







如何使用Elasticsearch 设计表结构?
我们知道 ES 是基于索引的设计,它没办法像 MySQL 那样使用 join 查询,所以,查询数据时我们需要把每条主数据及关联子表的数据全部整合在一条记录中
比如 MySQL 中有一个订单数据,使用 ES 查询时,我们会把每条主数据及关联子表数据全部整合在下表中
| 表名 | 作用 | 与订单主表关系 |
|---|---|---|
| order | 订单主表 | 自身 |
| order_invoice | 订单发票 | 1对1 |
| order_product_item | 订单商品详情表 | 1对多 |
| product | 商品表 | 多对多 |
| user | 用户表 | 1对多 |
| ...... | ...... | ...... |
从上表中,我们发现:使用 ES 存储数据时并不会设计多个表,而是将所有表的相关字段数据汇集在一个 Document 中,即一个完整的文档结构,类似这样(此处使用 JSON),代码示例如下
{ "order_id": {
"order_id": "O2020103115214521",
"order_invoice": {},
"user": {
"user_id": "U1099",
"user_name": "吴大侠"
},
"order_product_item": [
{
"product_name": "Redis实战",
"product_count": 1,
"product_price": 149
},
{
"product_name": "铅笔",
"product_count": 2,
"product_price": 1.4
}
],
"total_amount": 20
}ES 的存储结构
ES 是一个分布式的查询系统,它的每一个节点都是一个基于 Lucene 的查询引擎。下面通过 Lucene 和 MySQL 的概念对比,你就能真正理解 Lucene 了
(1)Lucene 和 MySQL 的概念对比
Lucene 是一个索引系统,通过从易到难的方式,我们把 Lucene 与 MySQL 的一些概念简单做映射
| MySQL | lucene |
|---|---|
| 数据库(database) | 索引(Index) |
| 表(table) | Type |
| 行(rows、record) | Document |
| 字段(column) | Field |
| 结果(result) | Hit |
(2)无结构文档的倒排索引(Index)
实际上,Lucene 使用的是倒排索引的结构,具体是什么意思呢?
假如我们有一个无结构的文档,如下表所示
| 文档 id | 文档内容 |
|---|---|
| Doc 1 | 张三和李四是夫妻 |
| Doc 2 | 张无忌和赵敏是一对 |
| Doc 3 | 大师兄,师傅被妖怪捉走了 |
| ..... | ..... |
简单倒排索引后,显示的结果如下表所示
| 字典表(Dictionary) | 倒排表(Posting List) |
|---|---|
| 张三 | Doc 1 |
| 李四 | Doc 2 |
| 和 | Doc 1 -> Doc 2 |
| ... | ... |
无结构的文档经过简单的倒排索引后,字典表主要存放关键字,而倒排表存放该关键字所在的文档 id
(3)有结构文档的倒排索引(Index)
比如每个 Doc 都有多个 Field,Field 有不同的值(包含不同的 Term),倒排索引的结构参考如下图所示

有结构的文档经过倒排索引后,字段中的每个值都是一个关键字,存放在左边的 Term Dictionary(词汇表)中,且每个关键字都有对应地址指向所在文档
(4) ES 的 Document 怎么定义结构和字段格式
从它是基于索引的设计来看,设计 ES Document 结构时,并不需要像 MySQL 那样关联表,而是会把所有相关数据汇集在 1 个 Document 中,接下来看个例子
直接将刚刚 order 的 JSON 文档转成一个 ES 定义文档命令(这里需要注意:SQL 中的子表数据,在 ES 中需要以嵌入式对象的格式存储),代码示例如下
{
"mappings": {
"doc": {
"properties": {
"order_id": {
"type": "text"
},
"order_invoice": {
"type": "nested"
},
"order_product_item": {
"type": "nested",
"properties": {
"product_count": {
"type": "long"
},
"product_name": {
"type": "text"
},
"product_price": {
"type": "float"
}
}
},
"total_amount": {
"type": "long"
},
"user": {
"properties": {
"user_id": {
"type": "text"
},
"user_name": {
"type": "text"
}
}
}
}
}
}
}Elasticsearch如何修改表结构?
在实际业务中,如果你想增加新的字段,ES 支持直接添加,但如果你想修改字段类型或者改名,ES 官方文档里是这样写的
Except for supported mapping parameters, you can’t change the mapping or field type of an existing field. Changing an existing field could invalidate data that’s already Indexed.
If you need to change the mapping of a field in other indices, create a new index with the correct mapping and reIndex your data into that index.
Renaming a field would invalidate data already indexed under the old field name. Instead, add an alias field to create an alternate field name.
