







内核与操作系统
内核是操作系统的核心部分,包含了系统运行的核心过程,决定系统的性能,操作系统启动内核被装入到RAM中;
操作系统与底层硬件设备交互和为运行应用程序提供执行环境。
Linux内核与微内核比较:
微内核:内核只需要一个很小的函数集,通常包括几个同步原语,一个简单的调度程序和进程间通信机制。
运行在微内核之上的几个系统进程实现系统级功能:内存分配,设备驱动程序……完全的模块化进程。任何操作系统层都是独立的程序模块,通过模块化的方法定义明确清晰的软件接口与其它层交互。内核中暂且不需要执行的系统进程可以被调出或者撤销。微内核便于移植和充分利用RAM,但开销大效率是个问题。
宏内核:Linux内核:单块结构。内核的全部代码,包括所有子系统(如内存管理、文件系统、设备驱动程序)都打包到一个文件中。内核中的每个函数都可以访问内核中所有其他部分。模块特性依赖于内核与用户层之间设计精巧的通信方法,这使得模块的热插拔和动态装载得以实现。每个内核层都被继承到整个内核程序中,并代表着当前进程在内核态下运行。
模块化(非进程)——允许在运行状态下动态的安装。模块是一个目标文件,其代码在运行时链接到内核或从内核解除链接。目标代码通常是一组函数组成,用来实现文件系统,驱动程序……这些模块与其他静态链接内核函数一样,代表着当前进程在内核态下执行,直接函数调用避免进程切换消息传递的开销,效率可能更高。
Linux用户程序两种状态:
用户态和内核态;用户态切换到内核态:
l 进程系统调用
l CPU异常
l 中断
l 内核线程被执行多用户系统:
能并发执行和独立的执行多个用户的应用程序,各个用户拥有独立空间。用户组,Root用户。
Linux进程:
进程Process:
l 操作系统的基本抽象。
l 进程是程序执行时的一个实例;一个运行程序的执行上下文。
l 几个进程能并发的执行同一个程序;而同一个进程能顺序执行几个程序。
l 具有独立的地址空间;多个进程可以同时执行。进程受内核管理;每个进程由一个进程描述符表示,包含进程当前的状态信息。
当内核暂停一个进程的执行时,就把几个相关处理器寄存器的内容保存在进程描述符中。这些寄存器包括:
l 程序计数器PC和栈指针SP寄存器
l 通用寄存器
l 浮点寄存器
l 包含CPU状态信息的处理控制寄存器
l 跟踪进程对RAM访问的内存管理寄存器 当内核恢复执行进程时:将进程描述符中合适字段来装在CPU寄存器,根据程序计数器指向恢复到程序执行的地方。
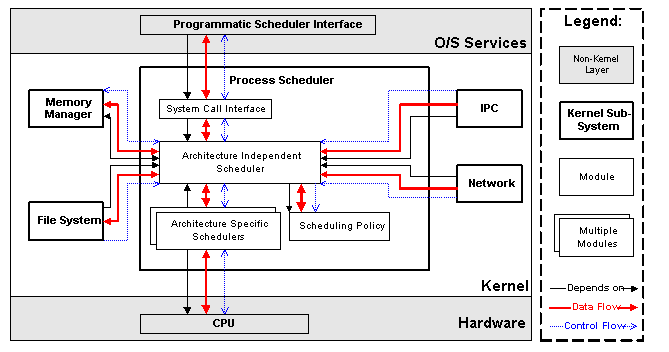
Linux重入内核:
内核可重入:
可重入函数:使用局部变量
实现同步机制:信号量、锁、关中断
进程执行状态切换: 进程在用户态与内核态的转换,Linux是抢占式内核
进程地址空间:每个进程运行在似有地址空间
同步和临界区:内核数据操作访问。
进程间通信IPC:信号量、消息队列、共享内存
进程管理:fork与_exit,exec(),子进程与父进程Linux文件系统:
文件系统是对存储设备上的数据和元数据进行组织的机制,以树形结构组织。
文件类型:
不同文件
目录
符号链接
面向块得设备文件 (设备驱动相关)
面向字符的设备文件 (设备驱动相关)
管道(pipe)和命名管道(named pipe)(进程间通信相关)
套接字(socket) (进程间通信相关)
文件访问权限和访问模式
文件描述符和索引节点:记录文件的信息数据。
文件操作的系统调用:open、read、write……
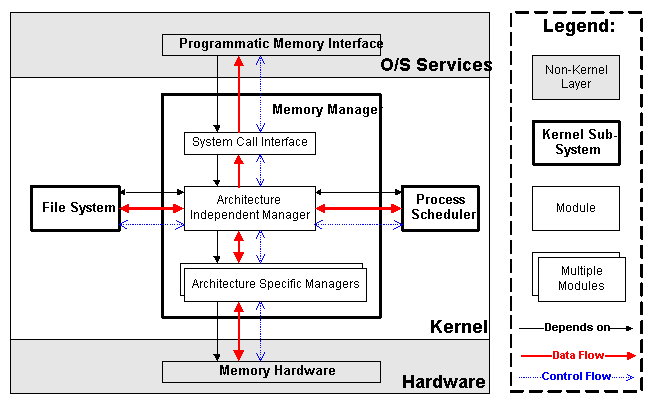
内存管理:
虚拟内存:处于应用程序内存请求与硬件内存单元之间的逻辑层。
随即访问存储器RAM:一部分用于内核映像,其余虚拟内存处理
内核内存分配器:KMA 处理内存请求子系统
l 速度快
l 减少内存浪费
l 减轻内存碎片
l 与其他内存管理合作(页框)
l 内存分配算法进程虚拟空间地址处理:内核分配给进程的虚拟地址空间由以下内存区组成:
l 程序的可执行代码
l 程序的初始化数据
l 程序未初始化数据
l 初始化程序栈
l 所需共享库的可执行代码和数据
l 程序动态请求的内存堆高速缓存:
设备驱动程序:
内核通过设备驱动程序与I/O设备交互,设备驱动程序在内核中,用户程序通过内核访问设备。
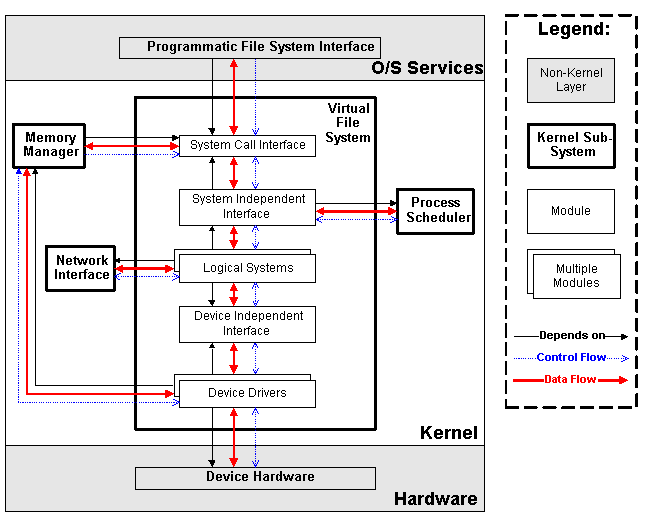
进程
一 进程与线程
进程就是处于执行期的程序,包含了独立地址空间,多个执行线程等资源。
线程是进程中活动的对象,每个线程都拥有独立的程序计数器、进程栈和一组进程寄存器。
内核调度的对象是线程而不是进程。对Linux而言,线程是特殊的进程。
二 进程描述符及任务结构
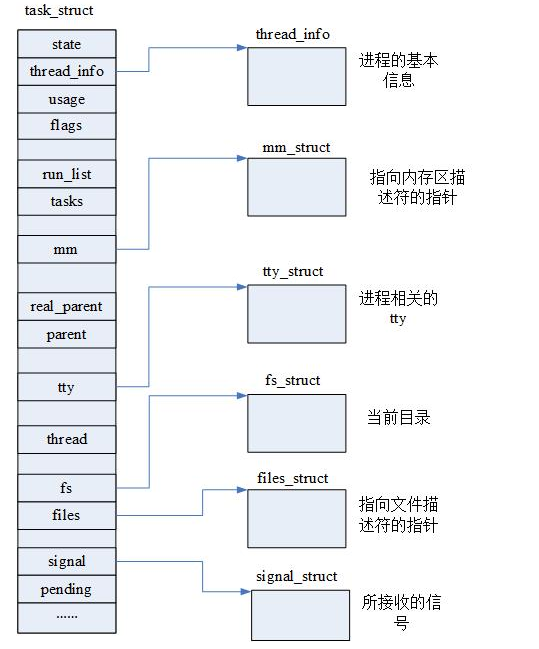
内核使用双向循环链表的任务队列来存放进程,使用结构体task_struct来描述进程所有信息。
1 进程描述符task_struct
struct task_struct {}结构体相当大,大约1.7K字节。大概列出一些看看:
struct task_struct {
//这个是进程的运行时状态,-1代表不可运行,0代表可运行,>0代表已停止。
volatile long state;
/*
flags是进程当前的状态标志,具体的如:
0x00000002表示进程正在被创建;
0x00000004表示进程正准备退出;
0x00000040 表示此进程被fork出,但是并没有执行exec;
0x00000400表示此进程由于其他进程发送相关信号而被杀死 。
*/
unsigned int flags;
//表示此进程的运行优先级
unsigned int rt_priority;
//这里出现了list_head结构体
struct list_head tasks;
//这里出现了mm_struct 结构体,该结构体记录了进程内存使用的相关情况,详情请参考
struct mm_struct *mm;
/* 接下来是进程的一些状态参数*/
int exit_state;
int exit_code, exit_signal;
//这个是进程号
pid_t pid;
//这个是进程组号
pid_t tgid;
//real_parent是该进程的”亲生父亲“,不管其是否被“寄养”。
struct task_struct *real_parent;
//parent是该进程现在的父进程,有可能是”继父“
struct task_struct *parent;
//这里children指的是该进程孩子的链表,可以得到所有孩子的进程描述符,但是需使用list_for_each和list_entry,list_entry其实直接使用了container_of,详情请参考
struct list_head children;
//同理,sibling该进程兄弟的链表,也就是其父亲的所有孩子的链表。用法与children相似。
struct list_head sibling;
//这个是主线程的进程描述符,也许你会奇怪,为什么线程用进程描述符表示,因为linux并没有单独实现线程的相关结构体,只是用一个进程来代替线程,然后对其做一些特殊的处理。
struct task_struct *group_leader;
//这个是该进程所有线程的链表。
struct list_head thread_group;
//顾名思义,这个是该进程使用cpu时间的信息,utime是在用户态下执行的时间,stime是在内核态下执行的时间。
cputime_t utime, stime;
//下面的是启动的时间,只是时间基准不一样。
struct timespec start_time;
struct timespec real_start_time;
//comm是保存该进程名字的字符数组,长度最长为15,因为TASK_COMM_LEN为16。
char comm[TASK_COMM_LEN];
/* 文件系统信息计数*/
int link_count, total_link_count;
/*该进程在特定CPU下的状态*/
struct thread_struct thread;
/* 文件系统相关信息结构体*/
struct fs_struct *fs;
