






文 | 拍乐云
早期的音频系统都是基于声音的模拟信号实现的,在声音的录制、编辑和播放过程中很容易引入各种噪声,从而导致信号的失真。随着信息技术的发展,数字信号处理技术在越来越多领域得到了应用,数字信号更是具备了易于存储和远距离传输、没有累积失真、抗干扰能力强等等,信号和信号处理都往数字化发展。为了使得数字音频可以被高效地压缩存储并高品质地还原,数字音频的编码技术就变成至关重要的一个部分了。本篇文章会介绍当今的音频的编码器(传统算法非深度学习)的两大主流阵营之一的基于线性预测的语音编码器的原理。
#01
音频的编码器分类及简介
比较流行基于传统算法的音频的编码器基本可以分成两个大的类别:
Audio Codec(音频编码器): aac, mp3, ogg, celt(inside of opus) ...
Speech Codec(语音编码器): ilbc, isac, silk(inside of opus) ...
而这两种编码器类型基于完全不同的编码原理,Audio Codec (音频编码器)利用了人类听觉感知系统的特性来研究音频编码的方法,可以对较多音源,复杂信号进行高品质的编码。而Speech Codec (语音编码器)是以语音生成模型为基础,可以对单个音源(人或者一些乐器的发音器官单元)进行更低码率的高效编码。
为什么已经有了可以对较多音源,复杂信号进行高品质编码的Audio Codec,还需要研究和发展Speech Codec呢?
因为应用领域的需求完全不一样。Audio Codec的应用领域更多和音乐有关,研究的是在保证尽量小的感知失真的前提下,对声音进行压缩编码。早期mp3想要实现高品质所需要的编码码率还是比较高的,压缩比并不高。而早期的数字电信系统的带宽有限,如何可以用尽量小的带宽实现可以还原出清晰的语音则成了Speech Codec的任务。更多在8kHz和16kHz采样率下实现较低码率的编码。
#02
语音的发声模型和特性
既然需要设计一款专门针对语音的编码器,那肯定要先研究一下语音的一些特性。
1. 人的发声模型
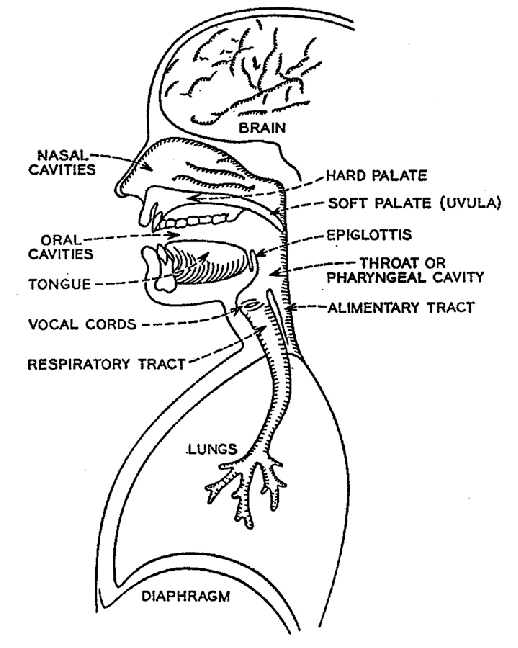
总的来说,人的发声模型可以分成三个部分:
由肺和气管产生生气源
喉和声带组成声门
咽腔,口腔,鼻腔等组成声道
人的发声过程基本过程可以这样描述:由肺部挤压产生流动高压气体,通过气管,经过喉咙,喉咙控制相关软骨组织和肌肉组织(其中最为重要为声道)进行复杂运动,最终声带在控制下进行合拢或者分离,最终产生了声音的激励,再经过咽腔、口腔、鼻腔共鸣最终形成声音。
2. 语音信号的一般分类
人发出不同的声音时,语音激励和声道的情况也是完全不同的,发出的声音基本可以分类为两种类型:
浊音:空气流经过声带时,声带呈紧绷状态,并产生张弛振动,即声带进行周期性的开启和闭合,空气流经过声带后形成一个一个脉冲,然后再经过各种声道的共鸣作用,最后形成浊音。浊音典型波形如下图:
