







pandas的常见操作
pandas操作excel的基础用法
pandas是Python的第三方库,使用pandas库能高效的处理excel数据,在数据分析或者机器人自动化流程中广泛使用。它有一个极大的优点:数据和处理逻辑是分离的。基于这一点,便可以实现Excel数据处理的自动化。
1.安装
pip install pandas
当遇到安装出错时,一般可以通过升级 pip 和升级 setuptools 解决。
2.基本结构
- pandas有两个主要的数据结构,一个是Series,另一个是DataFrame。
- Series一种增强的一维数组,类似于列表,由索引(index)和值(values)组成。
- DataFrame是一个类似表格的二维数据结构,索引包括列索引和行索引,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame的每一行和每一列都是一个Series
3.基本操作
1、读取xlsx表格:pd.read_excel()
a)读取第n个Sheet(子表,在左下方可以查看或增删子表)的数据,通过执行sheet_name可以指定读取某个sheet页的数据。
import pandas as pd
# 每次都需要修改的路径
path = "test.xlsx"
# sheet_name默认为0,即读取第一个sheet的数据
sheet = pd.read_excel(path, sheet_name=0)
print(sheet)
"""
Unnamed: 0 name1 name2 name3
0 row1 1 2.0 3
1 row2 4 NaN 6
2 row3 7 8.0 9
"""
细心的小伙伴们可能会发现,原始excel表格左上角有一列是没有填入内容,pandas读取Excel文件后,读取的结果是“Unnamed: 0” ,这是由于read_excel函数会默认把表格的第一行为列索引名。另外,对于行索引名来说,默认从第二行开始编号(因为默认第一行是列索引名,所以默认第一行不是数据)。如果无特意指定索引,则自动从0开始编号。演示代码如下:
sheet = pd.read_excel(path)
# 查看列索引名,返回列表形式
print(sheet.columns.values)
# 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式
print(sheet.index.values)
"""
['Unnamed: 0' 'name1' 'name2' 'name3']
[0 1 2]
"""
b)对于列索引名而已,还可进行自定义,演示代码如下:
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4'])
print(sheet)
# 查看列索引名,返回列表形式
print(sheet.columns.values)
"""
col1 col2 col3 col4
0 row1 1 2.0 3
1 row2 4 NaN 6
2 row3 7 8.0 9
['col1' 'col2' 'col3' 'col4']
"""
c)也可以指定第n列为行索引名,如下:
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
"""
d)pandas可以根据需要指定跳过第n行读取数据,颜时代吗如下:
# 跳过第2行的数据(第一行索引为0)
sheet = pd.read_excel(path, skiprows=[1])
print(sheet)
"""
Unnamed: 0 name1 name2 name3
0 row2 4 NaN 6
1 row3 7 8.0 9
"""
e) 获取表格的数据大小
通过sheet.shape可以获取到行列的数量,返回一个列表,第一个索引位置的值为行数,第二位列数。
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('==========================')
print('shape of sheet:', sheet.shape)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
==========================
shape of sheet: (3, 3)
"""
2.通过索引获取数据
索引数据的方法:
- [ ]
- loc[]
- iloc[]
a)直接加方括号索引
通过方括号加列名 [col_name] 可以提取dataframe中某列的数据,然后再用方括号加索引数字 [index] 来提取该列某个具体索引位置的值。如下代码表示检索列名为name1的列,然后选取索引为1的数据:
df= pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name1']
print(col)
# 打印该列第二个数据
print(col[1]) # 4
"""
0 1
1 4
2 7
Name: name1, dtype: int64
4
"""
b)iloc方法,按整数编号切片获取
使用 df.iloc[ ] ,方括号内为行列的整数位置编号(除去作为行索引的那一列和作为列索引的哪一行后,从 0 开始编号)。
- df.iloc[1, 2] :提取第2行第3列数据。第一个是行索引,第二个是列索引
- df.iloc[0: 2] :提取前两行数据
- df.iloc[0:2, 0:2] :通过分片的方式提取 前两行 的 前两列 数据
# 指定第一列数据为行索引
df= pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = df.iloc[1, 2]
print(data) # 6