/* 打开的文件相关信息结构体*/
struct files_struct *files;
/* 信号相关信息的句柄*/
struct signal_struct *signal;
struct sighand_struct *sighand;
/*这些是松弛时间值,用来规定select()和poll()的超时时间,单位是纳秒nanoseconds */
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
};
2 分配进程描述符
当进程由于中断或系统调用从用户态转换到内核态时,进程所使用的栈也要从用户栈切换到内核栈。通过内核栈获取栈尾thread_info,就可以获取当前进程描述符task_struct。每个进程的thread_info结构在他的内核栈的尾端分配。结构中task域中存放是指向该任务实际的task_struct。
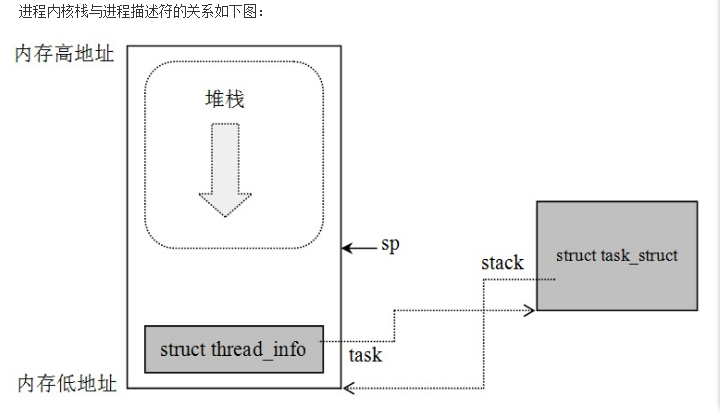
内核处理进程就是通过进程描述符task_struct结构体对象来操作。所以操作进程要获取当前正在运行的进程描述符。通过thread_info的地址就可以找到task_struct地址;在不同的体系结构上计算thread_info的偏移地址不同。
/* linux-2.6.38.8/arch/arm/include/asm/current.h */
static inline struct task_struct *get_current(void)
{
return current_thread_info()->task;
}
`
#define current (get_current())
/* linux-2.6.38.8/arch/arm/include/asm/thread_info.h */
static inline struct thread_info *current_thread_info(void)
{
//栈指针
register unsigned long sp asm ("sp");
return (struct thread_info *)(sp & ~(THREAD_SIZE - 1));
}
3 进程的状态
系统中的每个进程都必然处于五种进程状态中的一种或进行切换。该域的值也必为下列五种状态标志之一:
- TASK_RUNNING(运行)—进程是可执行的;它或者正在执行,或者在运行队列中等待执行(运行队列将会在第4章中讨论)。这是进程在用户空间中执行的唯一可能的状态;这种状态也可以应用到内核空间中正在执行的进程。
- TASK_INTERRUPTIBLE(可中断)—进程正在睡眠(也就是说它被阻塞),等待某些条件的达成。一旦这些条件达成,内核就会把进程状态设置为运行。处于此状态的进程也会因为接收到信号而提前被唤醒并随时准备投入运行。
- TASK_UNINTERRUPTIBLE(不可中断)—除了就算是接收到信号也不会被唤醒或准备投入运行外,这个状态与可打断状态相同。这个状态通常在进程必须在等待时不受干扰或等待事件很快就会发生时出现。由于处于此状态的任务对信号不做响应,所以较之可中断状态,使用得较少。
- __TASK_TRACED—被其他进程跟踪的进程,例如通过ptrace对调试程序进行跟踪。
- __TASK_STOPPED(停止)—进程停止执行;进程没有投入运行也不能投入运行。通常这种状态发生在接收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU等信号的时候。此外,在调试期间接收到任何信号,都会使进程进入这种状态。
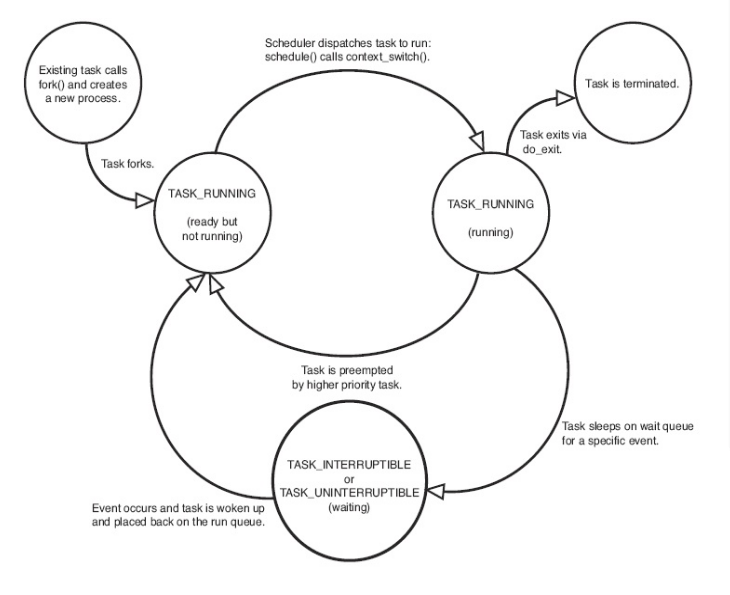
三 进程创建
- fork:copy当前进程创建一个新的进程;
- exec:读取可执行文件并将其载入地址空间开始运行。
1 fork过程
创建进程都是通过调用do_fork函数完成,其中提供了很多参数标志来表明进程创建的方式。
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
……
//创建进程
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
……
//将进程加入到运行队列中
wake_up_new_task(p);
}copy_process里面通过父进程创建子进程,并未执行:
task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
struct task_struct *p;
//创建进程内核栈和进程描述符
p = dup_task_struct(current);
//得到的进程与父进程内容完全一致,初始化新创建进程
……
return p;
}dup_task_struct根据父进程创建子进程内核栈和进程描述符:
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tsk_fork_get_node(orig);
//创建进程描述符对象
tsk = alloc_task_struct_node(node);
//创建进程内核栈 thread_info
ti = alloc_thread_info_node(tsk, node);
//使子进程描述符和父进程一致
err = arch_dup_task_struct(tsk, orig);
//进程描述符stack指向thread_info
tsk->stack = ti;
//使子进程thread_info内容与父进程一致但task指向子进程task_struct
setup_thread_stack(tsk, orig);
return tsk;
}创建进程copy_process之后并未执行,返回到do_fork中,将新创建进程加入到运行队列中等待被执行。
四 线程在Linux中的实现与内核线程
线程机制提供了在同一个程序共享内存地址空间,文件等资源的一组线程。在Linux内核中把所有线程都当做进程来实现。
内核并没有提供调度算法,或者数据结构来表征线程,而是作为与其他进程共享资源的进程;与其他系统不同。
内核线程与普通进程间的区别是:
内核线程没有独立的地址空间
只在内核空间运行,不会切换到用户空间
五 进程终结
进程终结时内核释放其所占有的资源,并告诉父进程,更新父子关系。调用exit终结进程,进程被终结时通常最后都要调用do_exit来处理。
void do_exit(long code)
{
//获取当前运行进程
struct task_struct *tsk = current;
……
//sets PF_EXITING
exit_signals(tsk);
//释放task_struct的mm_struct内存
exit_mm(tsk);
//退出接收IPC信号队列
exit_sem(tsk);
//进程名字空间
exit_shm(tsk);
//文件描述符
exit_files(tsk);
//文件系统
exit_fs(tsk);
//资源释放
exit_thread();
//向父进程发送信号
exit_notify(tsk, group_dead);
……
//切换到其他进程
tsk->state = TASK_DEAD;
tsk->flags |= PF_NOFREEZE;
schedule();
……
} 进程调度:
在可运行态进程之间分配有限处理器时间资源的内核子系统。
一 调度策略
1 进程类型
I/O消耗型进程:大部分时间用来提交I/O请求或是等待I/O请求,经常处于可运行状态,但运行时间短,等待请求过程时处于阻塞状态。如交互式程序。
处理器消耗型进程:时间大都用在执行代码上,除非被抢占否则一直不停的运行。
综合型:既是I/O消耗型又是处理器消耗型。
调度策略要在:进程响应迅速(响应时间短)和最大系统利用率(高吞吐量)之间寻找平衡。
2 调度概念
优先级:基于进程价值和对处理器时间需求进行进程分级的调度。
时间片:表明进程被抢占前所能持续运行的时间,规定一个默认的时间片。时间片过长导致系统交互性的响应不好,程序并行性效果差;时间片太短增大进程切换带来的处理器耗时。矛盾!
