







Clickhouse的JOIN子句 可以多多表的数据进行连接查询,在Clickhouse中JOIN语法包含连接精度和连接类型两部分:
连接精度:ALL ANY ASOF
连接类型:外连接 内连接和交叉连接
我们使用DB-engine中的数据来演示说明:
t_socre表中有独有的HBase,t_rank 有独有的InfluxDB,t_info有独有的Greenplum记录。
create table t_score(
id UInt32,db_name String,month_score Decimal32(2),diff_lastyear_month_score Decimal32(2)
,diff_threeyearago_month_score Decimal32(2),lastmodifytime Datetime) engine=MergeTree()
PARTITION BY toYYYYMM(lastmodifytime)
ORDER BY id;
INSERT INTO `t_score` VALUES (1, 'Elasticsearch', 151.59, 1.90, 2.77, now());
INSERT INTO `t_score` VALUES (2, 'Redis', 150.05, 4.40, 5.78, now());
INSERT INTO `t_score` VALUES (3, 'Hive', 76.42, -2.23, -4.45,now());
INSERT INTO `t_score` VALUES (4, 'Spark SQL', 18.40, 0.50, 1.65, now());
INSERT INTO `t_score` VALUES (5, 'ClickHouse', 5.31, 0.45, 2.21, now());
INSERT INTO `t_score` VALUES (6, 'TiDB', 2.05, 0.23, 0.38, now());
INSERT INTO `t_score` VALUES (7, 'CockroachDB', 4.97, 0.40, 2.10, now());
INSERT INTO `t_score` VALUES (8, 'HBase', 48.66, -0.07, -8.88, now());
create table t_rank( id UInt32,db_name String,month_rank UInt32,diff_lastyear_month_rank UInt32
,diff_threeyearago_month_rank UInt32,lastmodifytime Datetime) engine=MergeTree()
PARTITION BY toYYYYMM(lastmodifytime)
ORDER BY id;
INSERT INTO `t_rank` VALUES (1, 'Elasticsearch', 7, 7, 7, now());
INSERT INTO `t_rank` VALUES (2, 'Redis', 8, 8, 8, now());
INSERT INTO `t_rank` VALUES (3, 'Hive', 14, 14, 14, now());
INSERT INTO `t_rank` VALUES (4, 'Spark SQL', 34, 34, 35, now());
INSERT INTO `t_rank` VALUES (5, 'ClickHouse', 65, 67, 86, now());
INSERT INTO `t_rank` VALUES (6, 'TiDB', 119, 121, 120, now());
INSERT INTO `t_rank` VALUES (7, 'CockroachDB', 68, 74, 89, now());
INSERT INTO `t_rank` VALUES (8, 'InfluxDB', 30, 30, 34, now());
create table t_info( id UInt32,db_name String,db_model String,website String,developer String
,lastmodifytime Datetime) engine=MergeTree()
PARTITION BY toYYYYMM(lastmodifytime)
ORDER BY id;