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.iloc[0:2]
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice = df.iloc[0:2, 0:2]
print(data_slice)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""
c)loc方法,按行列名称索引
使用 df.loc[ ] ,方括号内为行列的名称字符串。具体使用方式同 iloc相同 ,不同的是把 iloc 的整数索引替换成了行列名进行选取符合条件的数据。
注意:iloc[1: 2] 是不包含2的,而 loc[‘row1’: ‘row2’] 是包含 ‘row2’ 的。
# 指定第一列数据为行索引
df= pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = df.loc['row2', 'name3']
print(data) # 1
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = df.loc['row1': 'row2']
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice1 = df.loc['row1': 'row2', 'name1': 'name2']
print(data_slice1)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""
4.判断数据是否为空
1)使用 numpy 库的 isnan() 或 pandas 库的 isnull() 方法可以判断某项数据是否等于 nan 。
df= pd.read_excel(path)
# 读取列名为 name1 的列数据
col = df['name2']
print(np.isnan(col[1])) # True
print(pd.isnull(col[1])) # True
"""
True
True
"""
2)使用 str() 转为字符串,判断是否等于 ‘nan’ 。如果excel单元格为空,转为字符串时变为以nan的形式展现。
df= pd.read_excel(path)
# 读取列名为 name1 的列数据
col = df['name2']
print(col)
# 打印该列第二个数据
if str(col[1]) == 'nan':
print('col[1] is nan')
"""
0 2.0
1 NaN
2 8.0
Name: name2, dtype: float64
col[1] is nan
"""
5.查找符合条件的数据
通过df[列名] == 1 条件表达式,可以筛选出列中符合条件的数据行的索引,结合loc可以灵活的获取到某列数据中符合指定条件的数据行。
# 提取name1 == 1 的行
name1_data= (df['name1'] == 1)
x = df.loc[name1_data]
print(x)
"""
name1 name2 name3
row1 1 2.0 3
"""
6.修改元素值
(1)df[‘name2’].replace(2, 100, inplace=True) :把 name2 列值为2的元素 改为 100。
注意:inplace表示是否在原数据上操作,True为在原数据上更改数据,Flase反之,需重新赋值给一个变量得到更新后的值。
df['name2'].replace(2, 100, inplace=True)
print(df)
"""
name1 name2 name3
row1 1 100.0 3
row2 4 NaN 6
row3 7 8.0 9
"""
(2)df[‘name2’].replace(np.nan, 100, inplace=True) :把 name2 列为空的元素(nan)改为100,并且是在元数据做修改操作(inplace=True)。
import numpy as np
df['name2'].replace(np.nan, 100, inplace=True)
print(df)
print(type(df.loc['row2', 'name2']))
"""
name1 name2 name3
row1 1 2.0 3
row2 4 100.0 6
row3 7 8.0 9
"""
7.增加数据
增加列,直接使用中括号 [ 要添加的名字 ] 添加,例如:df[‘name4’] = [55, 66, 77] (添加名为 name4 的列,值为[55, 66, 77])
path = "test.xlsx"
# 指定第一列为行索引
df= pd.read_excel(path, index_col=0)
print(df)
print('====================================')
# 添加名为 name4 的列,值为[55, 66, 77]
df['name4'] = [55, 66, 77]
print(df)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
====================================
name1 name2 name3 name4
row1 1 2.0 3 55
row2 4 NaN 6 66
row3 7 8.0 9 77
"""
8.删除数据
a)del(df[‘name3’]) :使用 del 方法删除,删除某一列
df= pd.read_excel(path, index_col=0)
# 使用 del 方法删除 'name3' 的列
del(df['name3'])
print(df)
"""
name1 name2
row1 1 2.0
row2 4 NaN
row3 7 8.0
"""