因为修改字段的类型会导致索引失效,所以 ES 不支持我们修改原来字段的类型
如果你想修改字段的映射,首先需要新建一个索引,然后使用 ES 的 reindex 功能将旧索引拷贝到新索引中
那什么是 reindex 呢?
reindex 是 ES 自带的 API ,在实际代码中,看下调用示例就能明白它的功用了
POST _reIndex
{
"source": {
"Index": "my-Index-000001"
},
"dest": {
"Index": "my-new-Index-000001"
}
}不过,直接重命名字段时,我们使用 reindex 功能会导致原来保存的旧字段名的索引数据失效,这种情况该如何解决?此时我们可以使用 alias 索引功能,代码示例如下
PUT trips
{
"mappings": {
"properties": {
"distance": {
"type": "long"
},
"route_length_miles": {
"type": "alias",
"path": "distance"
},
"transit_mode": {
"type": "keyword"
}
}
}
}说到修改表结构,使用普通 MySQL 时,并不建议直接修改字段的类型,改名或删字段。因为每次更新版本时,我们都要做好版本回滚的打算,为此设计每个版本对应数据库时,我们会尽量兼容前面版本的代码
因 ES 的结构基于 MySQL 而设计,两者之间存在对应关系,所以也不建议直接修改 ES 的表结构
那如果真有修改的需求呢?一般而言,我们会先保留旧的字段,然后直接添加并使用新的字段,直到新版本的代码全部稳定工作后,我们再找机会清理旧的不用的字段,即分成 2 个版本完成修改需求
ES 的坑有哪些?
- 坑一:ES 是准实时的?
当你更新数据至 ES 且返回成功提示(注意这一瞬间),会发现通过 ES 查询返回的数据仍然不是最新的,背后的原因究竟是什么?这就要求我们对数据索引的整个过程有所了解,且待我们一步步揭开真实的面纱
数据索引整个过程因涉及 ES 的分片,Lucene Index、Segment、 Document 的三者之间关系等知识点,ES 的一个分片就是一个 Lucene Index,每一个 Lucene Index 由多个 Segment 构成,即 Lucene Index 的子集就是 Segment,如下图所示
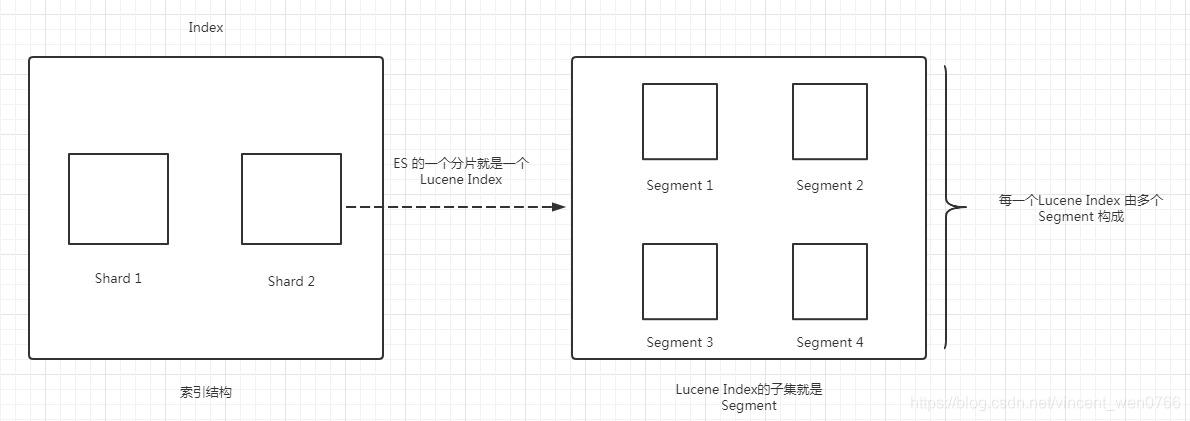
关于 Lucene Index、Segment、 Document 三者之间的关系,你看完下面这张图就一目了然了,如下图所示
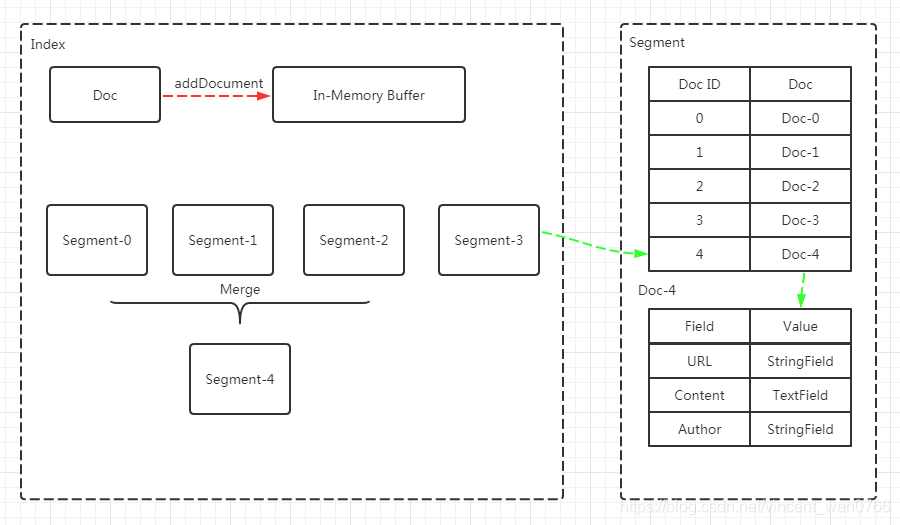