INSERT INTO `t_info` VALUES (1, 'Elasticsearch', 'Search engine,Document store', 'www.elastic.co/elasticsearch', 'Elastic', now());
INSERT INTO `t_info` VALUES (2, 'Redis', 'Key-value store,Document store,Graph DBMS,Time Series DBMS', 'www.redis.io', 'Salvatore Sanfilippo', now());
INSERT INTO `t_info` VALUES (3, 'Hive', 'Relational DBMS', 'hive.apache.org', 'Facebook', now());
INSERT INTO `t_info` VALUES (4, 'Spark SQL', 'Relational DBMS', 'https://spark.apache.org/sql/', 'DataBricks', now());
INSERT INTO `t_info` VALUES (5, 'ClickHouse', 'Relational DBMS,Time Series DBMS', 'clickhouse.tech', 'Yandex LLC', now());
INSERT INTO `t_info` VALUES (6, 'TiDB', 'Relational DBMS,NewSQL,Document store', 'pingcap.com', 'PingCAP, Inc', now());
INSERT INTO `t_info` VALUES (7, 'CockroachDB', 'Relational DBMS,NewSQL', 'www.cockroachlabs.com', 'Cockroach Labs', now());
INSERT INTO `t_info` VALUES (8, 'Greenplum', 'Relational DBMS,Document store', 'https://tanzu.vmware.com/greenplum', 'Pivotal Software Inc.', now());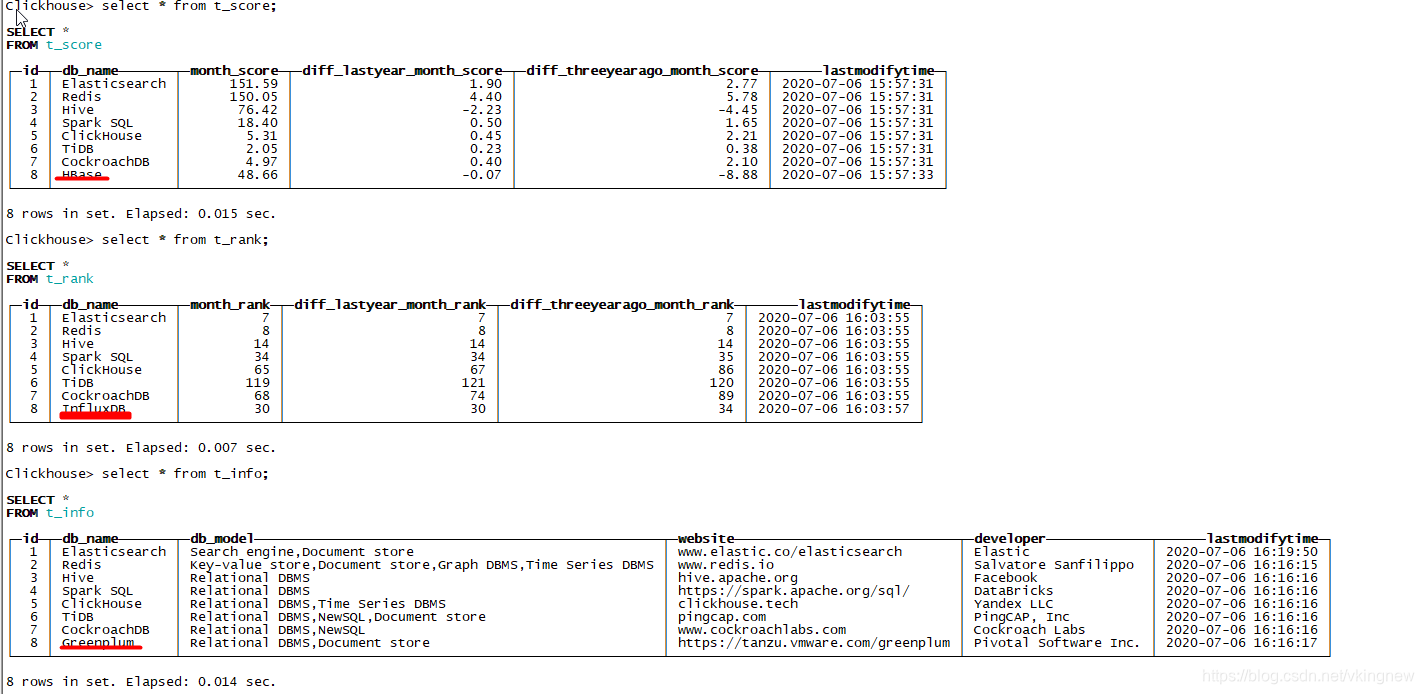
可以看到每行的第八行数据不一样。
1.连接精度:
连接进度决定了JOIN查询在连接数据时所使用的策略,目前支持ALL,ANY和ASOF 三种类型。如果不主动声明则默认是ALL。
可以通过join_default_strictness 设置修改默认的连接精度类型。
对数据是否连接匹配的判断是通过JOIN KEY 进行的,目前只支持等值连接equal join,交叉连接cross join 不需要JOIN KEY,因为他们会产生笛卡尔积。
1.ALL
若左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据。而判断连接匹配的依据
则是左表和右表的数据,基于连接键JOIN KEY的取值完全相等。
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r ALL INNER JOIN t_score s on r.id=s.id;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
ALL INNER JOIN t_score AS s ON r.id = s.id
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.002 sec.
2.ANY
若左表内的一行数据在右表中的有多行数据与之匹配则仅仅返回右表中的第一行连接的数据。
ANY 和ALL判断连接匹配的依据相同。
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r ANY INNER JOIN t_score s on r.id=s.id;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
ANY INNER JOIN t_score AS s ON r.id = s.id
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.005 sec.