时间片耗尽进程运行到期,暂时不可运行状态。直到所有进程时间片都耗尽,重新计算进程时间片。
Linux调度程序提高交互式程序优先级,提供较长时间片;实现动态调整优先级和时间片长度机制。
进程抢占:Linux系统是抢占式,始终运行优先级高的进程。
3 调度算法
可执行队列:runqueue;给定处理器上可执行进程的链表,每个处理器一个。每个可执行进程都唯一归属于一个可执行队列。
运行队列是调度程序中最基本的数据结构:
struct runqueue {
spinlock_t lock; /* 保护运行队列的自旋锁*/
unsigned long nr_running; /* 可运行任务数目*/
unsigned long nr_switches; /* 上下文切换数目*/
unsigned long expired_timestamp; /* 队列最后被换出时间*/
unsigned long nr_uninterruptible; /* 处于不可中断睡眠状态的任务数目*/
unsigned long long timestamp_last_tick; /* 最后一个调度程序的节拍*/
struct task_struct *curr; /* 当前运行任务*/
struct task_struct *idle; /* 该处理器的空任务*/
struct mm_struct *prev_mm; /* 最后运行任务的mm_struct结构体*/
struct prio_array *active; /* 活动优先级队列*/
atomic_t nr_iowait; /* 等待I/O操作的任务数目*/
……
};提供了一组宏来获取给定CPU的进程执行队列:
#define cpu_rq(cpu) //返回给定处理器可执行队列的指针
#define this_rq() //返回当前处理器的可执行队列
#define task_rq(p) //返回给定任务所在的队列指针在操作处理器任务队列时候要用锁:
__task_rq_lock
……
__task_rq_unlock4 schedule
系统要选定下一个执行的进程通过调用schedule函数完成。
调度时机:
l 进程状态转换的时刻:进程终止、进程睡眠;
l 当前进程的时间片用完时(current->counter=0);
l 设备驱动程序调用;
l 进程从中断、异常及系统调用返回到用户态时;睡眠和唤醒:
休眠(被阻塞)的进程处于一个特殊的不可执行状态。休眠有两种进程状态:
TASK_INTERRUPTIBLE:接收到信号就被唤醒
TASK_UNINTERRUPTIBLE:忽略信号
两种状态进程位于同一个等待队列上,等待某些事件,不能够运行。进程休眠策略:
//q是我们希望睡眠的等待队列
DECLARE_WAITQUEUE(wait, current);
add_wait_queue(q, &wait);
//condition 是我们在等待的事件
while (!condition)
{
//将进程状态设为不可执行休眠状态 or TASK_UNINTERRUPTIBLE
set_current_state(TASK_INTERRUPTIBLE);
if(signal_pending(current))
//调度进程
schedule();
}
//进程被唤醒条件满足 进程可执行状态
set_current_state(TASK_RUNNING);
//将进程等待队列中移除
remove_wait_queue(q, &wait);进程通过执行下面几个步骤将自己加入到一个等待队列中:
1) 调用DECLARE_WAITQUEUE()创建一个等待队列的项。
2) 调用add_wait_queue()把自己加入到队列中。该队列会在进程等待的条件满足时唤醒它。当然我们必须在其他地方撰写相关代码,在事件发生时,对等待队列执行wake_up()操作。
3) 将进程的状态变更为 TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE。
4) 如果状态被置为TASK_INTERRUPTIBLE,则信号唤醒进程。这就是所谓的伪唤醒(唤醒不是因为事件的发生),因此检查并处理信号。
5) 检查条件是否为真;如果是的话,就没必要休眠了。如果条件不为真,调用schedule()。
6) 当进程被唤醒的时候,它会再次检查条件是否为真。如果是,它就退出循环,如果不是,它再次调用schedule()并一直重复这步操作。
7) 当条件满足后,进程将自己设置为TASK_RUNNING并调用remove_wait_queue()把自己移出等待队列。
二 抢占和上下文切换
进程切换schedule函数调用context_switch()函数完成以下工作:
l 调用定义在<asm/mmu_context.h>中的switch_mm(),该函数负责把虚拟内存从上一个进程映射切换到新进程中。
l 调用定义在<asm/system.h>中的switch_to(),该函数负责从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存、恢复栈信息和寄存器信息。在前面看到schedule函数调用有很多种情况,完全依靠用户来调用不能达到很好的效果。内核需要判断什么时候调用schedule,内核提供了一个need_resched标志来表明是否需要重新执行一次调度:
l 当某个进程耗尽它的时间片时,scheduler_tick()就会设置这个标志;
l 当一个优先级高的进程进入可执行状态的时候,try_to_wake_up()也会设置这个标志。每个进程都包含一个need_resched标志,这是因为访问进程描述符内的数值要比访问一个全局变量快(因为current宏速度很快并且描述符通常都在高速缓存中)。1 用户抢占
内核即将返回用户空间时候,如果need_resched标志被设置,会导致schedule函数被调用,此时发生用户抢占。
用户抢占在以下情况时产生:
l 从系统调返回用户空间。
l 从中断处理程序返回用户空间。2 内核抢占
只要重新调度是安全的,那么内核就可以在任何时间抢占正在执行的任务。
什么时候重新调度才是安全的呢?只要没有持有锁,内核就可以进行抢占。锁是非抢占区域的标志。由于内核是支持SMP的,所以,如果没有持有锁,那么正在执行的代码就是可重新导入的,也就是可以抢占的。
为了支持内核抢占所作的第一处变动就是为每个进程的thread_info引入了preempt_count计数器。该计数器初始值为0,每当使用锁的时候数值加1,释放锁的时候数值减1。当数值为0的时候,内核就可执行抢占。从中断返回内核空间的时候,内核会检查need_resched和preempt_count的值。如果need_resched被设置,并且preempt_count为0的话,这说明有一个更为重要的任务需要执行并且可以安全地抢占,此时,调度程序就会被调用。
内核抢占会发生在:
l 当从中断处理程序正在执行,且返回内核空间之前。
l 当内核代码再一次具有可抢占性的时候。
l 如果内核中的任务显式的调用schedule()。
l 如果内核中的任务阻塞(这同样也会导致调用schedule())。 一 用户空间和内核空间
Linux内核将这4G字节虚拟地址空间的空间分为两部分:
l 将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为“内核空间”。
l 将较低的3G字节(从虚拟地址 0x00000000到0xBFFFFFFF),供各个进程使用,称为“用户空间)。
因为每个进程可以通过系统调用进入内核,因此Linux内核由系统内的所有进程共享。于是从具体进程的角度来看,
每个进程可以拥有4G字节的虚拟空间。如此划分提供对系统内核安全保护机制。
系统调用
用户空间的进程和内核空间程序如何进行交互?——系统调用
l 为用户空间提供统一的抽象接口;
l 保证系统的安全访问和稳定;
l 控制进程用户空间与内核空间的切换;1 系统调用的层次关系
Linux内部体系结构:
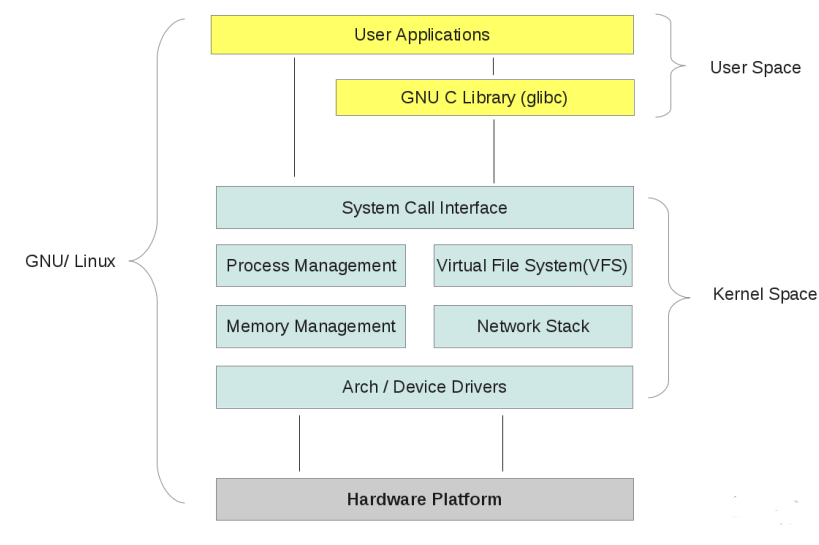
系统调用过程如下:

Unix系统设计理念:提供机制而不是策略
将编程问题分成两个部分:机制(Mechanism)和策略(Policy)。对外应用程序提供接口(系统调用API),而不用去关心如何实现——机制;真正的实现在系统内部,系统提供实现接口算法而不关心如何使用——策略。
2 系统调用程序执行
通知内核的机制是靠软中断实现的:
通过引发一个异常来促使系统切换到内核态去执行异常处理程序。此时的异常处理程序实际上就是系统调用处理程序。
通过异常陷入到内核中,如何执行相应的系统调用:
在x86上, 系统调用号是通过eax寄存器传递给内核的。在陷入内核之前,用户空间就把相应系统调用所对应的号放入eax中了。这样系统调用处理程序一旦运行,就可以从eax中得到数据。
call *sys_call_table(, %eax, 4)
由于系统调用表中的表项是以32位(4字节)类型存放的,所以内核需要将给定的系统调用号乘以4,然后用所得的结果在该表中查询其位置。
通过异常陷入到内核中,如何传递参数给系统调用以及回传给用户空间:
把这些参数也存放在寄存器里。在x86系统上,ebx、ecx、edx、esi和edi按照顺序存放前五个参数。需要六个或六个以上参数的情况不多见,
