



 本文介绍了使用Python进行XPath信息提取和CSV文件操作。XPath提取包括获取节点、文本、链接、标签元素、固定位置信息和匹配数字等方法,需先对网页用lxml库解析。CSV文件操作涵盖写入和读取,要注意Python3文件读写的编码问题。
本文介绍了使用Python进行XPath信息提取和CSV文件操作。XPath提取包括获取节点、文本、链接、标签元素、固定位置信息和匹配数字等方法,需先对网页用lxml库解析。CSV文件操作涵盖写入和读取,要注意Python3文件读写的编码问题。
xpath提取信息及CSV文件
一、xpath提取
1.获取xpath节点方法
xpath是按照HTML标签的方式进行定位的,谷歌浏览器自带有xpath,可以直接复制过来使用,简单方便,运行速度快。输出结果为:
//*[@id=“content”]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
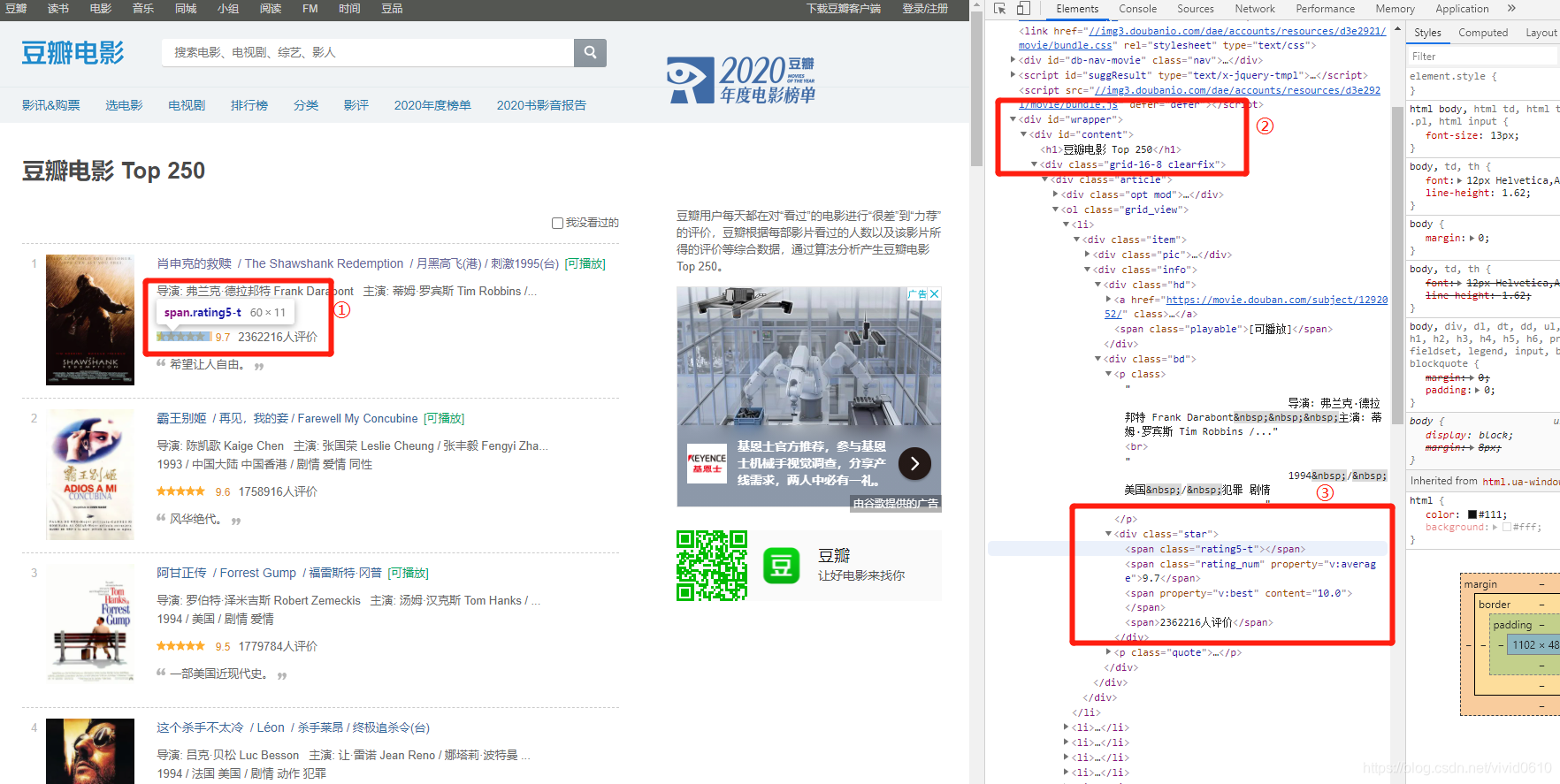
在需要的内容上右键,在copy选项中选择copy xpath
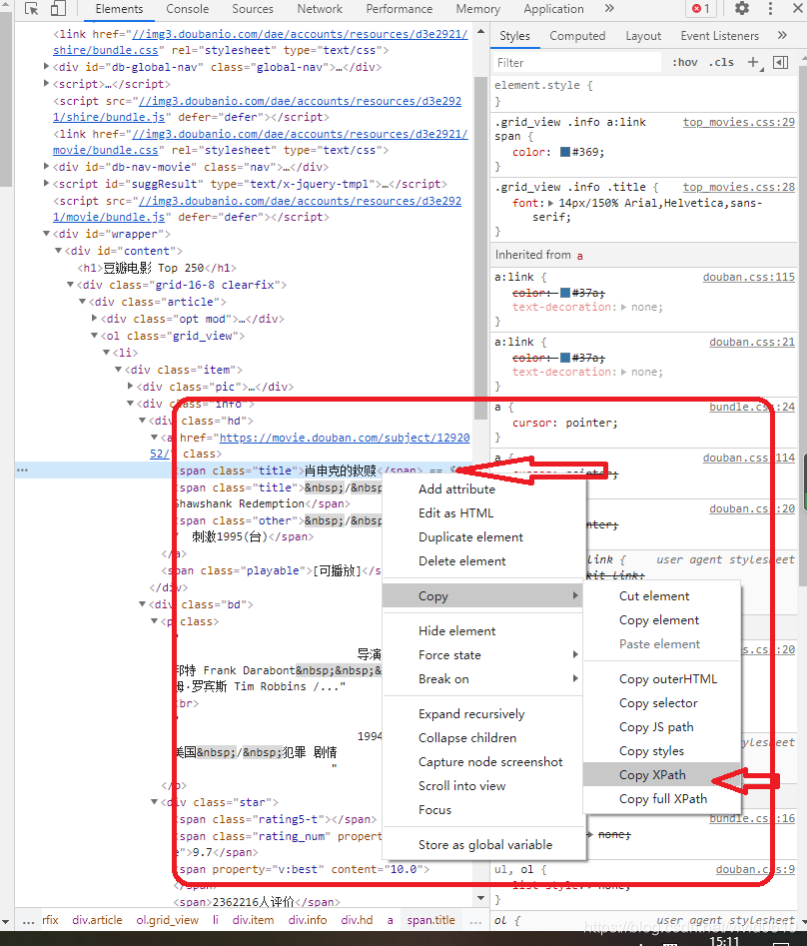
使用xpath时,也必须先对网页进行 lxml 库中的 etree 解析,把它变为特有的树状形式,才能通过它进行节点定位
from lxml import etree #导入解析库
html_etree = etree.HTML(reponse) #树状结构解析
2.xpath提取文本
当我们提取标签内的文本时,需要在复制到的xpath后面加上 /text() ,告诉它我们需要提取的内容是一个标签呈现的数据
<span class="title">肖申克的救赎</span>
结合xpath所提取的文字代码为:
html_etree = etree.HTML(r)
name = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()')
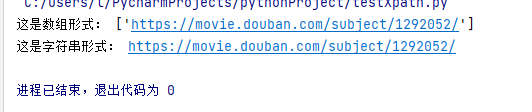
print ("这是数组形式:",name)
print ("这是字符串形式:",name[0])