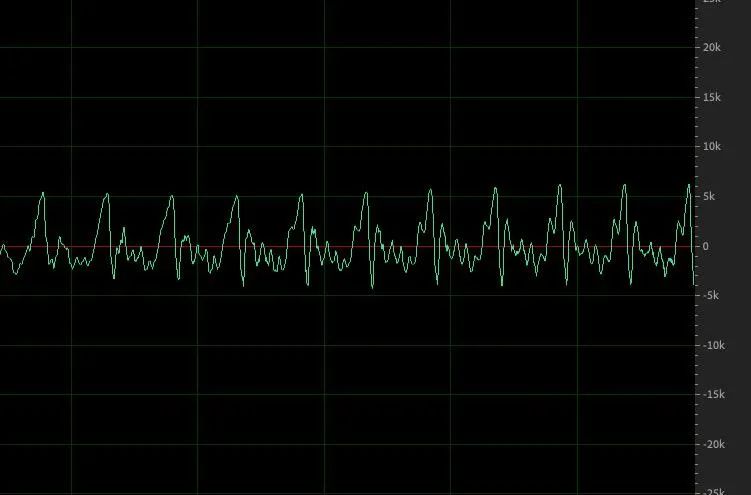
非常的周期性
轻音:空气流经过声带时,声带呈放松状态,之后在进入声道时,如果声道收缩,则气流被迫高速通过,最终产生摩擦音或者清音,如果声道某个部位完全闭合,气流经过这里则受到阻塞,气压增大,然后闭合点突然开启则最终产生爆破音。清音典型波形如下图:
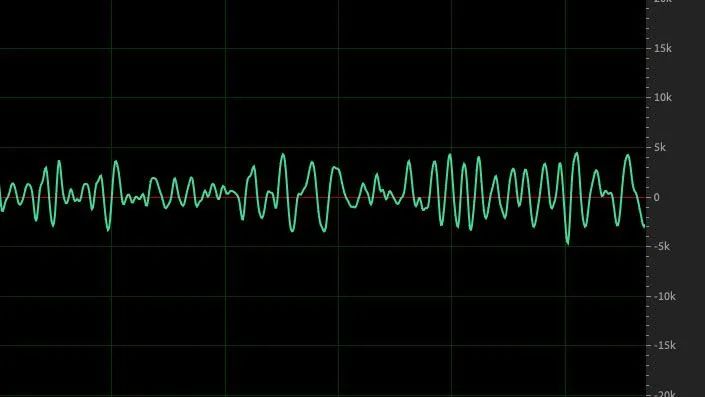
无明显周期性
3. 语音信号的特性和模型
视频编码会针对时间和空间的冗余,那语音里面是不是也有一些明显冗余呢?至少就前面的浊音来看,有非常明显的周期性,从时间轴上来看是应该有明显的冗余的,那如何进行压缩呢,另外清音是否也有类似的冗余呢?
想弄明白答案,还是要先从根本来分析,先针对人的发声系统进行建模:
需要注意的是发生浊音和清音是由完全不同的声音激励,再经过声道共鸣发出的。
浊音的语音激励近似为:脉冲信号
清音的语音激励近似为:白噪声
所以整个语音产生可以描述为一个系统,叫Speech Source-Filter Model,如下图所示:
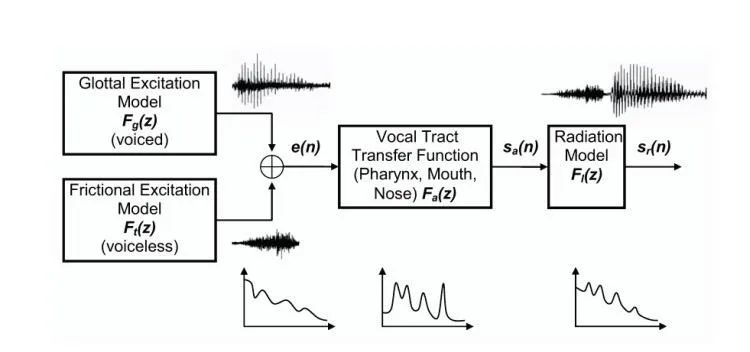
从这个模型我们可以看出来,语音的激励本身不是脉冲信号就是白噪声,基本上频谱都是比较平的,且基本不包含实际信息。而语音本身所包含的复杂信息主要是由变化的声道的处理形成的。而语音信号本身又符合短时平稳的特性。那么语音信号编码器的一个朴素的编码思想就在这里形成了:
是不是可以针对每个短时语音序列分析,由于语音的复杂性基本由声道处理形成,尝试对于这个短时语音信号的声道进行建模,然后再把简单的语音激励信号和声道模型进行编码,解码的时候就可以利用语音的激励信号,再次通过声道模型,从而让这个语音再次“说”一遍。
经过对人体生理发声的一系列基础研究,发现声道模型的传递函数是自回归滑动平均模型ARMA(Autoregressive moving average model),而ARMA模型本身就表明存在内在的相关性,即可以从历史预测未来。这也就从根本上确定了之前对于语音信号时间冗余的编码的可行性和理论基础。
总的来说,语音的产生是:激励模型G(z)、辐射模型R(z)和声道模型V(z)进行级联组合形成的,也符合ARMA模型。而建模过程为了可以方便计算经过近似,大致可以用全极点模型AR(p)过程来表达:
(1)
采用这样的一个简单模型的主要优点在于可以用线性预测分析法对增益G和滤波器系数{ } 进行直接而高效的计算。
#03
LPC线性预测
线性预测编码(LPC, Linear predictive coding)是主要用于音频信号处理与语音处理中根据线性预测模型的信息用压缩形式表示数字语音信号谱包络(spectral envelope)的工具。它是最有效的语音分析技术之一,也是低码率下编码高质量语音最有用的方法之一,它能够提供非常精确的语音参数预测。