此时,应该用一个单独的寄存器存放指向所有这些参数在用户空间地址的指针。给用户空间的返回值也通过寄存器传递。在x86系统上,它存放在eax寄存器中。
3 系统调用的实现
一个Linux的系统调用在实现时并不需要太关心它和系统调用处理程序之间的关系。给Linux添加一个新的系统调用是件相对容易的工作。
怎样设计和实现一个系统调用是难题所在,而把它加到内核里却无须太多周折。
实现一个新的系统调用的第一步是决定它的用途。它要做些什么:
每个系统调用都应该有一个明确的用途。在Linux中不提倡采用多用途的系统调用(一个系统调用通过传递不同的参数值来选择完成不同的工作)。
ioctl()就应该被视为一个反例。
新系统调用的参数、返回值和错误码又该是什么:
系统调用的接口应该力求简洁,参数尽可能少。系统调用的语义和行为非常关键;因为应用程序依赖于它们,所以它们应力求稳定,不做改动。
设计接口的时候要尽量为将来多做考虑。你是不是对函数做了不必要的限制:
系统调用设计得越通用越好。不要假设这个系统调用现在怎么用将来也一定就是这么用。系统调用的目的可能不变,
但它的用法却可能改变。这个系统调用可移植吗?别对机器的字节长度和字节序做假设。记住Unix的格言:“提供机制而不是策略”。
添加系统调用要谨慎!
中断推后处理机制
一 中断
硬件通过中断与操作系统进行通信,通过对硬件驱动程序处注册中断处理程序,快速响应硬件的中断。硬件中断优先级很高,打断当前正在执行的程序。有两种情况:
硬件中断在中断处理程序中处理
硬件中断延后再进行处理
这个具体硬件相关,在中断处理程序中处理,打断了当前正在执行的程序;所有中断都将被屏蔽;如果占用时间太长不合适,造成系统交互性,反应能力都会受到影响。 需要在其中判断平衡:
如果一个任务对时间非常敏感,将其放在中断处理程序中执行;
如果一个人和和硬件相关,将其放在中断处理程序中执行;
如果一个任务要保证不被其他中断打断,将其放在中断处理程序中执行;
其余情况考虑延后机制中执行——下半部。
二 中断推后执行机制—— 软中断
软中断是在编译期间静态分配的,在程序执行前将软中断假如到表中。
下面看一下这个过程:
加入软中断类型:
Linux3.5.3代码:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};软中断表:
static struct softirq_action softirq_vec[NR_SOFTIRQS]
软中断结构体
struct softirq_action
{
void (*action)(struct softirq_action *);
};注册软中断处理函数:
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
//关联表中对应类型
softirq_vec[nr].action = action;
}
触发软中断:
void raise_softirq(unsigned int nr)
{
unsigned long flags;
//停止但保存中断标志
local_irq_save(flags);
//将相应软中断挂起状态
raise_softirq_irqoff(nr);
//恢复中断
local_irq_restore(flags);
}执行软中断:
void irq_exit(void)
{
invoke_softirq(); //do_softirq();
}
void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
//获取CPU软中断状态标志位 32位代表最多32个软中断
pending = local_softirq_pending();
restart:
/* Reset the pending bitmask before enabling irqs */
set_softirq_pending(0);
local_irq_enable();
h = softirq_vec;
do {
//被触发则执行软中断处理程序
if (pending & 1) {
h->action(h);
}
//下一个软中断
h++;
//下一个软中断状态标志位
pending >>= 1;
} while (pending);
local_irq_disable();
pending = local_softirq_pending();
if (pending && --max_restart)
goto restart;
if (pending)
wakeup_softirqd();
lockdep_softirq_exit();
__local_bh_enable(SOFTIRQ_OFFSET);
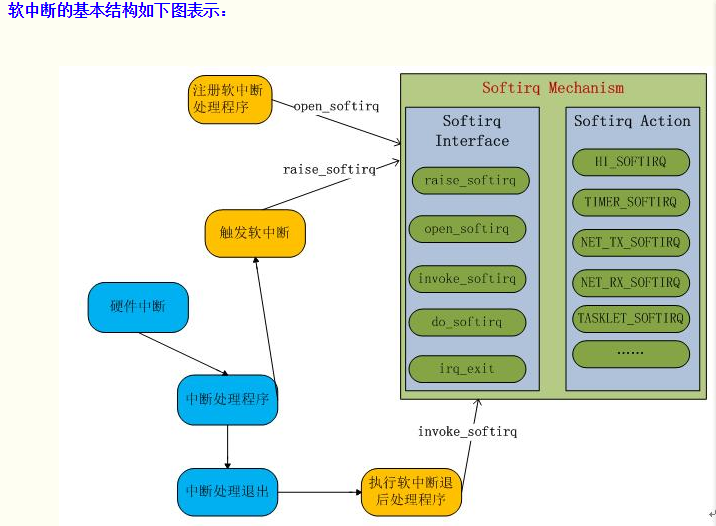
}软中断的基本结构如下图表示:
三 中断推后执行机制——tasklet
软中断中表中有一种类型是:TASKLET_SOFTIRQ
Tasklet就是利用软中断实现中断推后处理机制。通常使用较多的是tasklet而不是软中断。
Tasklet数据结构:
struct tasklet_struct
{
//链表中下一个tasklet
struct tasklet_struct *next;
//tasklet状态
unsigned long state;
//引用计数器
atomic_t count;
//tasklet处理函数
void (*func)(unsigned long);
//处理函数参数
unsigned long data;
};state:
enum
{
TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */
TASKLET_STATE_RUN /* Tasklet is running (SMP only) */
};count:为0允许激活执行
声明tasklet:可以动态或者静态方式
静态:
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }动态:
void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
{
t->next = NULL;
t->state = 0;
atomic_set(&t->count, 0);
t->func = func;
t->data = data;
}同时需要编写tasklet处理函数。
调度tasklet:
void tasklet_hi_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
}执行tasklet处理程序:
继续看上面调度tasklet程序执行:
inline void raise_softirq_irqoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
if (!in_interrupt())
wakeup_softirqd();
}
//使用ksoftirqd内核线程来处理
static void wakeup_softirqd(void)
{
/* Interrupts are disabled: no need to stop preemption */
struct task_struct *tsk = __this_cpu_read(ksoftirqd);
if (tsk && tsk->state != TASK_RUNNING)
wake_up_process(tsk);
}Ksoftirqd内核线程:
软中断才被触发频率很高,在处理过程中还会重新触发软中断;执行会导致用户空间进程无法获得处理时间处于饥饿状态;
对重新触发的软中断立即处理,会导致占据处理时间过长;不进行立即处理不合适;
对此解决方法:
l 只要还有被触发并等待处理和过程中重新触发的软中断的软中断,本次执行就要负责处理;软中断立即处理,用户空间得不到执行时间。
l 不处理过程中触发的软中断,放到下一个中断执行时机时处理。软中断得不到立即处理,系统空闲时造成不合理;保证用户空间得到执行时间。两种方式有存在问题,只能在这其中采取这种的方式:
内核使用线程处理软中断,线程优先级较低,可以被抢占;能够保证软中断被处理,也能保证用户空间程序得到执行时间。
每个CPU上有存在这样一个线程:ksoftirqd/0或者ksoftirqd/1……
static __init int spawn_ksoftirqd(void)
{
void *cpu = (void *)(long)smp_processor_id();
int err = cpu_callback(&cpu_nfb, CPU_UP_PREPARE, cpu);
……
return 0;
}
early_initcall(spawn_ksoftirqd);
static int __cpuinit cpu_callback(struct notifier_block *nfb,
unsigned long action,
void *hcpu)
{
int hotcpu = (unsigned long)hcpu;
struct task_struct *p;
switch (action) {
case CPU_UP_PREPARE:
case CPU_UP_PREPARE_FROZEN:
