







第1章 语言应用初探 Lanugage Applications Cracked Open
1.1 大局观 The Big Picture
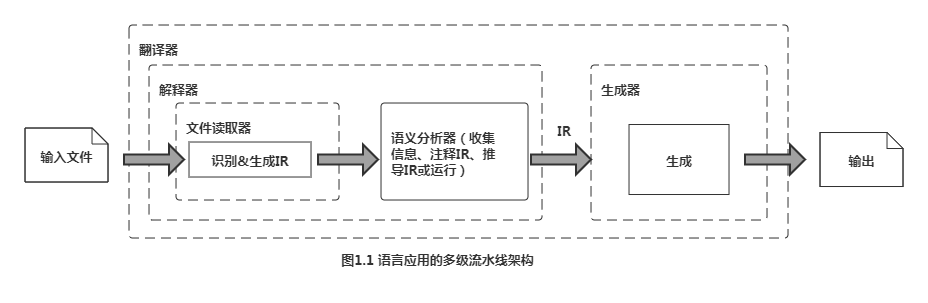
主要思想:文件读取部分对输入内容进行“识别”,并输出数据结构作为中间表示(intermediate representation,IR),供其他部件使用。流水线的末端是生成器,会根据IR及之前所收集到的信息进行计算,并输出最终所需的结果。那么这之间的过程就是进行语义分析。
图形地址:ProcessOn Flowchart
1.2 模式概览 A Tour of the Patterns
-
解析输入语句:解析输入内容的结构
-
2、3章文件读取器所涉及的模式
-
还会对文法进行一些讲解(用形式语言描述的),跟解释器识别语言的原理有关
-
第一种模式根据文法手工编写解析器:ANTLR(或类似的解析器、生成器 www.antlr.org)可以自动实现这个功能
-
简单的输入组件,模式二和模式三可以识别输入语句
-
模式四:增加每次读入字符的个数,解析器的解析能力会得到提高
-
模式五:更复杂情况,解析器得读入整个语句才能解析
-
模式六:回溯法,解析能力强大,但运行效率较低
-
模式七:最强大的解析能力,谓词解析器能根据运行时的信息进行动态调整,切换到正确的解析流上
-
-
-
构建语法树:为避免重新解析输入流,可以生成一些数据结构作为IR
-
模式八:第一个有关树的模式。解析树中含很多无用信息。如果要编写源代码分析器或者翻译器等应用,通常会采用抽象语法树(abstract syntax tree, AST),主要考虑遍历树的方式(前中后序等等)
-
模式九:所有节点都用同种类型表示
-
模式十:多类型节点
-
模式十一:异型节点
-
-
遍历树:树的遍历方法选择
-
模式十二:把方法内置于每个节点的类中
-
模式十三:把方法封装在外部访问者里
-
模式十四、十五:使用工具自动生成访问者,就像自动生成解析器一样
-
-
弄清输入的含义:要想生成有用的输出结果,就必须分析输入内容,以获取相关的信息(语义分析),符号表。符号表所采用的的模式取决于语言的语义规则。
-
模式十六:单一作用域规则
-
模式十七:嵌套作用域规则
-
模式十八:C结构体作用域规则
-
模式十九:类作用域规则
-
模式二十、二十一:为类C/C++语言打好基础
-
模式二十二:类C语言非面向对象语言处理
-
模式二十三:类C++语言面向对象语言处理
-
-
解释输入语句:解释器能运行IR中的指令,但一般也要使用符号表之类的数据结构
-
模式二十四、二十五、二十七、二十八:从作用上来说等价,常见的解释器模式,只是在指令集、运行效率、交互性、易用性及实现的难度上存在差异
-
-
翻译语言:任何翻译器的末端都是生成器,能产生结构化的文本或者二进制数据
-
模式二十九:模型驱动领域方法、模版引擎(逆解析器等,如书中的StringTemplate www.stringtemplate.org)
-
1.3 深入浅出语言应用 Dissecting a Few Applications
字节码解释器
用软件模拟出硬件处理器,因此也被称作虚拟机。指令集比较底层,但是没有机器代码那么底层。指令集里的指令往往用一个字节(能表示0到255之间不同的整数)就能表示,因此又称为字节码。
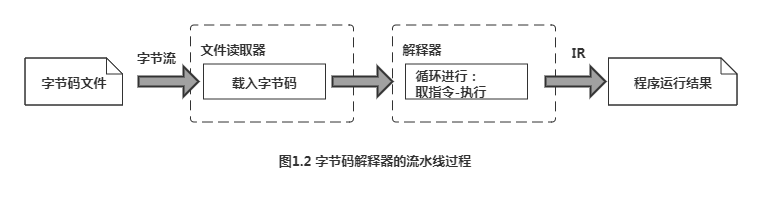
包括Java、Lua、Python、Ruby、C#和Smalltalk在内的语言都采用字节码解释器来实现。Lua实现方式采用模式二十八,其他几个用的是模式二十七。在1.9版本以前,Ruby实现方式类似于模式二十五。
Java差错程序1
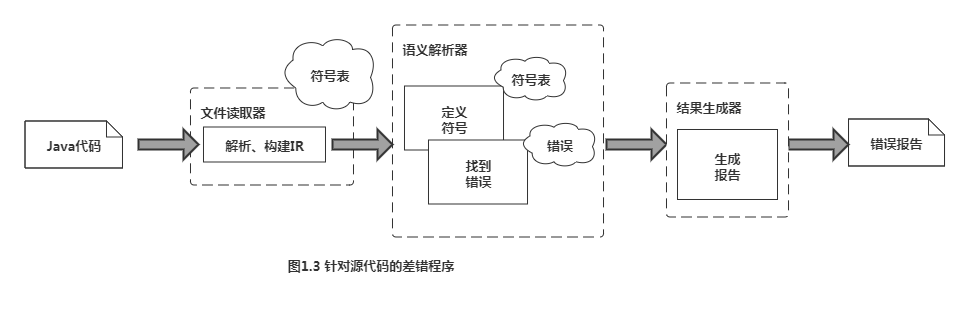
本例的语义分析中,需要遍历IR两次,第一次记录所有的符号(标识符),第二次找出所有等号两边一样的赋值语句。
大部分文件的读取都分为两个阶段,首先把输入的字符流分成基本符号,即词法单元,之后用语法解析器检查词法单元的语法。在这个例子里,词法分析器(有些书中也称lexer)会输出如下符号流: ... void setX ( int y ) { ...
