







1. 结构
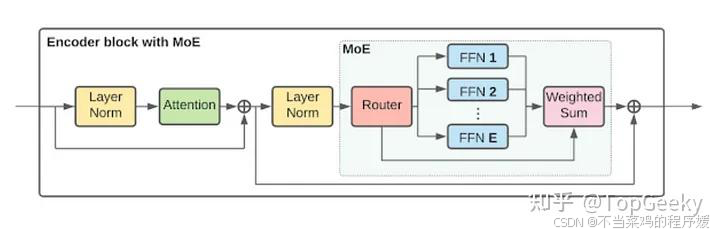
参考知乎图: https://www.zhihu.com/search?type=content&q=MOE的baseline
MoE 之所以脱颖而出,是因为它动态地确定哪个“专家”应该处理给定的输入,这与依赖静态规则来组合输出的传统集成不同。
huggingface写的详细的博客:
混合专家模型(MoE)详解 (huggingface.co)
GateNet:多类的判别模型 此部分用来决定输入的token分发给哪一个专家
GateNet可以理解为一个分配器,根据输入样本的特征,动态决策将其分配给哪个专家进行处理。这个过程可以通过一个softmax分类器来实现,其中每个神经元对应一个专家模型。GateNet的输出值表示了每个专家的权重。
GateNet的设计需要考虑两个关键点:输入样本特征的提取和分配策略的确定。在特征的提取方面,常用的方法是使用卷积神经网络(CNN)或者Transformer等结构来提取输入样本的特征表示。而在分配策略的确定方面,可以采用不同的注意力机制或者引入一些先验知识来指导。
2. MoE实践案例
在语言模型应用过程中,当输入数据通过MoE层的时候,每个token都有GateNet分配在最适合处理的专家模型身上。由于每个专家专注于特定任务,这一方法可以实现计算的高效性。
不仅如此,这种方式允许模型对不同类型的输入数据进行个性化处理,提高了整体效率和性能
Switch transformer:
paper:https://arxiv.org/pdf/2101.03961
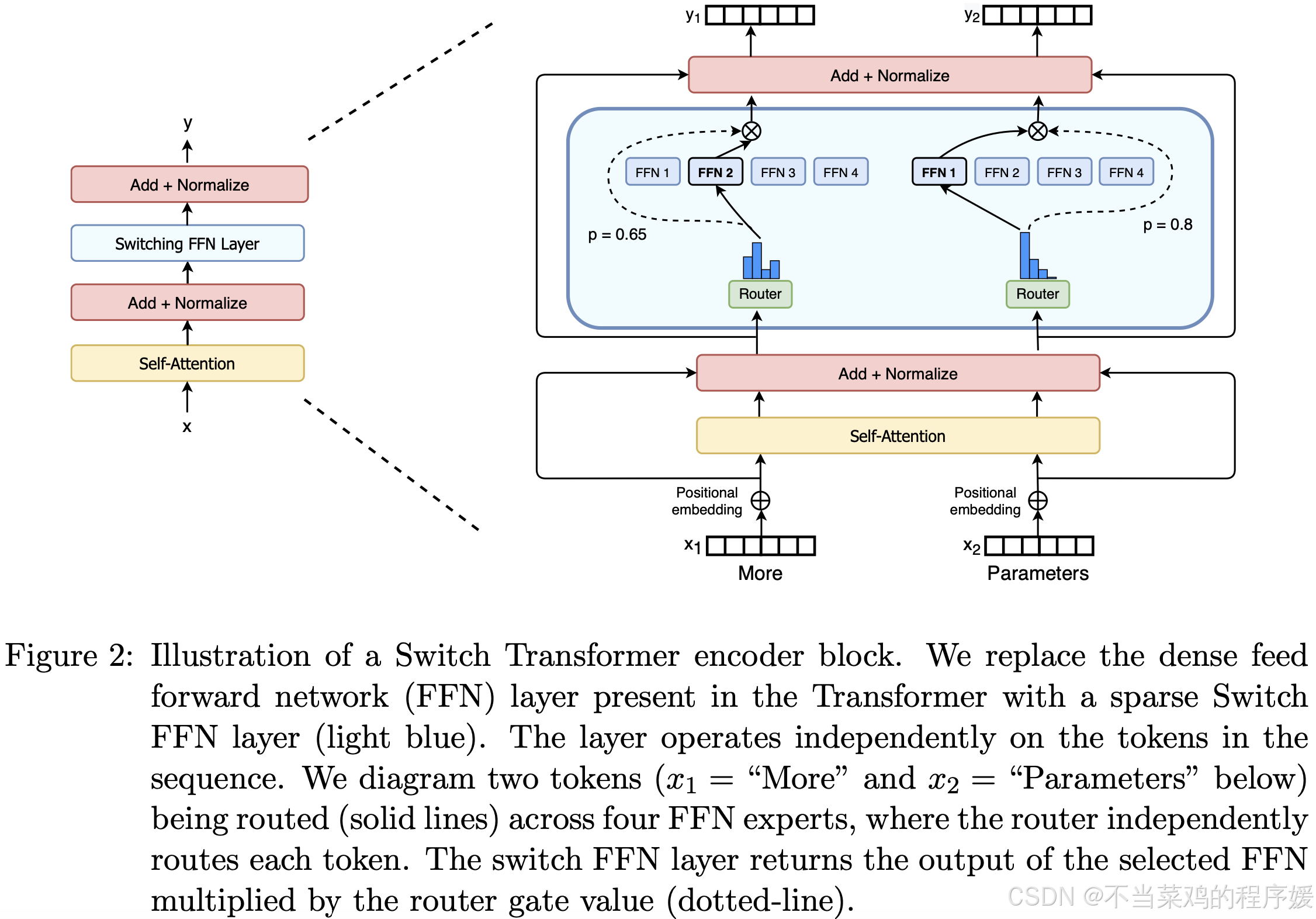
这个从0开始建立MOE是讲的真的好:

















 3253
3253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









