







Abstract
本文挑战背景可能非常复杂的视频运动目标检测。与大部分已有的跟踪器不同,它们只在线学习被跟踪对象的外观,受Deep Learning的启发,我们更加注重(无监督)特征学习。使用辅助的自然图像,我们训练了一个离线的SDAE来学习对变化更加健壮的通用图像特征。然后将离线学习得到的经验用于在线跟踪。在线跟踪涉及分类神经网络,它由SDAE的编码部分作为特征提取器,额外加上一层分类层。特征提取器和分类器可以进一步tune以适应运动目标外观的改变。和目前艺术级跟踪器相比,在一些有挑战性的视频benchmark序列上我们的DL跟踪器更准确,而且当我们的matlab实现在GPU上跑时,计算量低具有实时性能。
1 Introduction
跟踪目标在第一帧中被手动或自动发现之后,视觉跟踪的接下来目标是自动跟踪之后视频帧中目标的运动轨迹(trajectory)。尽管控制好环境背景,已有的机器视觉技术已经提出令人满意的方案,但某些实际应用之中这个问题仍然很有挑战性,比如局部遮挡(
partial occlusion
)、杂乱的背景(
cluttered background
)、快速剧烈的运动、剧烈光照变化和视角的剧变。大部分现有的跟踪器采用
generative or the discriminative方法。通用跟踪器假设目标可以被一些通用手段描述,其动机来自image representation以方便稳定的跟踪。受最近鲁棒估计和稀疏编码的快速算法的启发,出现了
alternating direction method of multipliers (ADMM) and accelerated gradient methods等算法。还有些流行的算法比如基于PCA跟踪的IVT算法、基于完备基向量稀疏结合的L1T算法,类似的拓展还有很多。
有一种方法首先从辅助数据学习得到一个图像特征的字典(比如SIFT局部特征),将之用到在线跟踪上。
尽管许多跟踪器只是用原始像素作为特征,有一些方法使用了信息量更丰富的特征,比如Haar系数、直方图和局部二值化特征,这些特征都是离线手工提取的,但并非特地为跟踪目标而提出的。
本文提出一种新的深度学习跟踪器(DLT),与其他跟踪器相比,DLT有一些关键的不。首先,它使用SDAE从庞大的图像数据库(作为辅助数据)学习通用特征,将学到的特征用到在线追踪任务。第二,不同于先前的从辅助数据中学习特征的方法,在线跟踪的过程中DLT学习到的特征可以进一步调节以适应具体的目标。因为DLT使用了多种非线性变换,因此得到的图像表达比之前基于PCA的方法更具有表现性。此外,represent跟踪目标不需要像之前基于稀疏编码的方法一样解优化,DLT显然更有效率也更适合实时实现。
2 Particle Filter Approach for Visual Tracking
粒子滤波的算法就不讲了,详见“视觉跟踪综述”和“基于粒子滤波的物体跟踪”。本文中,采用深度学习的算法目标就是找出较好的特征作为粒子滤波算法的状态变量(state variable)。
对于目标跟踪,状态变量一般表示为6中仿射变换(
affine transformation
)的参数——平移(横向和纵向)、缩放、宽高比、旋转和偏度(
translation, scale, aspect ratio, rotation, and skewness
)。对每一帧图像来说,跟踪结果是权重最大的粒子。【?很多跟踪器都采用了粒子滤波,各自的主要差别在于观察模型
p(y|si)(和粒子权重计算相关),其中y为图像帧,si为状态变量。】
粒子滤波器是视觉跟踪的主要方法,原因如下。第一,它超越了高斯分布,比卡尔曼滤波更普遍。第二,通过一组粒子它逼近后验状态的分布,而不仅仅通过一个点。对视觉跟踪,这个特点使其便于跟踪器从错误跟踪结果恢复。
3 The DLT Tracker
3.1 Offline Training with Auxiliary Data
3.1.1 Dataset and Preprocessing
使用
Tiny Images dataset作为离线训练的辅助数据,该数据库是使用非抽象英语名词通过7中搜索引擎在网上搜集起来的,涵盖现实世界中很多物体。从80,000,000大小为32*32的图像中我们随机抽取1,000,000,用来离线训练。因为我们要比较的跟踪器只是用灰度图像,我们将所有样本图像转换为灰度图。每幅图想由1024维(1024个像素点)的向量表示,每维的特征值(
像素值
)被线性归一化,此外不做任何预处理。
3.1.2 Learning Generic Image Features with a SDAE
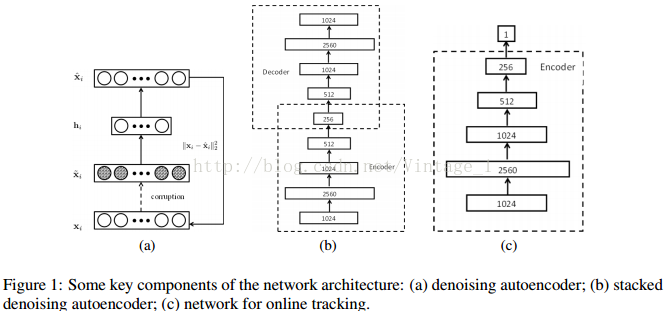
假设总共有k个训练样本,xi表示第i个样本,~xi表示其加噪的版本(掩码(mask)噪声,加性高斯噪声或椒盐噪声)。W和b表示编码器的权值和偏置,W'和b'表示解码器的权值和偏置。DAE可以通过解以下优化问题进行学习,