线性预测的基本思想是:一个语音取样的现在值可以用若干个语音取样过去值的线性加权组合来逼近。
语音抽样信号s(n)和激励信号u(n)之间的关系可以用下列简单的差分方程来表示:
(2)
p阶线性预测是根据信号过去的p个取样值的加权和来预测信号的当前取样值s(n)的:
(3)
预测误差定义为:
(4)
其系统函数为:
(5)
那么A(z)和H(z)的关系如下:
(6)
此时线性预测的问题就变成求出一组预测系数{ } ,但是问题是e(n)的表达公式只有s(n)序列是已知的, 和 e(n) 都是未知的,这个方程其实是过定的,也就是解不唯一,那我们只需要找到一个“好”的解即可。而我们希望预测误差越小越好,所以预测误差的“最小均方差”就是一个很好方案,即:
(7)
然后 对于a求偏导,经过一系列的计算,最终得到了著名的Yule-Walker方程:
对于a求偏导,经过一系列的计算,最终得到了著名的Yule-Walker方程:
(8)
其中R是自相关函数,R(j-i)=E[s(n-i)s(n-j)] (i, j = 1, 2, 3, ..., p)
可以看到上面的矩阵,不仅是对称矩阵,而且平行对角线的元素也都相等,这样的矩阵称Toeplitz矩阵。这个方程组包含p+1个未知数(p个预测系数 和一个最小均方误差 ),而 到 都是已知数,可解。
另外增益模型也可以利用激励信号的为白噪声的均方误差为1且自相关函数为0的特性得出:
(9)
PS: 即使在浊音的情况下,由于一串脉冲信号在大部分时间也是非常小的,所以使用最小的预测误差e(n)逼近u(n)和u(n)能量很小不矛盾。
至此公式(1)内的全极点模型的所有参数都解出来了。
#04
Levinson-Durbin算法与格型滤波器
全极点模型的参数在可以计算的前提下,实际应用特别是对编码传输来说还是有很大痛点:
解方程需要求矩阵的逆,非常的消耗计算量;
AR的模型里面使用的是FIR滤波器,直接型FIR特别是高阶的对于滤波系数的量化误差异常敏感。
那么怎么解决呢?首先来看如何快速求解预测参数。
1. Levinson-Durbin算法
对于求解Yule-Walker方程,由于Toeplitz矩阵自己的特性,可以得到一种有效的迭代算法,论证的过程这里就不详细写了,相信有很多资料都可以查到。这个算法是一个迭代计算的过程,从最低阶往上计算逐步递推。不仅求出了所有的p阶预测系数,还得到了所有低阶预测系数,具体过程如下:

其中 又称为是反射系数,并且只有 ,才能保证系统H(z)稳定,且 和 是一一对应的。
2. 格型滤波器
有了 这个中间变量后, 把预测滤波器的低阶系数和高阶系数联系到了一起:
j = 1,2,3,...,i-1
(10)
那么既然反射系数 和预测系数替换,系统都由反射系数表达会变成什么样呢?