p = kthread_create_on_node(run_ksoftirqd,
hcpu,
cpu_to_node(hotcpu),
"ksoftirqd/%d", hotcpu);
kthread_bind(p, hotcpu);
per_cpu(ksoftirqd, hotcpu) = p;
break;
……
}四 中断推后执行机制——工作队列
工作队列(work queue)通过内核线程将中断下半部分程序推后执行到线程中执行,工作队列可以创建线程来处理相应任务。
工作队列创建的线程为工作者线程:worker thread;系统提供默认的线程来处理工作者队列。
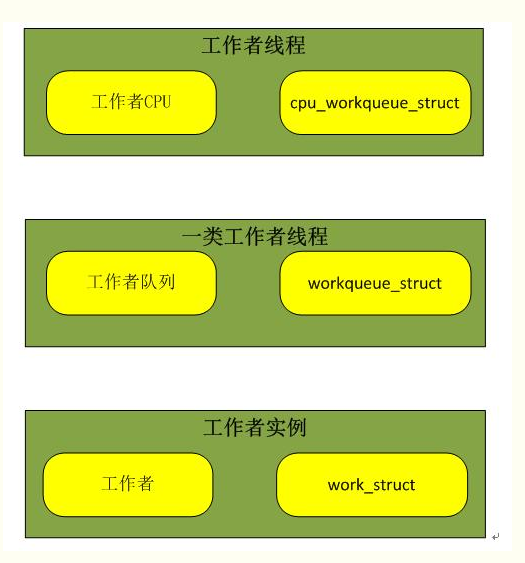
工作者线程数据结构:
struct workqueue_struct {
unsigned int flags; /* W: WQ_* flags */
union {
struct cpu_workqueue_struct __percpu *pcpu;
struct cpu_workqueue_struct *single;
unsigned long v;
} cpu_wq; /* I: cwq's */
struct list_head list; /* W: list of all workqueues */
……
}CPU工作队列数据结构:
struct cpu_workqueue_struct {
//每个CPU工作队列信息
struct global_cwq *gcwq;
//每个CPU工作队列
struct workqueue_struct *wq;
……
};工作数据结构:
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
};声明工作队列:
静态:
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f) 动态:
#define INIT_WORK(_work, _func) \
do { \
__INIT_WORK((_work), (_func), 0); \
} while (0)
需要编写工作队列处理函数:
typedef void (*work_func_t)(struct work_struct *work);调度工作队列:
int schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
{
ret = queue_work_on(get_cpu(), wq, work);
}唤醒工作者队列线程处理。
执行工作者队列处理程序:
static int worker_thread(void *__worker)
{
do {
struct work_struct *work =
list_first_entry(&gcwq->worklist,
struct work_struct, entry);
process_one_work(worker, work);
} while (keep_working(gcwq));
}可以创建新的工作者队列和线程来处理。
平衡是个很关键的问题!
内核同步机制和实现方式
一 原子操作
指令以原子的方式执行——执行过程不被打断。
1 原子整数操作
原子操作函数接收的操作数类型——atomic_t
//定义
atomic_t v;
//初始化
atomic_t u = ATOMIC_INIT(0);
//操作
atomic_set(&v,4); // v = 4
atomic_add(2,&v); // v = v + 2 = 6
atomic_inc(&v); // v = v + 1 = 7
//实现原子操作函数实现
static inline void atomic_add(int i, atomic_t *v)
{
unsigned long tmp;
int result;
__asm__ __volatile__("@ atomic_add\n"
"1: ldrex %0, [%3]\n"
" add %0, %0, %4\n"
" strex %1, %0, [%3]\n"
" teq %1, #0\n"
" bne 1b"
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter)
: "r" (&v->counter), "Ir" (i)
: "cc");
}2 原子位操作
//定义
unsigned long word = 0;
//操作
set_bit(0,&word); //第0位被设置1
set_bit(0,&word); //第1位被设置1
clear_bit(1,&word); //第1位被清空0
//原子位操作函数实现
static inline void ____atomic_set_bit(unsigned int bit, volatile unsigned long *p)
{
unsigned long flags;
unsigned long mask = 1UL << (bit & 31);
p += bit >> 5;
raw_local_irq_save(flags);
*p |= mask;
raw_local_irq_restore(flags);
}二 自旋锁
原子位和原子整数仅能对简单的整形变量进行原子操作,对于复杂的数据复杂的操作并不适用。需要更复杂的同步方法实现保护机制——锁。
自旋锁:同一时刻只能被一个可执行线程持有,获得自旋锁时,如果已被别的线程持有则该线程进行循环等待锁重新可用,然后继续向下执行。
过程如下:
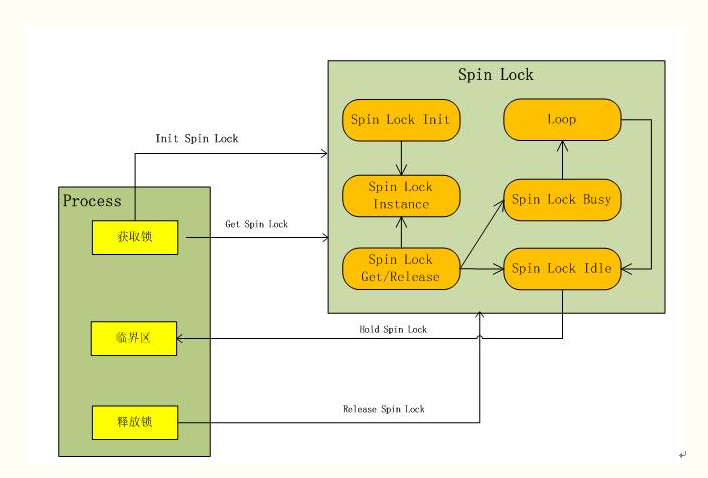
使用锁得基本形式如下:
spinlock_t lock;
//获取锁
spin_lock(&lock);
//临界区
……
//释放锁
spin_unlock(&lock);使用自旋锁防止死锁:
自旋锁不可递归,自旋处于等待中造成死锁;
中断处理程序中,获取自旋锁前要先禁止本地中断,中断会打断正持有自旋锁的任务,中断处理程序有可能争用已经被持有的自旋锁,造成死锁。
读写自旋锁:将锁的用途直接分为读取和写入。
三 信号量
信号量:睡眠锁。如果有一个任务试图获取信号量时,
信号量未被占用:该任务获得成功信号量;
信号量已被占用:信号量将任任务推进等待队列,让其睡眠,处理器继续工作;当信号量被释放后,唤醒信号量队列中的任务,并获取该信号量。
可有读写信号量。
声明信号量:
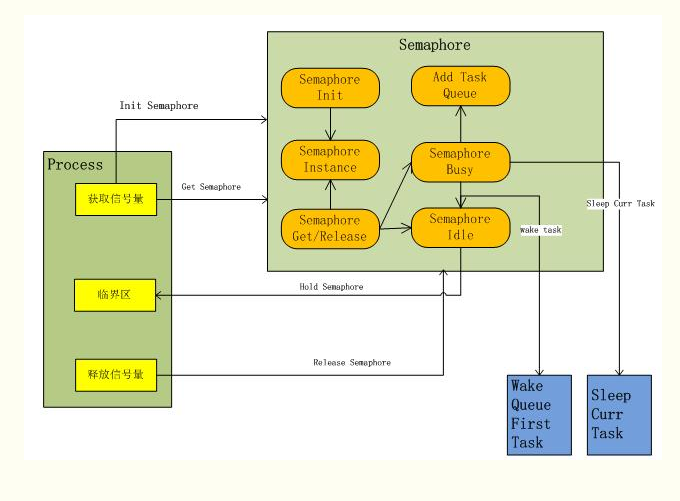
信号量数据结构:
/* Please don't access any members of this structure directly */
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};静态声明信号量:
//声明可用数量为1信号量
#define DEFINE_SEMAPHORE(name) \
struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1)
//声明可用数量为n的信号量
#define __SEMAPHORE_INITIALIZER(name, n) \
{ \
.lock = __RAW_SPIN_LOCK_UNLOCKED((name).lock), \
.count = n, \
.wait_list = LIST_HEAD_INIT((name).wait_list), \
}动态声明信号量:
static inline void sema_init(struct semaphore *sem, int val)
{
static struct lock_class_key __key;
*sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);
lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
}使用信号量:
//初始化定义信号量
struct semaphore driver_lock;
sema_init(&driver_lock, 1);
//获取信号量
if (down_interruptible(&driver_lock))
return -EINTR;
//执行临界区
……
//释放信号量
up(&driver_lock);自旋锁与信号量对比:
需求 使用锁
低开销加锁 : 优先使用自旋锁
短期锁定 : 优先使用自旋锁
长期锁定 : 优先使用信号量
中断上下文加锁 : 使用自旋锁
持有锁需要睡眠 : 使用信号量
四 完成变量
完成变量:如果在内核中一个任务需要发出信号通知另一个任务发生了某个特定事件,使用完成变量去唤醒在等待的任务,使两个任务得以同步。信号量的简易方法。
数据结构:
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
完成变量声明:
动态:#define COMPLETION_INITIALIZER(work) \
{ 0, __WAIT_QUEUE_HEAD_INITIALIZER((work).wait) }
静态: static inline void init_completion(struct completion *x)