3.xpath提取链接
每一个链接都是在标签内的,通常放在 src=" " 或者 href=" " 之中,如

xpath为:
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a
提取链接时,需要在复制到的xpath后面加上 /@href , 指定提取链接
movie_url = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/@href')
print ("这是数组形式:",movie_url)
print ("这是字符串形式:",movie_url[0])
4.xpath提取标签元素
这个网页中电影的星级没有用几颗星的文本表示,而是标签表示的
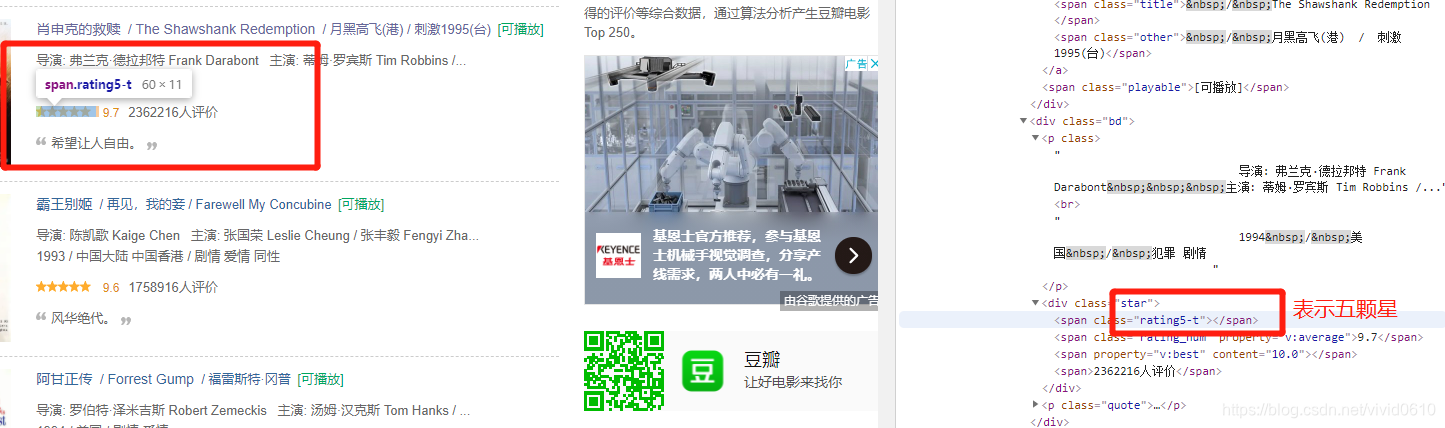
只需要取出 class=" " 中的内容就可以得到星级了,复制它的xpath,和提取链接的方法一样,在后面加上 /@class 即可
rating = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[1]/@class')
print ("这是数组形式:",rating)
print ("这是字符串形式:",rating[0])
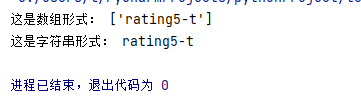
接下来需要把结果中的信息匹配出来,可以使用正在表达式,单独提取自己需要的信息,如星级,它都是以 rating5-t 方式呈现的,但是我们只需要它数字5位置的部分,所以需要进行二次提取
5.提取固定位置信息
正则表达式中可以使用 .*? 来进行匹配信息,没有加括号时可以去掉不一样的信息,不需要提取出来,加括号 (.*?) 可以提取出括号内的内容
test = "rating5-t"
text = re.findall('rating(.*?)-t', test)
print (text)
6.匹配数字
比如评价数,我们xpath提取到的数据格式为: 1056830人评价 ,保存的时候只需要数字即可,现在把数字提取出来
data = "1059232人评价"
num = re.sub(r'\D', "", data)
