







项目背景:针对一些翻译等应用,用户可能输入不同语种的文本,在进行实际的翻译前,需要对用户输入的语言的语种进行检测。
项目简介: 用sklearn里的朴素贝叶斯模型构建一个语种检测的分类器,并部署。
数据介绍: 主要抓取了来自于twitter、facebook上的数据,包括德语、英语、法语、西班牙语、意大利语和荷兰语共六种语言的数据,经整理后,数据被提取为 句子+标签(即语种)的形式。
一、分类器构建
数据集来自于twitter数据,包含English, French, German, Spanish, Italian 和 Dutch 6种语言。
数据集形如:
1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme,nl
1 millón de afectados ante las inundaciones en sri lanka unicef está distribuyendo ayuda de emergencia srilanka,es
1 millón de fans en facebook antes del 14 de febrero y paty miki dani y berta se tiran en paracaídas qué harías tú porunmillondefans,es
1 satellite galileo sottoposto ai test presso lesaestec nl galileo navigation space in inglese,it
10 der welt sind bei,de
导入数据,规范数据格式
in_f = open('../data/lesson1_data/data.csv')
lines = in_f.readlines()
in_f.close()
dataset = [(line.strip()[:-3], line.strip()[-2:]) for line in lines]
切分训练集和测试集
from sklearn.model_selection import train_test_split
x, y = zip(*dataset)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
用正则表达式去除噪声数据
由于原始数据为来自于twitter和facebook上的数据,其中的“@某人”、”#某主题”、“网址”等数据可能并不能代表使用的语言本身,因此用正则表达式将其从原始数据中去除。
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
\S 匹配任意非空字符
\w 匹配数字字母下划线
import re
def remove_noise(document):
noise_pattern = re.compile("|".join(["http\S+", "\@\w+", "\#\w+"]))
clean_text = re.sub(noise_pattern, "", document)
return clean_text.strip()
remove_noise("Trump images are now more popular than cat gifs. @trump #trends http://www.trumptrends.html")
在降噪数据上抽取1-gram和2-gram的统计特征
from sklearn.feature_extraction.text import CountVectorizer
#from sklearn.feature_extraction.text import TfidfVectorizer
vec = CountVectorizer( # 词袋模型,也可以用TfidfVectorizer
lowercase=True, # 英文文本全小写
analyzer='char_wb', # 逐个字母解析
ngram_range=(1,3), # 1=出现的字母以及每个字母出现的次数,2=出现的连续2个字母,和连续2个字母出现的频次,可以为1-n,实验得出n取值为4时精度最高
# trump images are now... => 1gram = t,r,u,m,p... 2gram = tr,ru,um,mp...
max_features=1000, # keep the most common 1000 ngrams
preprocessor=remove_noise # 上面自定义的预处理函数
)
vec.fit(x_train)
def get_features(x):
vec.transform(x)
可通过result = vec.transform(["Trump images are now more popular than cat gifs"])和result.toarray()来查看结果。
也可以通过vec.vocabulary_来查看词典。
导入分类器进行训练
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(x_train), y_train)
朴素贝叶斯算法假设了数据集属性之间是相互独立的,因此算法的逻辑性十分简单,并且算法较为稳定,当数据呈现不同的特点时,朴素贝叶斯的分类性能不会有太大的差异。换句话说就是朴素贝叶斯算法的健壮性比较好,对于不同类型的数据集不会呈现出太大的差异性。当数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
得出准确率
classifier.score(vec.transform(x_test), y_test)
规范化,写成一个类
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from joblib import dump, load
class LanguageDetector():
# 成员函数
def __init__(self, classifier=MultinomialNB()):
self.classifier = classifier
self.vectorizer = CountVectorizer(ngram_range=(1,2), max_features=1000, preprocessor=self._remove_noise)