{
x->done = 0;
init_waitqueue_head(&x->wait);
}完成变量使用:
//等待制定的完成变量
void __sched wait_for_completion(struct completion *x)
//发信号唤醒等待的任务
void complete(struct completion *x) 还有实现同步机制诸如:禁止抢占,Seq锁(读写共享数据),顺序和屏障
定时器和时间管理
一 内核中的时间观念
内核在硬件的帮助下计算和管理时间。硬件为内核提供一个系统定时器用以计算流逝的时间。系统定时器以某种频率自行触发,产生时钟中断,进入内核时钟中断处理程序中进行处理。
墙上时间和系统运行时间根据时钟间隔来计算。
利用时间中断周期执行的工作:
更新系统运行时间;
更新实际时间;
在smp系统上,均衡调度程序中各处理器上运行队列;
检查当前进程是否用尽了时间片,重新进行调度;
运行超时的动态定时器;
更新资源消耗和处理器时间的统计值;
二 节拍率
系统定时器的频率;通过静态预处理定义的——HZ;系统启动按照HZ值对硬件进行设置。体系结构不同,HZ值也不同;HZ可变的。
//内核时间频率
#define HZ 1000提高节拍率中断产生更加频繁带来的好处:
提高时间驱动事件的解析度;
提高时间驱动事件的准确度;
内核定时器以更高的频度和准确度;
依赖顶上执行的系统调用poll()和select()能更高的精度运行;
系统时间测量更精细;
提高进程抢占的准确度;提高节拍率带来的副作用:
中断频率增高系统负担增加;
中断处理程序占用处理器时间增多;
频繁打断处理器高速缓存;节拍率HZ值需要在其中进行平衡。
三 jiffies
jiffies:全局变量,用来记录自系统启动以来产生的节拍总数。启动时内核将该变量初始化为0;此后每次时钟中断处理程序增加该变量的值。每一秒钟中断次数HZ,jiffies一秒内增加HZ。系统运行时间 = jiffie/HZ.
jiffies用途:计算流逝时间和时间管理
jiffies内部表示:
extern u64 jiffies_64;
extern unsigned long volatile jiffies; //位长更系统有关32/64 32位:497天后溢出
64位:……
//0.5秒后超时
unsigned long timeout = jiffies + HZ/2;
……
//注意jiffies值溢出回绕用宏time_before 而非 直timeout > jiffies
if(time_before(jiffies,timeout)){
//没有超时
}else{
//超时
}四 硬时钟和定时器
两种设备进行计时:系统定时器和实时时钟。
实时时钟(RTC):用来持久存放系统时间的设备,即便系统关闭后,靠主板上的微型电池提供电力保持系统的计时。
系统启动内核通过读取RTC来初始化墙上时间,改时间存放在xtime变量中。
系统定时器:内核定时机制,注册中断处理程序,周期性触发中断,响应中断处理程序,进行处理执行以下工作:
l 获得xtime_lock锁,访问jiffies和更新墙上时间xtime;
l 更新实时时钟;
l 更新资源统计值:当前进程耗时,系统时间等;
l 执行已到期的动态定时器;
l 执行scheduler_tick()//中断处理程序
irqreturn_t timer_interrupt(int irq, void *dev)
{
//ticks have passed
long nticks;
xtime_update(nticks);
while (nticks--)
update_process_times(user_mode(get_irq_regs()));
return IRQ_HANDLED;
}
void xtime_update(unsigned long ticks)
{
//seq锁
write_seqlock(&xtime_lock);
do_timer(ticks);
write_sequnlock(&xtime_lock);
}
void do_timer(unsigned long ticks)
{
jiffies_64 += ticks;
//更新墙上时间 ——实际时间
update_wall_time();
calc_global_load(ticks);
}
void update_process_times(int user_tick)
{
struct task_struct *p = current;
//计算当前进程执行时间
account_process_tick(p, user_tick);
//触发软中断TIMER_SOFTIRQ 超时的timer
run_local_timers();
//计算进程时间片
scheduler_tick();
}五 定时器
定时器:管理内核时间的基础,推后或执行时间执行某些代码。
定时器数据结构:
struct timer_list {
struct list_head entry;
//定时值基于jiffies
unsigned long expires;
//定时器内部值
struct tvec_base *base;
//定时器处理函数
void (*function)(unsigned long);
//定时器处理函数参数
unsigned long data;
……
};定时器使用:
struct timer_list my_timer;
//初始化定时器
init_timer(&my_timer);
……
//激活定时器
add_timer(&my_timer);
//删除定时器
del_timer(my_timer);
……六 延迟执行
使用定时器和下半部机制推迟执行任务。还有其他延迟执行的机制:
忙等待:
利用节拍,精确率不高
unsigned long delay = jiffies + 2*HZ ; //2秒 节拍整数倍才行;
while(time_before(jiffies,delay))
;短延迟:延迟时间精确到毫秒,微妙;短暂等待某个动作完成时,比时钟节拍更短;依靠数次循环达到延迟效果。
void udelay(unsigned long usecs)
void mdelay(unsigned long msecs)schedule_timeout()延迟:使执行的任务睡眠指定时间,达到延迟
signed long __sched schedule_timeout(signed long timeout)
{
struct timer_list timer;
unsigned long expire;
switch (timeout)
{
case MAX_SCHEDULE_TIMEOUT:
//无限期睡眠
schedule();
goto out;
default:
if (timeout < 0) {
current->state = TASK_RUNNING;
goto out;
}
}
//超时时间
expire = timeout + jiffies;
//初始化一个timer定时器 参数current task
setup_timer_on_stack(&timer, process_timeout, (unsigned long)current);
__mod_timer(&timer, expire, false, TIMER_NOT_PINNED);
schedule();
del_singleshot_timer_sync(&timer);
/* Remove the timer from the object tracker */
destroy_timer_on_stack(&timer);
timeout = expire - jiffies;
out:
return timeout < 0 ? 0 : timeout;
}
static void process_timeout(unsigned long __data)
{
//唤醒被睡眠的任务
wake_up_process((struct task_struct *)__data);
}内核内存管理方式
一 页
内核把物理页作为内存管理的基本单位;内存管理单元(MMU)把虚拟地址转换为物理
地址,通常以页为单位进行处理。MMU以页大小为单位来管理系统中的也表。
32位系统:页大小4KB
64位系统:页大小8KB内核用相应的数据结构表示系统中的每个物理页:
<linux/mm_types.h>
struct page {}内核通过这样的数据结构管理系统中所有的页,因此内核判断一个页是否空闲,谁有拥有这个页,拥有者可能是:用户空间进程、动态分配的内核数据、静态内核代码、页高速缓存……
系统中每一个物理页都要分配这样一个结构体,进行内存管理。
二 区
Linux内存寻址存在问题:
一些硬件只能用某些特定的内存来执行DMA(直接内存访问)
一些体系结构其内存的物理寻址范围必须你寻址范围大得多。这样导致一些内存不能永久映射到内核空间上。通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间。当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射。因此内核空间地址为3~4G,最多只能映射到1G空间的内存,超出1G大小的内存将如何去问呢!