通过上面这个图,知道一个 Lucene Index 可以存放多个 Segment,而每个 Segment 又可以存放多个 Document
数据索引的过程详解
第一步:当新的 Document 被创建,数据首先会存放到新的 Segment 中,同时旧的 Document 会被删除,并在原来的 Segment 上标记一个删除标识。当 Document 被更新,旧版 Document 会被标识为删除,并将新版 Document 存放新的 Segment 中
第二步:Shard 收到写请求时,请求会被写入 Translog 中,然后 Document 被存放 memory buffer (注意:memory buffer 的数据并不能被搜索到)中,最终 Translog 保存所有修改记录
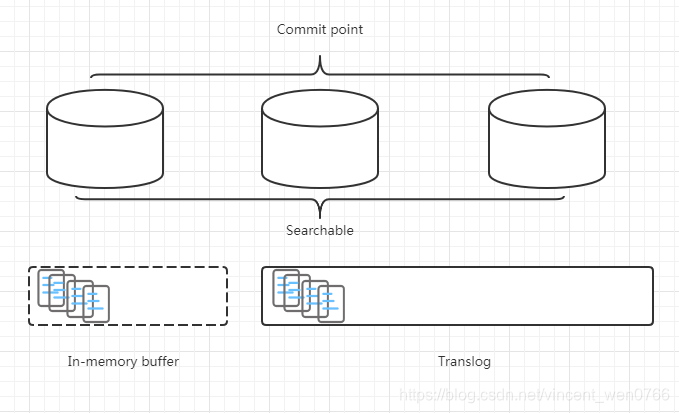
第三步:每隔 1 秒(默认设置),refresh 操作被执行一次,且 memory buffer 中的数据会被写入一个 Segment 并存放 filesystem cache 中,这时新的数据就可以被搜索到了,如下图所示

通过以上数据索引过程的说明,发现 ES 并不是实时的,而是有 1 秒延时,因延时问题的解决方案可以提示用户查询的数据会有一定延时即可
- 坑二:ES 宕机恢复后,数据丢失
在数据索引的过程这部分内容,我们提及了每隔 1 秒(根据配置),memory buffer 中的数据会被写入 Segment 中,此时这部分数据可被用户搜索到,但没有被持久化,一旦系统宕机了,数据就会丢失
比如下图中灰色的桶,目前它可被搜索到,但还没有持久化,一旦 ES 宕机,数据将会丢失
如何防止数据丢失呢?使用 Lucene 中的 commit 操作就能轻松解决这个问题
commit 具体操作:先将多个 Segment 合并保存到磁盘中,再将灰色的桶变成上图中白色的桶
不过,使用 commit 操作存在一点不足:耗 IO,从而引发 ES 在 commit 之前宕机的问题。一旦系统在 translog fsync 之前宕机,数据也会直接丢失,如何保证 ES 数据的完整性便成了亟待解决的问题
遇到这种情况,我们采用 translog 解决就行,因为 Translog 中的数据不会直接保存在磁盘中,只有 fsync 后才保存,这里分享两种 Translog 解决方案
第一种:将 Index.translog.durability 设置成 request ,如果我们发现系统运行得不错,采用这种方式即可;
第二种:将 Index.translog.durability 设置成 fsync,每次 ES 宕机启动后,先将主数据和 ES 数据进行对比,再将 ES 缺失的数据找出来
Translog 何时会 fsync ?
