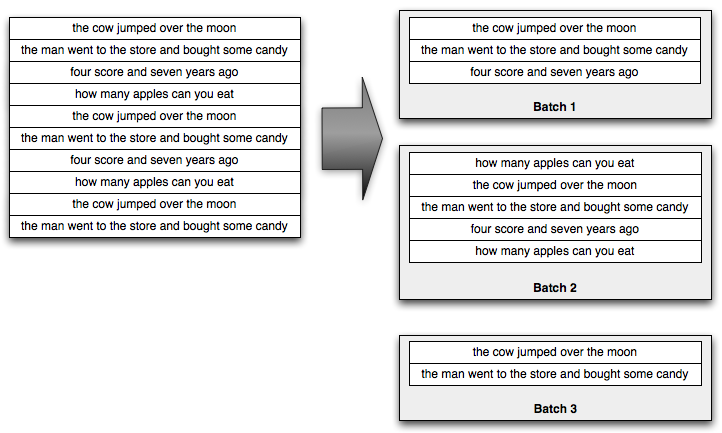
根据应用的吞吐量,一般而言,小批量将为1亿条tuples。Trident为小批量提供全面的批处理API。这些API与Hadoop之上的Pig/Cascading相似:group by、join、aggregation、runfunction、run filter等等。当然,小批量处理不保障Isolation,因此Trident将批量上的汇总结果持久化存储在内存、Memcached、Cassandra或其他。最后,Trident具有查询源的实时状态的优秀Function,state可被Trident更改。
上例中接下来的一行:Split(),spoutemits的stream包含名为sentence的field,此Function将"sentence"分割为word。每一sentencetuple对应创建多个wordtuples。Split函数定义:
public class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
topology接下来进行单词统计并持久化存储结果。先由"word"分组,后由Count()持续统计,而FunctionpersistentAggregate知道如何存储、更新汇总结果。本例将结果存储于内存,但这可以简单的切换至Memcached、Cassandra或其他。将单词统计结果存入Memcached的代码改写如下,利用trident-memcached,代码中的"serverLocations"是Memcached集群中的一系列host/port:
.persistentAggregate(MemcachedState.transactional(serverLocations), new Count(), new Fields("count"))
MemcachedState.transactional()
Trident具有容错、exactly-once的处理语义,使其易于支持实时处理。Trident如果执行失败将进行必要的重试, 它不会对相同数据做多次更新。
persistentAggregate将Stream转换为TridentState对象。此例,TridentState对象即为所有单位统计数。我们将用TridentState对象实现计算结果的分布式查询。
topology实现了对单词统计的低延迟、分布式查询。此查询以一组由空格分割的单词作为输入,以单词和其计数作为输出。这些查询如同普通RPC调用但他们在后端并行执。以下为查询调用的例子:
DRPCClient client = new DRPCClient("drpc.server.location", 3772);
System.out.println(client.execute("words", "cat dog the man");
// prints the JSON-encoded result, e.g.: "[[5078]]"
small queries的延迟一般为10ms左右,复杂DRPC查询将花费更长一点的时间,尽管延迟基本由分配计算资源的多少决定。topology中的分布式查询实现如下:
topology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
相同的TridentTopology对象用于创建DRPC stream且其function命名为words。此function name 对应上面DRPCClient执行中作为第一个参数的functionname。每一个DRPCrequest被看作为它自己的小批量处理job,输入单个tuple作为request。此tuple一个名为"args"的Field,内含client提供的参数。本例此参数为空格分割的一组单词。
分割单位,以word分组。stateQuery操作用于查询topology产生的TridentState对象。stateQuery获取一个state源,此例中,由topology其他部分计算的单词计数。MapGet function 被调用来获取每个单词的计数。既然DRPC stream以与TridentState相同的方式分组,则每个单词的查询被路由到TridentState对象的准确分部。接下来,没有统计值的单词将由过滤器FilterNull过滤掉,并由Sum实现结果汇总。Trident自动将此结果发送给等待的client。
Trident 是智能的,它能以最好的性能执行一个topology。在topology中将有如下两个优化:
-
对state的读写操作(persistentAggregate、stateQuery)自动的转为对此state的批处理操作。如果当前批处理对数据库有20个updates,Trident将自动为reads和writes分批,仅执行1read request 和1write request,而非20 read requests 和20 writes requests, (许多情况下,你可在State实现中使用caching以消除readrequest)。这样既得到最好的表达计算的convenience,也能获得最好的performance。
-
Trident aggregators 是深度优化的。不是将tuple分组传至同一机器而后执行aggregator,Trident在将tuple发送至网络前将尽可能做部分aggregations。比如,Count首先在每个分部上计算,将部分结果分送至网络再将各个部分结果汇总,与MapReduce上的combiners相似















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









