









 介绍了一种利用BiLSTM(双向长短期记忆网络)和CRF(条件随机场)进行标点符号预测的方法,该方法能有效提高文本的可读性和自然语言处理任务的准确性。
介绍了一种利用BiLSTM(双向长短期记忆网络)和CRF(条件随机场)进行标点符号预测的方法,该方法能有效提高文本的可读性和自然语言处理任务的准确性。
参考网址:https://blog.csdn.net/sihailongwang/article/details/76147065
原文地址:http://lxie.nwpu-aslp.org/papers/2016ISCSLP-XKT.pdf
据悉,标准的语音识别系统的输出是缺乏标点和句边界的。标点预测(punctuation prediction)技术,又称句边界检测(sentence boundary detection)或句切分(sentence segmentation)技术,是一种典型的序列标注机器学习任务,是指在缺乏标点的文本(如语音识别抄本)中加入标点或对篇章文本进行句子单元切分,目的是提高文本的可懂度,降低人工阅读的负荷;同时有效的标点和句边界也是自然语言理解、机器翻译等任务的前提。实验室在标点预测技术方面具有多年的技术储备,在此方面先后发表了六篇论文。其中,与微软研究院合作的论文Investigating LSTM for Punctuation Prediction在第十届中文口语语言处理国际会议(ISCSLP2016)上获得了最佳学生论文提名奖。此次实验室技术在腾讯在线系统上的成功应用,是校企合作推动技术成果转化的代表之作。
本文是利用BiLstm(双向Lstm)+CRF模型,对词组间的标点符号进行预测。
作者首先强调了,递归神经网络(RNN)及其变体在各种序列标签的任务已经显示出优越的性能,例如词性(POS)标签,分块和命名实体识别,韵律边界预测和语言理解。标点符号预测可以被看作是一个典型的序列标签任务。与此同时,作者认为,如果两个都是过去和未来的上下文考虑,标点符号标记更准确;使用一个条件随机域(CRF)层的Lstm可以捕获输出上下文信息,也会有一些性能上的提升。
BiLstm最大的优点在于:它不仅可以利用上一个的信息,还可以利用下一个的信息。
所做的贡献:
1)建议使用双向LSTM(BLSTM)和深度网络架构考虑过去和未来的输入以及模型输入特性和输出标签之间的复杂关系。
2)调查的上下文建模是否输出标点标签,通过CRF层,可以实现对标点符号的预测性能,如预期的那样在其他序列标签的任务。
3)通过研究,得出一个结论:一个2层BLSTM模型可以在标点符号生产最先进的性能预测
模型结构:
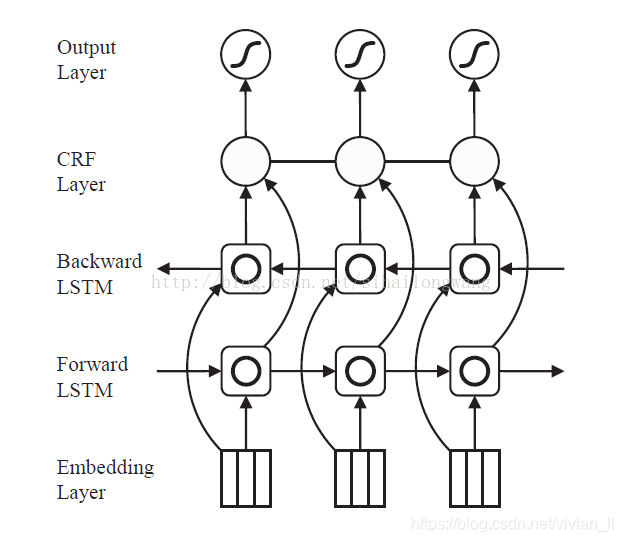
算法流程:
对于每个epoch循环:
对于每个batch循环:
(1)BiLstm-CRF正向传播
(2)CRF正向传播
(3)BiLstm-CRF反向传播
(4)更新参数
结束循环batch
结束循环epoch
实验需注意的事项:
(1)在输入前,进行了数据预处理:把问号、感叹号换成句号;把冒号、分号换成逗号(相当于只预测不打标点、逗号和句号三种情况),其他的符号均删除
(2)输入是一句话(经过分词之后的)和这句话中每个词语前的标点符号的label
(3)他们采用的是Mecab-toolkit工具进行分词的
实验结果:
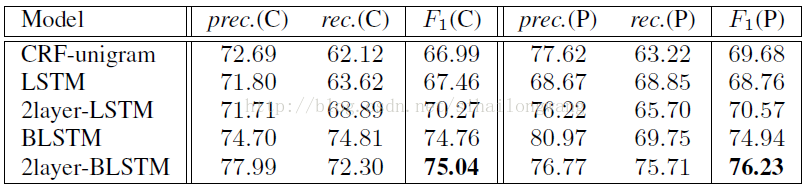



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