原本FIR滤波器的时域差分方程为:
(11)
由于这里 是从之前i个采样点来预测s[n]时产生的误差,所以称为:前向预测误差。
(12)
再将公式(10)带入并推导,最后得到的时域解释为:
(13)
这里 则是根据样本(n-i)之后的i个样本点预测得到的,所以这个 又被称为后向预测误差。
前向和后向表达里的预测系数 替换成 的表达为:
(14)
(15)
那么根据(13)(14)递推公式,已知我们知道s[n]求 ,p阶预测误差滤波器由 表达如下,且各阶前向和后向误差也如下图:

而语音的发声的全极点建模如下图:
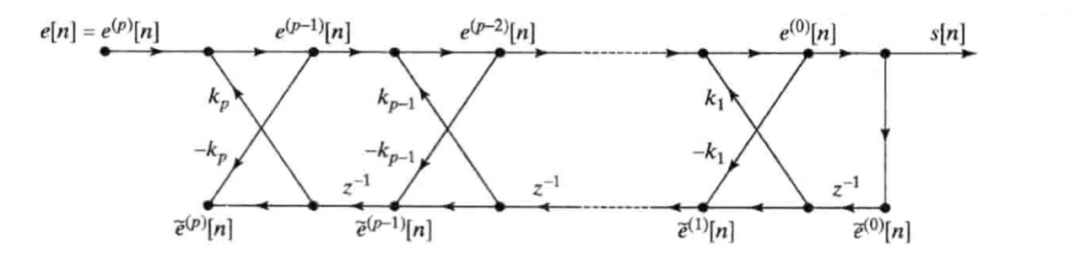
缺点:输出每个样本所经历的计算量是普通直接型滤波器的两倍。
优点:只要保证反射系数 ,就不会使得系统不稳定。
特别是高阶型的滤波器对于系数的量化非常敏感,量化误差稍大就可能导致系统不稳定,所以在需要对系数粗量化时,格型滤波器仍然是最优的实现方法。
#05
LPC的全极点模型阶数的影响
线性预测编码里的全极点建模提供了一种从截取或加窗数据中获得一个高分辨率信号频谱的方法。但这是基于一个前提,即如果参数信号数据和模型互相拟合,那么可以用数据的有限长区间段来确定模型参数,进而也确定了其频谱。
是不是LPC的全极点模型的阶数越高越精确呢?
如果s[n]本身就是全极点系统生成的,那么只要估计方案选择得当,使用高于原生成系统的阶数意义并不大。而即使信号s[n]本身不能用一个全极点系统来精确建模,通常也会存在一个p的取值,在该值之上再增大时,对于预测误差的影响就会非常小或者没有影响。而这个阈值将表明一个全极点模型阶数的有效选择。
那么如果在有效阶数一下,降低p的取值会对建模本身带来多少误差呢,或者说误差主要表现在哪里呢?
这里直接给出一个基于线性预测全极点重建数据频谱包络在不同p值之下和原信号的对比图:
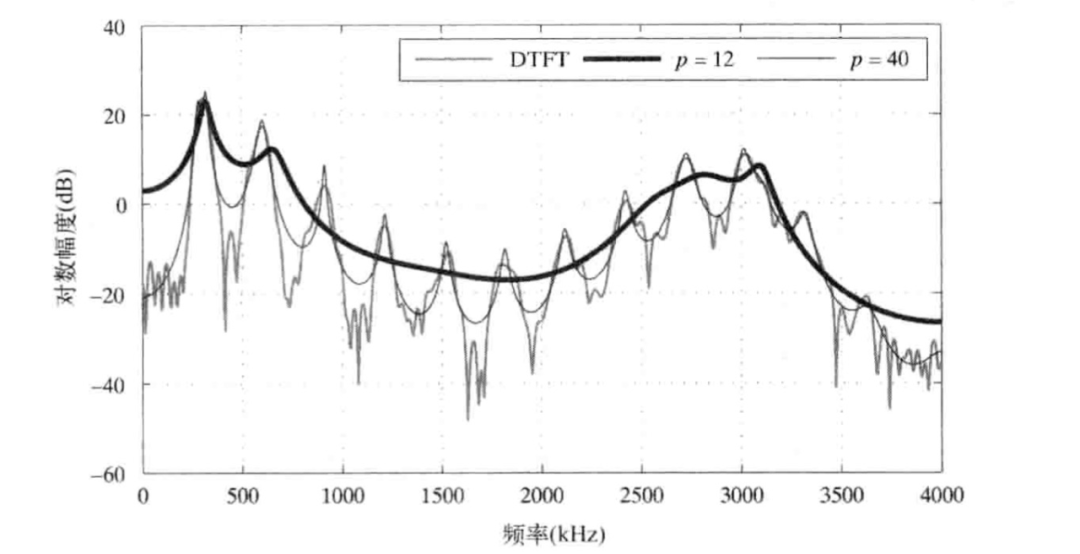
有图可见,降低LPC的全极点模型的阶数和原信号的频谱的对比表明了,其重建信号在阶数越低的情况下其频谱包络越平滑(如图:p=12),而越高的阶数(p=40)则能表现更多的细节。所以基于LPC的编码器的码率肯定会影响模型的阶数和量化的精度,由此也能看出重建声音在低码率下的音质并不能表现更多细节了。
#06
总结
本文介绍了基于线性预测的编码器的主要工作原理,更说明了各个部分的设计缘由、特点、缺陷等,希望读者可以对整个编码主体部分的分工和由来有一个基本概念。很多推导过程都已省略,相信很多书籍和材料都能查到相应算法的具体推导。另外这也只是基于LPC编码器编码的主体原理,实际应用时,编码器可能还会有很多其他模块,比如熵编码模块、抵抗量化噪声的模块等等。
扫描图中二维码或点击阅读原文
了解大会更多信息















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









