







查找出口
当要发送一个报文时,必定要查询发送接口,这个过程被Linux分为3个步骤:
第一个步骤是查询路由cache,
第二个步骤是查询FIB表,
第三步是将查询结果填入路由cache中以便将来查询。
现在来介绍一下路由cache。
路由cache
当确定了一条路由时,路由表项就被放入路由cache中,这意味着一旦知道路由并放入cache后,经过同样路由的报文能够立即找到出口。一个报文在本地机器上可以有一个目的地址,它最终的目的也许是本地可达的主机,也可能被发送到下一跳节点。因此,路由和目的cache被设计成报文目的地址对实际的IP发送过程是透明的,目的cache表项可以和路由cache表项互换。为了指向指向目的cache,同样的dst字段也指向路由表的表项。这让IP用有效的方法检查待发送报文的目的地址,而不用查找路由或显式的检查目的地址是否已经被解析到硬件地址。路由cache可以被看作FIB的子集,它是用来优化已知目的地址的已打开socket的快速路由的。路由cache的实现基于通用的目的地址cache架构,它由hash表组成,每一个表项包含路由表项。这个表可以用简单key完成快速搜索。hash表的实现允许冲突,因为每一个hash表位置可以包含多个路由。IP中的路由cache是一个hash桶(即rt_hash_bucket)的实例,叫rt_hase_table,在此数组中每一个单元包含一个指向路由表的链,每个匹配某目的地址的路由放在一个由链表指向的连接列表中。其基本结构如下:
rt_hash_table和rtable、dst_entry的关系如下图:
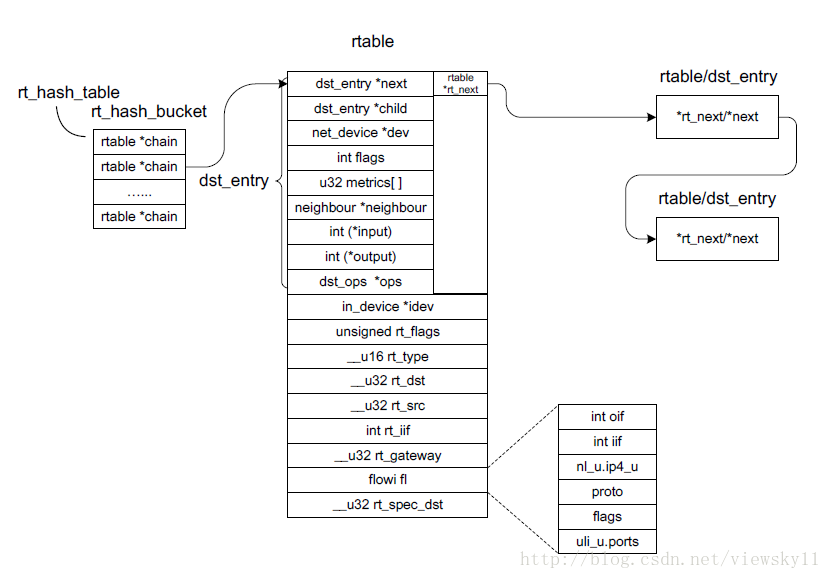
路由表是路由cache中存放每个路由的基本数据结构。本质上它是面向对象的。这是把路由cache看作是来源于通用的目的地址cache功能的原因。例如,sk_buff结构为外发报文包含一个指向目的cache表项的指针,这个dst表项为报文包含一个指向路由cache表项的指针。因此用相似的方法,这个rtable结构定义的首要的几个字段指向目的cache,dst_entry。
struct rtable
{
union
{
struct dst_entry dst;
} u;
struct flowi fl;//包含实际的hash 键
struct in_device *idev;
/*rt_flags能被提供应用程序接口的路由表使用。因为在单个hash桶内也许有多个路由,那么这些路由会冲突。当垃圾回收程序处理这些路由cache,如果和高价值的路由发生冲突时,低价值的路由倾向于被清除出去,路由控制flags决定这些路由的值。*/
unsigned rt_flags;
/*rt_type是这个路由的类型,它确定这些路由是否单播、组播或本地路由*/
__u16 rt_type;
/*rt_dst是IP目的地址,rt_src是IP源地址。Rt_iif是路由输入接口索引*/
__be32 rt_dst;
__be32 rt_src;
int rt_iif;
__be32 rt_gateway;//网关或邻居的IP地址
__be32 rt_spec_dst;
struct inet_peer *peer;
};路由cache的搜索算法:先用一个简单的hash code定位hash桶里的一个slot,然后用一个key去匹配一个指定的路由,这必须遍历这个slot所有的路由列表直到rt_next等于NULL。第二级查找是把rtable表项中的fl字段和收到的报文中的信息进行精确匹配。fl结构包含了能确定某路由的所有信息。
flowi数据结构
这里我们碰到一个奇怪的结构就是flowi。从它的字面上来理解似乎是和“流”有关的一个东西,但源代码中没有对它进行详细解释。而且,BSD协议栈中也没有这么一个结构。那么它到底是什么呢?其实,它就是标识一个发送/接收流的结构,不同用户的业务流之间是如何被内核区别就依靠它。所以,flowi中的i可以理解成identifier。首先,它的结构如下:
struct flowi {
int oif;/*出口设备*/
int iif;/*入口设备*/