# 私有函数,数据清洗
def _remove_noise(self, document):
noise_pattern = re.compile("|".join(["http\S+", "\@\w+", "\#\w+"]))
clean_text = re.sub(noise_pattern, "", document)
return clean_text
# 特征构建
def features(self, X):
return self.vectorizer.transform(X)
# 拟合数据
def fit(self, X, y):
self.vectorizer.fit(X)
self.classifier.fit(self.features(X), y)
# 预估类别
def predict(self, x):
return self.classifier.predict(self.features([x]))
# 测试集评分
def score(self, X, y):
return self.classifier.score(self.features(X), y)
# 模型持久化存储
def save_model(self, path):
dump((self.classifier, self.vectorizer), path)
# 模型加载
def load_model(self, path):
self.classifier, self.vectorizer = load(path)
模型训练与存储
in_f = open('../data/lesson1_data/data.csv')
lines = in_f.readlines()
in_f.close()
dataset = [(line.strip()[:-3], line.strip()[-2:]) for line in lines]
x, y = zip(*dataset)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2019)
language_detector = LanguageDetector()
language_detector.fit(x_train, y_train)
print(language_detector.predict('This is an English sentence'))
print(language_detector.score(x_test, y_test))
# 模型存储
!mkdir ../../tmp/model
model_path = "../../model/language_detector.model"
language_detector.save_model(model_path)
# 模型加载
new_language_detector = LanguageDetector()
new_language_detector.load_model(model_path)
# 使用加载的模型预测
new_language_detector.predict("10 der welt sind bei")
二、Flask部署
Flask是由python实现的一个web微框架,让我们可以使用Python语言快速实现一个网站或Web服务。
我们将从数据预处理到训练、预测、评分等全过程的代码封装成一个class,并利用FLASK开发一个简单的web应用。
构建目录树如下:

app.py
app.py文件包含将由python解释器执行以运行Flask Web应用程序的主代码,还包含用于对输入文本信息进行分类的ML代码。
在app.py中原封装代码的基础上增加以下内容:
from flask import Flask,render_template,url_for,request
app = Flask(__name__)
@app.route('/')
def home():
return render_template('home.html')
@app.route('/predict',methods=['POST'])
def predict():
model_path = "model/language_detector.model"
# windows下可能会报错找不到模型
# model_path = "F:\...\model\language_detector.model"
my_language_detector = LanguageDetector()
my_language_detector.load_model(model_path)
if request.method == 'POST':
message = request.form['message']
my_prediction = my_language_detector.predict(message)
return render_template('result.html',prediction = my_prediction[0])
if __name__ == '__main__':
app.run(debug=True)

首先引入了Flask类,然后给这个类创建了一个实例,name代表这个模块的名字。因为这个模块是直接被运行的所以此时name的值是main。然后用route()这个修饰器定义了一个路由,告诉flask如何访问该函数。最后用run()函数使这个应用在服务器上运行起来。
home.html
home.html将呈现文本表单的文件的内容,用户可以在其中输入消息:
<!DOCTYPE html>
<html>
<head>
<title>Home</title>
<!-- <link rel="stylesheet" type="text/css" href="../static/css/styles.css"> -->
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.css') }}">
</head>
<body>
<header>
<div class="container">
<div id="brandname">
基于Flask的机器学习应用
</div>
<h2>简易机器学习语种识别器</h2>
</div>
</header>
<div class="ml-container">
<form action="{{ url_for('predict')}}" method="POST">
<p>请在此输入你的检测内容</p>