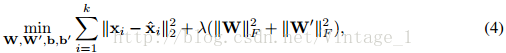
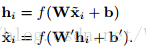
为了进一步学习有意义的特征,对隐藏神经元的激活值施加稀疏性约束。如果使用sigmoid激活函数,那么每个神经元的输出可以看做其激活的概率。让pj表示第j个神经元的目标稀疏性,^pj表示相应的实际(实验,
empirical
)平均激活率。pj和^pj的互熵可以作为额外的惩罚项引入(4)式,
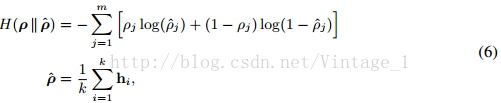
其中m是隐含单元个数。
预训练(指的就是SDAE的训练过程)结束后,SDAE可以展开(其编码器部分用来组成前向神经网络的一部分)。整个网络使用BP算法微调。为了加快收敛速度(
convergence rate
),可以使用简单的动量法或是或更先进的优化方法(比如L-BFGS或共轭梯度法)。
网络结构上,我们在第一层使用过完备滤波器,这是经过深思熟虑的因为过完备基一般能更好地捕获图像结构。然后单元数减少到256个隐藏单元,如Fig1(b)所示。为了加速第一层的预训练以学习局部特征,我们将32*32的小图像分割为5个16*16的patch(左上、右上、右下、左下、中间),然后训练5个DAE,每个DAE含有512个隐含单元。之后,用这5个小的DAE的权值初始化一个大的DAE,然后按一般方法训练大的DAE。下图是一些随机选择的第一层滤波器,

和预期的一样,大部分滤波器
(即每个隐藏节点连接到输入节点的权值:1024维的向量图形化)起边缘检测器的作用。
3.2 Online Tracking Process
跟踪目标在第一帧里用边框框出来。一个sigmoid分类层添加到离线训练好的SDAE的编码器之后,整体网络如Fig1所示。当一个新的视频帧到来,我们首先通过粒子滤波器抽取粒子
(一个粒子就是目标可能存在的一块图像,32*32),每个粒子的可信度通过网络前向传播确定。这种方法在这一步的计算量非常小但准确度很高。如果所有粒子的最大可信度小于预定的阈值,就表示追踪目标的外观发生了巨大改变。为解决这个问题,一旦发生这种情况,这个网络可以再次tune。阈值的设定是一个tradeoff,如果太小,跟踪器不能很好地适应目标的外表变换;如果太大,遮挡物体和背景都有可能被当做跟踪目标,从而造成跟踪从目标漂移。
个人理解:整个过程应该是这样的,第一帧中的框出来的目标,相当于一个粒子,通过神经网络前向传播得到其可信度;之后的图像帧每一帧都采n个粒子,每个粒子可信度通过神经网络计算,最大的那个粒子是目标。相当于,粒子滤波器的状态变量(或说所用的特征)及可信度计算由神经网络来确定,整个方法框架仍然是粒子滤波器,只是粒子滤波器第一步(撒粒子)后的计算可信度的工作由神经网络代劳了。
?加入分类层后的神经网络怎么训练,才能使用整个网络计算粒子可信度?——用第一帧图像框出的粒子通过变换(warp等手段)、并将其可信度设为1或-1,从而得到n个样本,作为加入分类层后的整体网络训练样本。这样,使得网络能够将SDAE提取的特征map到该粒子的可信度。在代码中,第一次训练时用110个样本训练20次,之后就用第一次训练好的网络进行跟踪;如果遇到了3.2中所述的目标外观大幅改变的情况,则用11个样本训练5次来调整网络,在将调整后的网络来进行跟踪。
代码中,通过变换获取样本的方法(warpimg/samplePos_DLT/sampleNeg),是根据仿射变换进行的。仿射变换使用六个仿射参数(code中trackparam_DLT.m的opt.affsig)指示预期的上/下帧图像的变动,用该变换可以根据经验预测下/上帧的图像,从而获取到训练样本。此外,使用DLT跟踪的时候,也先用warpimg预测下一帧的图像,然后从预测的图像中抽取粒子送到神经网络做前向计算得到相应可信度。
4 Experiments
(已有的)跟踪器只能处理灰度视频,所以用MATLAB rgb2gray函数将彩色视频转换为灰色。为了加速运算,我们通过
MATLAB Parallel Computing Toolbox使用
GPU做离线训练和在线跟踪。代码和资料在
http://winsty.net/dlt.html提供。
4.1 DLT Implementation Details
优化采用动量梯度法,动量参数设为0.9。离线训练SDAE,我们注入方差0.0004的高斯噪声来产生受损输入。将(4)式中的lamda设为0.0001,目标稀疏性p设为0.05,训练的batch大小为100。在线tune(遇到3.中最后所述的情况)时将
lamda设为0.002以避免过拟合,并将batch大小设为10。阈值设为0.9,粒子滤波器用1000个粒子。其他的参数比如粒子滤波器的仿射(affine)参数和其他方法中的搜索窗大小,我们采用网格搜索来确定最佳值。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