__u32 mark;/*mark值*/
/*三层相关的成员,对于ipv4有目的ip地址、源ip地址、tos、scope等*/
union {
struct {
__be32 daddr;
__be32 saddr;
__u8 tos;
__u8 scope;
} ip4_u;
struct {
struct in6_addr daddr;
struct in6_addr saddr;
__be32 flowlabel;
} ip6_u;
struct {
__le16 daddr;
__le16 saddr;
__u8 scope;
} dn_u;
} nl_u;
#define fld_dst nl_u.dn_u.daddr
#define fld_src nl_u.dn_u.saddr
#define fld_scope nl_u.dn_u.scope
#define fl6_dst nl_u.ip6_u.daddr
#define fl6_src nl_u.ip6_u.saddr
#define fl6_flowlabel nl_u.ip6_u.flowlabel
#define fl4_dst nl_u.ip4_u.daddr
#define fl4_src nl_u.ip4_u.saddr
#define fl4_tos nl_u.ip4_u.tos
#define fl4_scope nl_u.ip4_u.scope
__u8 proto;/*四层协议类型与四层协议相关的成员(源、目的端口)等*/
__u8 flags;
#define FLOWI_FLAG_MULTIPATHOLDROUTE 0x01
union {
struct {
__be16 sport;
__be16 dport;
} ports;
struct {
__u8 type;
__u8 code;
} icmpt;
struct {
__le16 sport;
__le16 dport;
} dnports;
__be32 spi;
#ifdef CONFIG_IPV6_MIP6
struct {
__u8 type;
} mht;
#endif
} uli_u;
#define fl_ip_sport uli_u.ports.sport
#define fl_ip_dport uli_u.ports.dport
#define fl_icmp_type uli_u.icmpt.type
#define fl_icmp_code uli_u.icmpt.code
#define fl_ipsec_spi uli_u.spi
#ifdef CONFIG_IPV6_MIP6
#define fl_mh_type uli_u.mht.type
#endif
__u32 secid; /* used by xfrm; see secid.txt */
} __attribute__((__aligned__(BITS_PER_LONG/8)));从上面结构定义可以看到,一个数据报文有源、目的地址端口,有proto选项,有用户定义的类型,甚至有入接口和出接口,那么,通过这些标识,就可以唯一的确定某用户的业务流。然后你就可以对某一个指定的流查找其路由。好啦,可以这么说,路由是网络内不同业务流的标识,而flowi是操作系统内部不同业务流的标识。内核通过从TCP或IP报文头中抽取相应的信息填入到flowi结构中,然后路由查找模块根据这个信息为相应的流找到对应路由。所以说,flowi就是一个查找key。
路由的范围放在flowi结构的scope字段,我们可以想象这个“scope”是到目的地址的距离。它是用来确定如何路由报文和如何归类这些路由。上表的scope值用在fib_result里的scope字段和next_hop结构的fib_nhs里的nh_scope字段,用户创建的特定路由表应用程序可以定义scope的范围是0~199,当前,Linux Ipv4经常使用的是RT_SCOPE_
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2472
2472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