3.ASOF
ASOF 是一种模糊连接,允许在连接键之后追加定义一个模糊连接的匹配条件 asof_column
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r ASOF INNER JOIN t_score s on r.id=s.id and r.lastmodifytime>=s.lastmodifytime;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
ASOF INNER JOIN t_score AS s ON (r.id = s.id) AND (r.lastmodifytime >= s.lastmodifytime)
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.003 sec.
最终返回的查询符合连接条件 (r.id = s.id) AND (r.lastmodifytime >= s.lastmodifytime)
且返回了右表中第一行连接匹配的数据。
ASOF 支持使用USING的简写形式,USING后声明的最后一个字段会被自动转换为asof—column模糊连接条件。
等同的语句:
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r ASOF INNER JOIN t_score s USING(id,lastmodifytime);
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
ASOF INNER JOIN t_score AS s USING (id, lastmodifytime)
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.004 sec.
注意:
1.对于使用asof_column 字段的使用有两点需要注意:asof_column 必须是整形,浮点型和日期类型 这种有序序列的数据类型
2.asof_column 不能是数据表内的唯一字段 即连接JOIN KEY 和ASOF_column 不能是同一个字段。2.连接类型:
连接类型决定了JOIN查询组合左右两个数据集合要用的策略,他们所形成的结果是交集,并集,笛卡尔积或其他形式。
1. INNER JOIN
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r ANY INNER JOIN t_score s on r.db_name=s.db_name;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
ANY INNER JOIN t_score AS s ON r.db_name = s.db_name
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
7 rows in set. Elapsed: 0.004 sec.
结果只显示左表和右表中db_name 相同的数据才会保留,保留交集数据。
2.OUTER JOIN:
LEFT ,RIGHT,FULL 连接三种。
2.1 LEFT OUTER JOIN:
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r LEFT OUTER JOIN t_score s on r.db_name=s.db_name;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
LEFT JOIN t_score AS s ON r.db_name = s.db_name
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 0 │ │ 0.00 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.002 sec.
2.2 RIGHT OUTER JOIN:
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r RIGHT OUTER JOIN t_score s on r.db_name=s.db_name FORMAT PrettyCompactMonoBlock;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
RIGHT JOIN t_score AS s ON r.db_name = s.db_name
FORMAT PrettyCompactMonoBlock
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 0 │ │ 0 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.004 sec.
2.3 FULL OUTER JOIN:
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r FULL OUTER JOIN t_score s on r.db_name=s.db_name FORMAT PrettyCompactMonoBlock;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
FULL OUTER JOIN t_score AS s ON r.db_name = s.db_name
FORMAT PrettyCompactMonoBlock
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 0 │ │ 0.00 │
│ 0 │ │ 0 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
9 rows in set. Elapsed: 0.003 sec.
3. CROSS JOIN
CROSS JOIN 表交叉连接 它返回左表和右表两个数据集合的笛卡尔积。 CROSS JOIN 不需要声明 JOIN KEY,他们的会包含所有的组合,会生成左表的行数 n * 右表的行数:
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r CROSS JOIN t_score s ;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