由于存在上述条件的限制。Linux将内核空间地址划分为三个区:
ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。
ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束同样每个区包含众多页,形成不同内存池,按照用途进行内存分配。
用相应的数据结构来表示区:
<linux/mmzone.h>
struct zone {}三 获取页/内存
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)该函数分配2的order次方个连续的物理页,返回指向第一个页的page结构体指针。
void *page_address(const struct page *page)返回指向给定物理页当前所在的逻辑地址
extern unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
extern unsigned long get_zeroed_page(gfp_t gfp_mask);释放:
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);内存的分配可能失败,内存的释放要准确!
1 kmalloc
kmalloc()函数与用户空间malloc一组函数类似,获得以字节为单位的一块内核内存。
void *kmalloc(size_t size, gfp_t flags)
void kfree(const void *objp)分配内存物理上连续。
gfp_t标志:表明分配内存的方式。如:
GFP_ATOMIC:分配内存优先级高,不会睡眠
GFP_KERNEL:常用的方式,可能会阻塞。2 vmalloc
void *vmalloc(unsigned long size)
void vfree(const void *addr)vmalloc()与kmalloc方式类似,vmalloc分配的内存虚拟地址是连续的,而物理地址则无需连续,与用户空间分配函数一致。
vmalloc通过分配非连续的物理内存块,在修正页表,把内存映射到逻辑地址空间的连续区域中,虚拟地址是连续的。是否必须要连续的物理地址和具体使用场景有关。在不理解虚拟地址的硬件设备中,内存区都必须是连续的。通过建立页表转换成虚拟地址空间上连续,肯定存在一些消耗,带来性能上影响。所以通常内核使用kmalloc来申请内存,在需要大块内存时使用vmalloc来分配。
四 slab层
内核中经常进行内存的分配和释放。为了便于数据的频繁分配和回收,通常建立一个空闲链表——内存池。当不使用的已分配的内存时,将其放入内存池中,而不是直接释放掉。
Linux内核提供了slab层来管理内存的分配和释放。
频繁分配和回收必然导致内存碎片,缓存他们.
slab层得设计实现
slab层把不同的对象划分为所谓的高速缓存组。每个高速缓存组存放不同类型的对象。高速缓存划分为slab,slab由一个或多个物理上连续的页组成。每个slab处于三种状态之一:满,部分满,空。
高速缓存,slab,对象之间的关系:
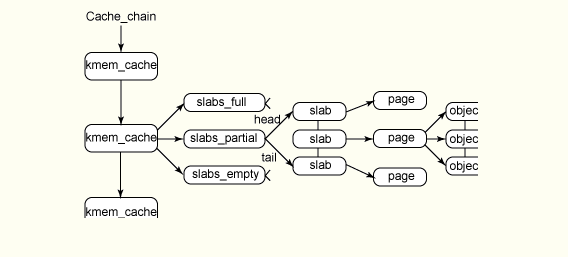
与传统的内存管理模式相比, slab 缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能, 从而避免了常见的碎片问题。slab 分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复
进行初始化。最后,slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
slab数据结构和接口:
每个高速缓存用kmem_cache结构来表示:
struct kmem_cache {
struct kmem_list3 **nodelists;
……
}缓存区包含三种slab:满,未满,空闲
struct kmem_list3 {
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
……
};每一个slab包含多个对象:
struct slab {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
unsigned short nodeid;
};相关接口:mm/slab.c
内核函数 kmem_cache_create 用来创建一个新缓存。这通常是在内核初始化时执行的,或者在首次加载内核模块时执行。
struct kmem_cache *kmem_cache_create (
const char *name,
size_t size,
size_t align,
unsigned long flags,
void (*ctor)(void *))name 参数定义了缓存名称,proc 文件系统(在 /proc/slabinfo 中)使用它标识这个缓存。
size 参数指定了为这个缓存创建的对象的大小,
align 参数定义了每个对象必需的对齐。
flags 参数指定了为缓存启用的选项:
- kmem_cache_create 的部分选项(在 flags 参数中指定)
- SLAB_RED_ZONE 在对象头、尾插入标志,用来支持对缓冲区溢出的检查。
- SLAB_POISON 使用一种己知模式填充 slab,允许对缓存中的对象进行监视(对象属对象所有,不过可以在外部进行修改)。
- SLAB_HWCACHE_ALIGN 指定缓存对象必须与硬件缓存行对齐。
ctor 和 dtor 参数定义了一个可选的对象构造器和析构器。构造器和析构器是用户提供的回调函数。当从缓存中分配新对象时,可以通过构造器进行初始化。要从一个命名的缓存中分配一个对象,可以使用 kmem_cache_alloc 函数。
void kmem_cache_alloc( struct kmem_cache *cachep, gfp_t flags );
这个函数从缓存中返回一个对象。注意如果缓存目前为空,那么这个函数就会调用 cache_alloc_refill 向缓存中增加内存。
kmem_cache_alloc 的 flags 选项与 kmalloc 的cachep:所建立的缓存区
flags参数:
- GFP_USER 为用户分配内存(这个调用可能会睡眠)。
- GFP_KERNEL 从内核 RAM 中分配内存(这个调用可能会睡眠)。
- GFP_ATOMIC 使该调用强制处于非睡眠状态(对中断处理程序非常有用)。
- GFP_HIGHUSER 从高端内存中分配内存。
五 高端内存的映射
永久映射:可能会阻塞
映射一个给定的page结构到内核地址空间:
void *kmap(struct page *page)
解除映射:
void kunmap(struct page *page)