print("这里的数字是:", num)
二、CSV文件
在使用Python进行网络爬虫或数据分析时,通常会遇到CSV文件,类似于Excel表格。在这里详细学习“把大象装进冰箱”的步骤
1.CSV文件写
基本流程如下:
√导入CSV模块
√创建一个CSV文件对象
√写入CSV文件
√关闭文件
# -*- coding: utf-8 -*-
import csv
c = open("test-01.csv", "w", encoding="utf8", newline='') #写文件
writer = csv.writer(c)
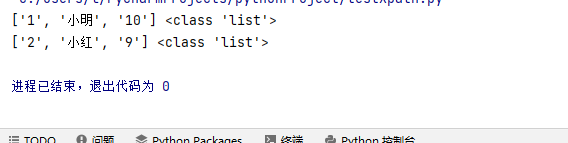
writer.writerow(['序号','姓名','年龄'])
tlist = []
tlist.append("1")
tlist.append("小明")
tlist.append("10")
writer.writerow(tlist)
print(tlist,type(tlist))
del tlist[:] #清空
tlist.append("2")
tlist.append("小红")
tlist.append("9")
writer.writerow(tlist)
print(tlist,type(tlist))
c.close()
2.CSV文件读
基本流程如下:
√导入CSV模块
√创建一个CSV文件对象
√读取CSV文件
√关闭文件
# -*- coding: utf-8 -*-
import csv
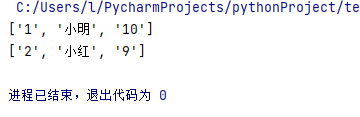
c = open("test-01.csv", "r", encoding="utf8") #读文件
reader = csv.reader(c)
for line in reader:
print(line[0],line[1],line[2])
c.close()
在文件操作中编码问题是最让人头疼的,Python3文件读写操作写清楚encoding编码方式就能正常显示

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