b)df.drop(‘row1’, axis=0):drop也是删除操作,通过axis删除行还是列。
- 使用 drop 方法删除 row1 行,删除列的话对应的 axis=1。
- 当 inplace 参数为 True 时,不会返回参数,直接在原数据上删除
- 当 inplace 参数为 False (默认)时不会修改原数据,而是返回修改后的数据
df.drop('row1', axis=0, inplace=True)
print(df)
"""
name1 name2 name3
row2 4 NaN 6
row3 7 8.0 9
"""
c)df.drop(labels=[‘name1’, ‘name2’], axis=1):使用 labels=[ ] 参数可以删除多行或多列数据
# 删除多列,默认 inplace 参数为False,即会返回结果
print(sheet.drop(labels=['name1', 'name2'], axis=1))
"""
name3
row1 3
row2 6
row3 9
"""
9.将数据保存到excel文件
1、通过to_excel()把 pandas 格式的数据另存为 .xlsx 文件
names = ['a', 'b', 'c']
scores = [99, 100, 99]
result_excel = pd.DataFrame()
result_excel["姓名"] = names
result_excel["评分"] = scores
# 写入excel
result_excel.to_excel('test3.xlsx')
2、把改好的 excel 文件另存为 .xlsx 文件。
import numpy as np
# 指定第一列为行索引
df= pd.read_excel(path, index_col=0)
df['name2'].replace(np.nan, 100, inplace=True)
df.to_excel('test2.xlsx')
10.去重操作
1)筛选出指定字段存在重复的数据
import pandas as pd
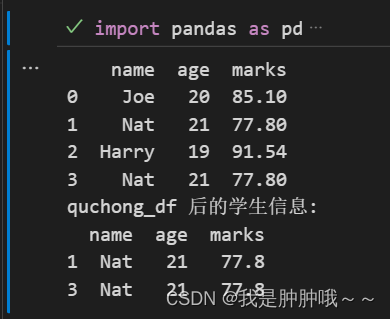
student_dict = {"name": ["Joe", "Nat", "Harry", "Nat"], "age": [20, 21, 19, 21], "marks": [85.10, 77.80, 91.54, 77.80]}
# 将字典格式的数据转成pandas中的dataframe形式,方便使用pandas操作数据
student = pd.DataFrame(student_dict)
print(student)
quchong_df = student[student.duplicated(subset=["age"], keep=False)]
print("quchong_df 后的学生信息:")
print(quchong_df )
运行结果:
2)drop_duplicates与duplicated的区别
-
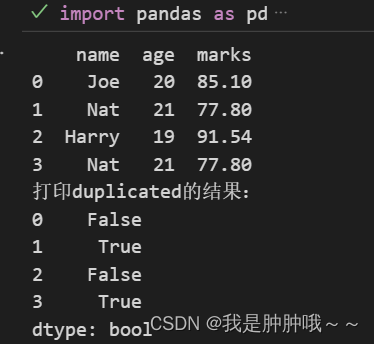
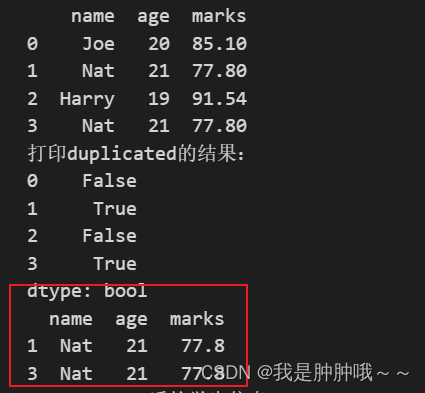
duplicated():duplicated方法返回的是一个布尔值Series(student.duplicated(subset=[“age”], keep=False)), 与之前出现的行对比,是否存在重复的行。如果重复则返回True,不重复则返回False。最终可以通过变量名[](student[student.duplicated(subset=[“age”], keep=False)])形式取到值为Ture的值,拿到重复的值。
-
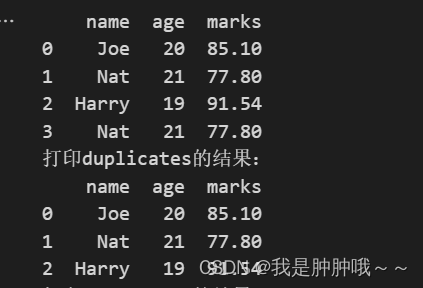
drop_duplicates():返回的是一个新的DataFrame数组,返回的数组就是duplicated中False的部分,直接获取到数据。
- 参数:
- keep: 删除重复项并保留第一次出现的项(参数值:first,last,FALSE)
- inplace:是否在原数据上更改值,默认为FALSE
- subset:用来指定特定的列,按照指定列去去重
附上代码:
from distutils.command.build_scripts import first_line_re
import pandas as pd
student_dict = {"name": ["Joe", "Nat", "Harry", "Nat"], "age": [20, 21, 19, 21], "marks": [85.10, 77.80, 91.54, 77.80]}
# 将字典格式的数据转成pandas中的dataframe形式,方便使用pandas操作数据
student = pd.DataFrame(student_dict)
print(student)
print("打印duplicates的结果:")
print(student.drop_duplicates(subset=["age"]))
print("打印duplicated的结果:")
print(student.duplicated(subset=["age"], keep=False))
print(student[student.duplicated(subset=["age"], keep=False)])
quchong_df = student[student.duplicated(subset=["age"], keep=False)]
print("quchong_df 后的学生信息:")
print(quchong_df )















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