<!-- <input type="text" name="comment"/> -->
<textarea name="message" rows="4" cols="50"></textarea>
<br/>
<input type="submit" class="btn-info" value="预测">
</form>
</div>
</body>
</html>
styles.css文件
在home.html的head部分,我们将加载styles.css文件,css文件用于确定HTML文档的外观和风格。styles.css必须保存在一个名为static的子目录中,这是Flask查找静态文件(如css)的默认目录。
body{
font:15px/1.5 Arial, Helvetica,sans-serif;
padding: 0px;
background-color:#f4f3f3;
}
.container{
width:100%;
margin: auto;
overflow: hidden;
}
header{
background:#03A9F4;#35434a;
border-bottom:#448AFF 3px solid;
height:120px;
width:100%;
padding-top:30px;
}
.main-header{
text-align:center;
background-color: blue;
height:100px;
width:100%;
margin:0px;
}
#brandname{
float:left;
font-size:30px;
color: #fff;
margin: 10px;
}
header h2{
text-align:center;
color:#fff;
}
.btn-info {background-color: #2196F3;
height:40px;
width:100px;} /* Blue */
.btn-info:hover {background: #0b7dda;}
.resultss{
border-radius: 15px 50px;
background: #345fe4;
padding: 20px;
width: 200px;
height: 150px;
}
result.html
我们创建一个result.html文件,该文件将通过函数render_template('result.html',prediction = my_prediction[0])返回呈现predict,我们在app.py脚本中定义该文件以显示用户通过文本字段提交的文本。result.html如下:
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/styles.css') }}">
</head>
<body>
<header>
<div class="container">
<div id="brandname">
算法应用
</div>
<h2>机器学习语种识别器</h2>
</div>
</header>
<p style="color:blue;font-size:20;text-align: left;"><b>算法检测结果如下</b></p>
<div class="results">
{% if prediction == "en"%}
<h2>这是<font color="red">英语</font></h2>
{% elif prediction == "de"%}
<h2>这是<font color="red">德语</font></h2>
{% elif prediction == "nl"%}
<h2>这是<font color="red">荷兰语</font></h2>
{% elif prediction == "es"%}
<h2>这是<font color="red">西班牙语</font></h2>
{% elif prediction == "it"%}
<h2>这是<font color="red">意大利语</font></h2>
{% elif prediction == "fr"%}
<h2>这是<font color="red">法语</font></h2>
{% endif %}
</div>
</body>
</html>

运行
运行app.py程序,在浏览器中打开 http://127.0.0.1:5000/,即可输入文本进行测试。
可能的报错
-
Windows下可能会报错找不到模型:
FileNotFoundError: [Errno 2] No such file or directory: 'model\\language_detector.model',此时可以尝试将模型的相对路径改为绝对路径。 -
Flask中报错:
NameError: name 'app' is not defined。
这是因为前面没有指定app的名字是什么,在flask中一定要加一句app = Flask(__name__) -
设置监听端口0.0.0.0却不能外网访问。
首先需要将运行函数改为app.run(host=‘0.0.0.0’),如果运行pycharm,发现没有起作用,运行的结果依然是http://127.0.0.1:5000,那么则需要在pycharm中run->edit configurations->Additional options里添加一下host设置,添加一行设置--host=0.0.0.0,设置完之后在点击运行就会发现此时运行结果已经改变。
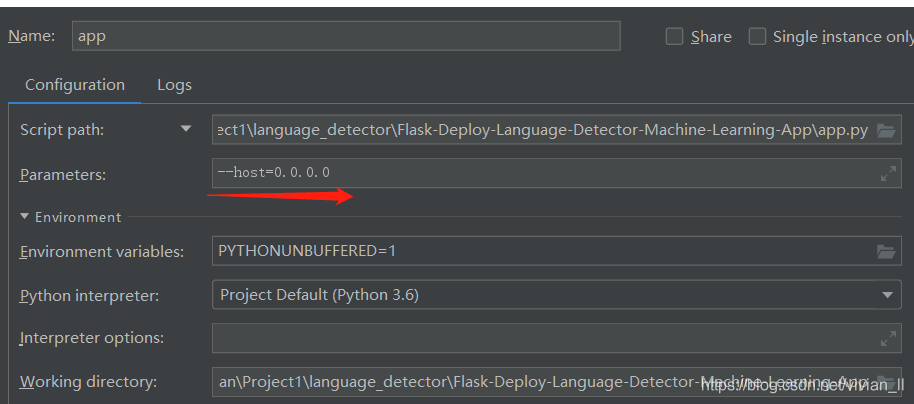
注意:将host设为0.0.0.0之后,我们编程访问时并不是访问http://0.0.0.0:5000这个网址,里面的 ip地址0.0.0.0 需要替换为flask程序所在的电脑的ip地址。(必须有公网ip,如果是个人电脑,可以参考https://hsk.oray.com/news/3225.html进行设置)
设置为0.0.0.0意思是我们可以在外部用任何网络访问。如果设置为别的ip地址意思是外部只有这个ip地址可以访问.
另外Pycharm启动Flask,运行app.run()是默认的127.0.0.1:5000,如果更改端口,只需要在上面的设置中,添加下面的命令
--port=****即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