当 Index.translog.durability 设置成 request 后,每个请求都会 fsync,不过这样影响 ES 性能。这时我们可以把 Index.translog.durability 设置成 fsync,那么每隔 Index.translog.sync_interval 后,每个请求才会 fsync 一次
- 坑三:分页越深,查询效率越慢
ES 分页这个坑的出现,与 ES 的读操作请求的处理流程密切关联,为此有必要先深度剖析下 ES 的读操作请求的处理流程,如下图所示
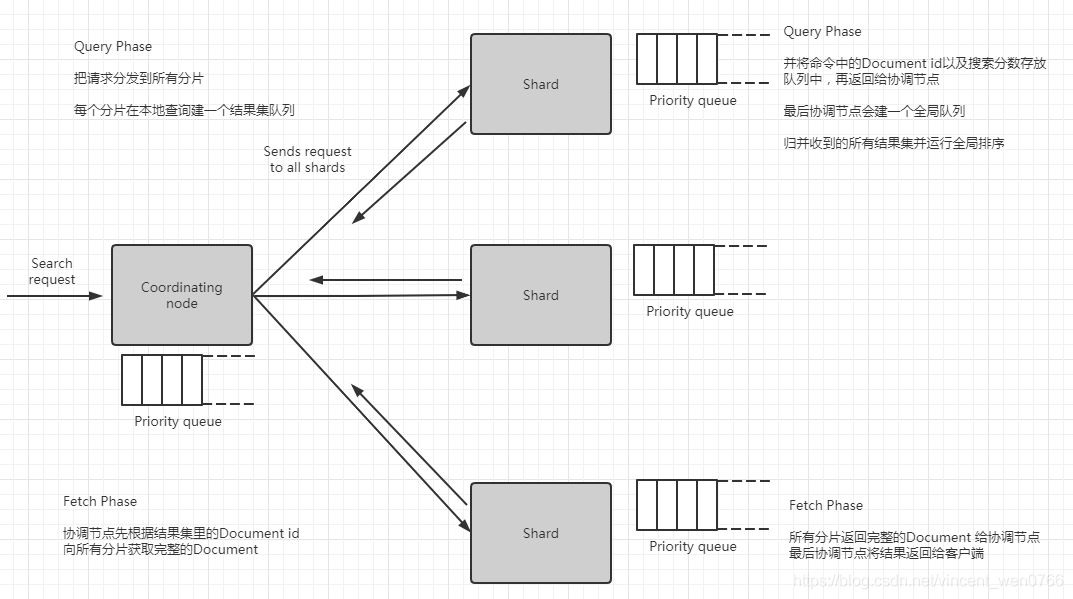
关于 ES 的读操作流程主要分为两个阶段:Query Phase、Fetch Phase
Query Phase: 协调的节点先把请求分发到所有分片,然后每个分片在本地查询建一个结果集队列,并将命令中的 Document id 以及搜索分数存放队列中,再返回给协调节点,最后协调节点会建一个全局队列,归并收到的所有结果集并进行全局排序
Query Phase 强调的是:在 ES 查询过程中,如果 search 带了 from 和 size 参数,Elasticsearch 集群需要给协调节点返回 shards number * (from + size) 条数据,然后在单机上进行排序,最后给客户端返回 size 大小的数据。比如客户端请求 10 条数据(比如 3 个分片),那么每个分片则会返回 10 条数据,协调节点最后会归并 30 条数据,但最终只返回 10 条数据给客户端
Fetch Phase: 协调节点先根据结果集里的 Document id 向所有分片获取完整的 Document,然后所有分片返回完整的 Document 给协调节点,最后协调节点将结果返回给客户端
在整个 ES 的读操作流程中,Elasticsearch 集群实际上需要给协调节点返回 shards number * (from + size) 条数据,然后在单机上进行排序,最后返回给客户端这个 size 大小的数据。比如有 5 个分片,我们需要查询排序序号从 10000 到 10010(from=10000,size=10)的结果,每个分片到底返回多少数据给协调节点计算呢?其实不是 10 条,是 10010 条。也就是说,协调节点需要在内存中计算 10010*5=50050 条记录,所以在系统使用中,如果用户分页越深查询速度会越慢,也就是说并不是分页越多越好
如何更好地解决 ES 分页问题呢?
为了控制性能,我们主要使用 ES 中的 max_result_window 配置,这个数据默认为 10000,当 from+size > max_result_window ,ES 将返回错误
由此可见,在系统设计时,一般需要控制用户翻页不能太深,而这在现实场景中用户也能接受,这也是我之前方案采用的设计方式。要是用户确实有深度翻页的需求,我们再使用 ES 中search_after 的功能也能解决,不过就是无法实现跳页了
举一个例子,查询按照订单总金额分页,上一页最后一条 order 的总金额 total_amount 是 10,那么下一页的查询示例代码如下
{
"query": {
"bool": {
"must": [
{
"term": {
"user.user_name.keyword": "隔壁老王"
}
}
],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 2,
"search_after": [
"10"
],
"sort": [
{
"total_amount": "asc"
}
],
"aggs": {}
}这个 search_after 里的值,就是上次查询结果的排序字段的结果值















 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