临时映射:不会阻塞
void *kmap_atomic(struct page *page)
六 分配函数的选择
l 连续的物理页:kmalloc或者低级页分配器
l 高端内存分配:alloc_pages 指向page结构指针,不是逻辑地址指针。再通过kmap()把高端地址内存映射到内核的逻辑地址空间。
l 无需连续物理地址:vmalloc 虚拟地址连续物理地址可能不连续,相对存在性能损失
l 频繁创建和销毁很多较大数据结构:建立slab缓存区,提高对象分配和回收性能。
参看资料:
Linux高端内存:
http://ilinuxkernel.com/?p=1013
Linux slab 分配器剖析:
https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/
虚拟文件系统
虚拟文件系统:内核子系统VFS,VFS是内核中文件系统的抽象层,为用户空间提供文件系统相关接口;
通过虚拟文件系统,程序可以利用标准Linux文件系统调用在不同的文件系统中进行交互和操作。
VFS作为抽象层:
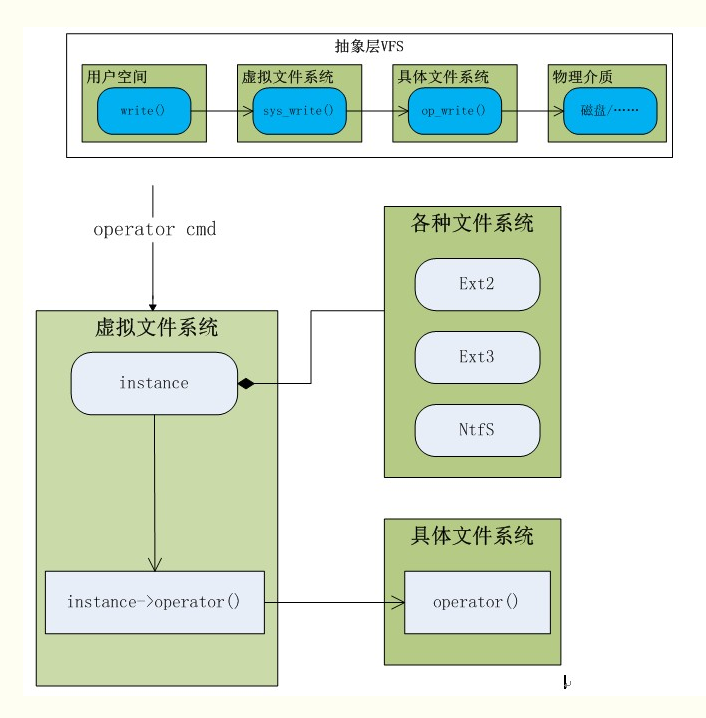
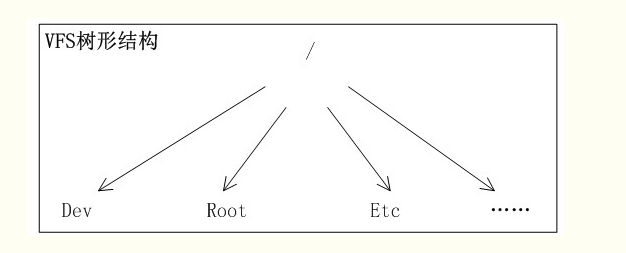
文件系统被安装在一个特定的安装点上,该安装点在全局层次结构中被称作命名空间,所有的已安装文件系统都作为根文件系统树的枝叶出现在系统中。
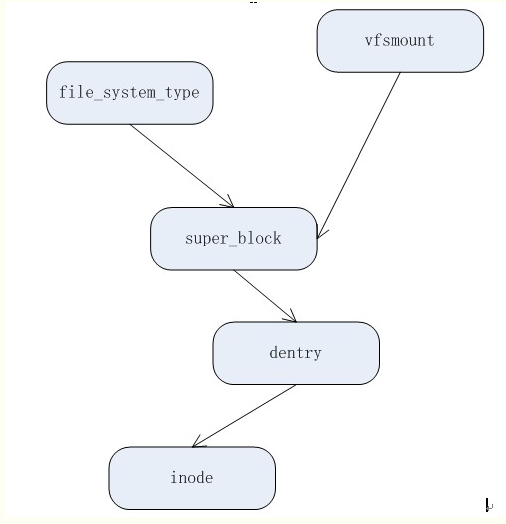
文件系统主要的对象:
超级块对象:代表一个已安装文件系统;struct super_block {}
索引节点对象:代表一个文件;struct inode {}
目录项对象:代表一个目录项,路径的一个组成部分;struct dentry {}
文件对象:进程打开的文件;struct file {}
特定文件系统类型:struct file_system_type {}
安装文件系统的实例:struct vfsmount {}
对象之间的结构关系如下:
Linux 中的 VFS 文件系统机制:
https://www.ibm.com/developerworks/cn/linux/l-vfs/
I/O层和I/O调度机制
一 块I/O基本概念
字符设备:按照字符流的方式被有序访问的设备。如串口、键盘等。
块设备:系统中不能随机(不需要按顺序)访问固定大小的数据片(chunk 块)的设备。
如:硬盘、软盘、CD-ROM驱动器、闪存等。都是通过以安装文件系统的方式使用。
块设备的组成:
扇区:是块设备中最小的可寻址单元(常见大小512字节);是块设备的基本寻址和操作单元。
块:是文件系统最小逻辑可寻址单元,文件系统的抽象,只能通过块访问文件系统。通常包含多个扇区。
当一个块被调入内存时(读入后或等待写出时),它要存储在一个缓冲区中;每个缓冲区与一个块对应,缓冲区相当于是磁盘块在内存中的表示;块大小不超过一个页面,一个页可以容纳一个或多个内存中的块。
缓冲区:是内核操作块设备的逻辑单元,每个缓冲区需要一个描述符来表示块的控相关制信息。
数据结构:缓冲区头 buffer_head,内核操作I/O块基本容器是:bio。操作内核中所有的缓冲区对应的I/O块。
请求队列:块设备将他们挂起的块I/O请求保存在请求队列中。
二 I/O调度机制
简单的以内核产生I/O请求的次序直接将请求发向块设备,造成性能将难以接受。因为磁盘寻址是整个计算机中最慢的操作之一,每一次寻址定位硬盘磁头到特定块上某个位置需要花费不少时间;要提高I/O操作性能,尽量缩短磁盘寻址时间。
在提交请求到块设备前,内核需要对请求进行处理:先执行合并与排序的预操作——I/O调度机制子系统,负责I/O请求的提交。
I/O调度程序管理块设备的请求队列,决定队列中的请求排列顺序,何时派发请求到设备。以减少磁盘寻址时间,提高全局吞吐量。
其实现的方法是合并与排序:
合并:将两个或多个请求结合成一个新的请求,比如访问磁盘扇区相邻时,合并为一个对单个和多个相邻磁盘扇区操作的新请求。合并后仅需要一次请求一条寻址命令。
排序:没有相邻操作扇区请求时,但可能是比较接近的;将整个请求队列按扇区增长方向有序排列,操作时保持磁头以直线一个方向移动,缩短请求磁盘寻址时间。
三 调度程序实现
1 Linus Elevator
当一个请求加入到队列时:
如果队列已存在一个对相邻磁盘扇区操作的请求,将新请求和这个已存在的请求合并成一个请求。
如果队列中存在一个驻留时间过长的请求,将新请求插入到队列尾部,防止请求发生饥饿。
如果队列中以扇区方向为序存在合适插入位置,将新请求插入到该位置,与被访问磁盘物理位置为序排列。
如果队列不存在合适位置插入,将请求插入到队列尾部。
2 最终期限I/O调度程序
Linus Elevator调度程序存在使请求发生饥饿的情况:
l 对某个磁盘区域繁重操作,使得磁盘其他位置上的操作请求得不到运行;
l 同一位置顺序上的请求流可以造成较远位置请求得不到运行;
l 写操作和提交应用程序是异步执行,读操作和提交应用程序是同步执行会阻塞,读操作响应时间影响性能。要在提高全局吞吐量和使请求得到公平处理之间进行平衡。
最终期限I/O调度程序中:每个请求都有一个超时时间,读请求默认500毫秒,写请求5秒。
提交请求时:
一个请求递交给排序队列,按照合并和排序插入队列;
将读请求按次序插入到读FIFO队列中;
将写请求按次序插入到写FIFO队列中;
派发请求时:
通常从排序队列中取队首请求加入到派发队列中;
如果写FIFO队列首或读FIFO队列首请求超时,调度程序从FIFO队列中提取队首请求加入到派发队列中。
如下图所示:
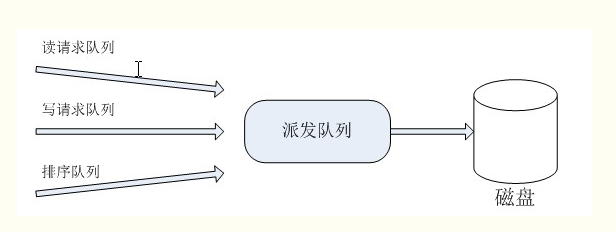
此方式能尽量保证:
请求超时前得到执行,防止请求发生饥饿;
读请求超时时间比写请求短很多,保证写请求不会因为堵塞读请求而使读请求发生饥饿。
3 预测I/O调度程序
最终期限调度程序降低请求发生饥饿的概率,同时降低了系统吞吐量。预测I/O调度程序的目标就是在保持良好读响应同时提供良好的全局吞吐量。
预测I/O调度程序与最终期限调度程序不同之处:请求提交后并不直接放回处理其他请求,而是会空闲片刻(6毫秒),使应用程序有提交其他请求的机会——任何对相邻磁盘位置的操作请求都会立刻得到处理,等待结束后,预测I/O调度程序重新返回原来的位置,继续执行以前的剩下请求。
预测I/O调度程序所能带来的优势取决于能否正确预测应用程序和文件系统的行为,需要启发和统计工作,预测准确能够减少寻址开销,提高系统响应,提高吞吐量。
还有其他调度程序:完全公正的排队I/O调度程序(每个进程独立I/O请求队列)和空操作I/O调度程序(相邻合并)要在提高全局吞吐量和使请求得到公平处理之间进行平衡。系统调度程序再启动时可以进行配置。















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