语法解析器一边进行语法扫描,一边构建IR。
Java差错程序2
Java编译器输出.class文件,里面是序列化的符号表和AST。使用字节码工程库(byte code engineering library,BCEL)或类似的class文件读取器,就可以直接载入.class文件并分析,而不用自己编写源代码读取器了(实际上,FindBugs就用了这种方式)。图1.5所示的是这种方法的流水线图。(略)
javac也是编译器,其基本原理与传统的C语言编译器的一样。唯一的区别就是C编译器最终会把代码翻译为某个特定平台上的指令。
C编译器
预处理=>加行号的C代码=>编译器处理=>输出汇编代码(机器码的文本助记符)=>汇编器生成最终的二进制机器码
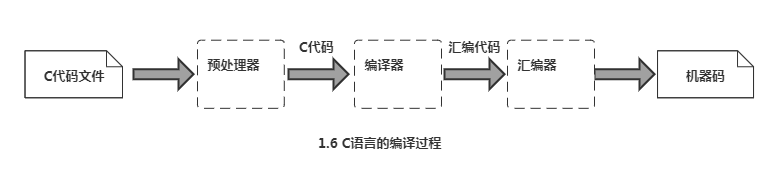
gcc 命令后加上参数-S,就可以把tmp.c编译成汇编代码(tmp.s),而不直接生成机器码。再使用as命令,就可以得到目标文件tmp.o: as -o tmp.o tmp.s(#把tmp.s汇编为tmp.o)
C编译器的流水线:
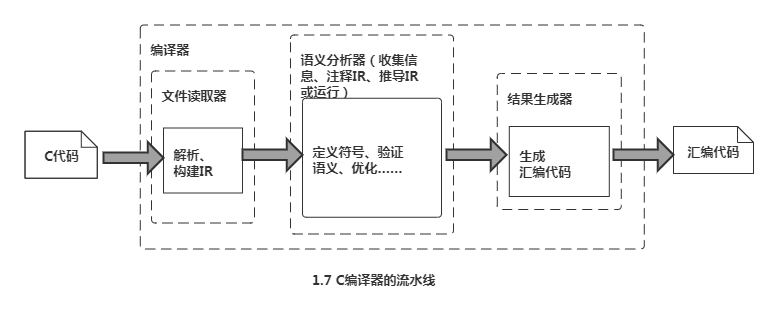
编译器最复杂的地方是语义分析和优化。
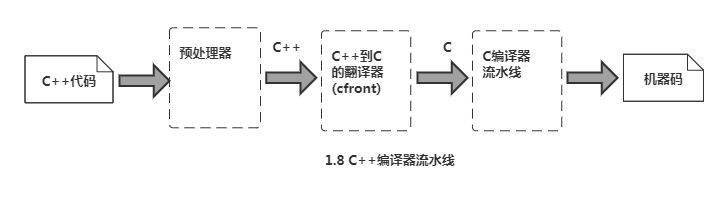
借助C编译器实现C++语言
Bjarne Stroustrup使用了已有的C编译器来完成对C++的编译。
具体来说,他只编写了翻译器(cfront),能把C++翻译成C,而没有编写真正的C++编译器。
由文件读取器、语义解析器和生成器组成。
1.4 为语言应用选择合适的模式 Choosing Patterns and Assembling Applications
程序员常做的两件事:一是实现某个DSL,二是处理或者翻译GPPL(General-Purpose Programming Language,是指类似C、Java等功能较为完备的编程语言)。换言之,程序员可能得实现某种制图语言或者数学语言,但很少需要编写大型程序语言的编译器或解释器。通常所遇到的任务不外乎是编写一些重构、格式调整、度量软件、错误查找、插桩或者翻译语言的工具。
编译器用到的模式,往往也是实现DSL甚至GPPL所需要的关键模式。比如符号表管理模式,几乎所有语言应用都以之为基础。
语言应用中,最基本的架构就是将词法分析模式和语法分析模式组合起来,这是模式二十四和二十九的核心。
另一个基本架构会对输入进行分析并构建AST(通过解析器来构造树),而不会对其进行实时处理。构建好AST之后,就可以对输入的内容进行多次遍历,而不用重复解析,这是比较高效的作法。比如模式二十五的while每次都会重新访问AST节点。



















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