CROSS JOIN t_score AS s
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 1 │ Elasticsearch │ 7 │ 2 │ Redis │ 150.05 │
│ 1 │ Elasticsearch │ 7 │ 3 │ Hive │ 76.42 │
│ 1 │ Elasticsearch │ 7 │ 4 │ Spark SQL │ 18.40 │
│ 1 │ Elasticsearch │ 7 │ 5 │ ClickHouse │ 5.31 │
│ 1 │ Elasticsearch │ 7 │ 6 │ TiDB │ 2.05 │
│ 1 │ Elasticsearch │ 7 │ 7 │ CockroachDB │ 4.97 │
│ 1 │ Elasticsearch │ 7 │ 8 │ HBase │ 48.66 │
│ 2 │ Redis │ 8 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 2 │ Redis │ 8 │ 3 │ Hive │ 76.42 │
│ 2 │ Redis │ 8 │ 4 │ Spark SQL │ 18.40 │
│ 2 │ Redis │ 8 │ 5 │ ClickHouse │ 5.31 │
│ 2 │ Redis │ 8 │ 6 │ TiDB │ 2.05 │
│ 2 │ Redis │ 8 │ 7 │ CockroachDB │ 4.97 │
│ 2 │ Redis │ 8 │ 8 │ HBase │ 48.66 │
│ 3 │ Hive │ 14 │ 1 │ Elasticsearch │ 151.59 │
│ 3 │ Hive │ 14 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 3 │ Hive │ 14 │ 4 │ Spark SQL │ 18.40 │
│ 3 │ Hive │ 14 │ 5 │ ClickHouse │ 5.31 │
│ 3 │ Hive │ 14 │ 6 │ TiDB │ 2.05 │
│ 3 │ Hive │ 14 │ 7 │ CockroachDB │ 4.97 │
│ 3 │ Hive │ 14 │ 8 │ HBase │ 48.66 │
│ 4 │ Spark SQL │ 34 │ 1 │ Elasticsearch │ 151.59 │
│ 4 │ Spark SQL │ 34 │ 2 │ Redis │ 150.05 │
│ 4 │ Spark SQL │ 34 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 4 │ Spark SQL │ 34 │ 5 │ ClickHouse │ 5.31 │
│ 4 │ Spark SQL │ 34 │ 6 │ TiDB │ 2.05 │
│ 4 │ Spark SQL │ 34 │ 7 │ CockroachDB │ 4.97 │
│ 4 │ Spark SQL │ 34 │ 8 │ HBase │ 48.66 │
│ 5 │ ClickHouse │ 65 │ 1 │ Elasticsearch │ 151.59 │
│ 5 │ ClickHouse │ 65 │ 2 │ Redis │ 150.05 │
│ 5 │ ClickHouse │ 65 │ 3 │ Hive │ 76.42 │
│ 5 │ ClickHouse │ 65 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 5 │ ClickHouse │ 65 │ 6 │ TiDB │ 2.05 │
│ 5 │ ClickHouse │ 65 │ 7 │ CockroachDB │ 4.97 │
│ 5 │ ClickHouse │ 65 │ 8 │ HBase │ 48.66 │
│ 6 │ TiDB │ 119 │ 1 │ Elasticsearch │ 151.59 │
│ 6 │ TiDB │ 119 │ 2 │ Redis │ 150.05 │
│ 6 │ TiDB │ 119 │ 3 │ Hive │ 76.42 │
│ 6 │ TiDB │ 119 │ 4 │ Spark SQL │ 18.40 │
│ 6 │ TiDB │ 119 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 6 │ TiDB │ 119 │ 7 │ CockroachDB │ 4.97 │
│ 6 │ TiDB │ 119 │ 8 │ HBase │ 48.66 │
│ 7 │ CockroachDB │ 68 │ 1 │ Elasticsearch │ 151.59 │
│ 7 │ CockroachDB │ 68 │ 2 │ Redis │ 150.05 │
│ 7 │ CockroachDB │ 68 │ 3 │ Hive │ 76.42 │
│ 7 │ CockroachDB │ 68 │ 4 │ Spark SQL │ 18.40 │
│ 7 │ CockroachDB │ 68 │ 5 │ ClickHouse │ 5.31 │
│ 7 │ CockroachDB │ 68 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 7 │ CockroachDB │ 68 │ 8 │ HBase │ 48.66 │
│ 8 │ InfluxDB │ 30 │ 1 │ Elasticsearch │ 151.59 │
│ 8 │ InfluxDB │ 30 │ 2 │ Redis │ 150.05 │
│ 8 │ InfluxDB │ 30 │ 3 │ Hive │ 76.42 │
│ 8 │ InfluxDB │ 30 │ 4 │ Spark SQL │ 18.40 │
│ 8 │ InfluxDB │ 30 │ 5 │ ClickHouse │ 5.31 │
│ 8 │ InfluxDB │ 30 │ 6 │ TiDB │ 2.05 │
│ 8 │ InfluxDB │ 30 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 8 │ HBase │ 48.66 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
64 rows in set. Elapsed: 0.003 sec.
左表有8条记录 右表8条记录 产生了8*8==64条记录。
3.多表连接:
Clickhouse> select r.id,r.db_name,r.month_rank,s.month_score,i.website from t_rank r LEFT OUTER JOIN t_score s on r.db_name=s.db_name left join t_info i on r.db_name=i.db_name;
SELECT
r.id,
r.db_name,
r.month_rank,
s.month_score,
i.website
FROM t_rank AS r
LEFT JOIN t_score AS s ON r.db_name = s.db_name
LEFT JOIN t_info AS i ON r.db_name = i.db_name
┌─r.id─┬─r.db_name─────┬─r.month_rank─┬─s.month_score─┬─i.website─────────────────────┐
│ 1 │ Elasticsearch │ 7 │ 151.59 │ www.elastic.co/elasticsearch │
│ 2 │ Redis │ 8 │ 150.05 │ www.redis.io │
│ 3 │ Hive │ 14 │ 76.42 │ hive.apache.org │
│ 4 │ Spark SQL │ 34 │ 18.40 │ https://spark.apache.org/sql/ │
│ 5 │ ClickHouse │ 65 │ 5.31 │ clickhouse.tech │
│ 6 │ TiDB │ 119 │ 2.05 │ pingcap.com │
│ 7 │ CockroachDB │ 68 │ 4.97 │ www.cockroachlabs.com │
│ 8 │ InfluxDB │ 30 │ 0.00 │ │
└──────┴───────────────┴──────────────┴───────────────┴───────────────────────────────┘
8 rows in set. Elapsed: 0.020 sec.
这里会有点问题 s表的分数应该为NULL,转为0.00 即此字段的默认数据值。
4.注意事项:
1.性能:
应该遵循 左大右小的原则,即将数据量小的表放在右侧。因为在执行JOIN查询的时候,无论哪种连接方式 右表都会被全部加载到内存中与左表进行比较。
JOIN 查询目前没有缓存的支持。
若在大量维度属性补全的查询场景中,则建议使用字典代替JOIN查询。因为在进行多表的连接查询的时候,查询会
转换为两两连接的形式。这种查询形式可能会带来性能问题。
2.关于空值策略和简写形式
在连接查询的空值是有默认值填充的,这与标准SQL所采取的策略不同。
连接策略是通过参数join_use_nulls参数指定的,默认为0.
当参数设置为0 空值由数据类型的默认值填充
参数值为1时候则空值由null填充。
JOIN KEY 支持简化写法,当数据表连接字段名称相同的时候可以用USING语法简写,但是并不推荐:
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r LEFT OUTER JOIN t_score s on r.db_name=s.db_name FORMAT PrettyCompactMonoBlock;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
LEFT JOIN t_score AS s ON r.db_name = s.db_name
FORMAT PrettyCompactMonoBlock
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 0 │ │ 0.00 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.003 sec.
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r LEFT OUTER JOIN t_score s USING db_name FORMAT PrettyCompactMonoBlock;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
LEFT JOIN t_score AS s USING (db_name)
FORMAT PrettyCompactMonoBlock
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ 0 │ │ 0.00 │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.003 sec.
可以看到查询效果一样的。
join_use_nulls 的效果:
Clickhouse> set join_use_nulls=1;
SET join_use_nulls = 1
Ok.
0 rows in set. Elapsed: 0.001 sec.
Clickhouse> select r.id,r.db_name,r.month_rank,s.id,s.db_name,s.month_score from t_rank r LEFT OUTER JOIN t_score s USING db_name FORMAT PrettyCompactMonoBlock;
SELECT
r.id,
r.db_name,
r.month_rank,
s.id,
s.db_name,
s.month_score
FROM t_rank AS r
LEFT JOIN t_score AS s USING (db_name)
FORMAT PrettyCompactMonoBlock
┌─id─┬─db_name───────┬─month_rank─┬─s.id─┬─s.db_name─────┬─month_score─┐
│ 1 │ Elasticsearch │ 7 │ 1 │ Elasticsearch │ 151.59 │
│ 2 │ Redis │ 8 │ 2 │ Redis │ 150.05 │
│ 3 │ Hive │ 14 │ 3 │ Hive │ 76.42 │
│ 4 │ Spark SQL │ 34 │ 4 │ Spark SQL │ 18.40 │
│ 5 │ ClickHouse │ 65 │ 5 │ ClickHouse │ 5.31 │
│ 6 │ TiDB │ 119 │ 6 │ TiDB │ 2.05 │
│ 7 │ CockroachDB │ 68 │ 7 │ CockroachDB │ 4.97 │
│ 8 │ InfluxDB │ 30 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
└────┴───────────────┴────────────┴──────┴───────────────┴─────────────┘
8 rows in set. Elapsed: 0.004 sec.

















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









