






前言
在开始讲这个问题前,大家要知道栈是如何运用的。
很多人会说,“就是后进后出嘛”,那我要以一个大家在数据结构课上应该遇到过的问题开始今天的讲解:利用栈,输入【A,B,C】(入栈顺序)有多少种输出结果:
答案是五种,ABC、ACB、BAC、BCA、CBA,每次输入和输出的顺序不同可以产生很多结果,这也是我们利用栈思考问题的核心思想。
接下来,无痛解决二叉树遍历问题,本文将主要讲解迭代解法,递归的方法较为简单。
简单讲一下递归
/* 前序遍历 */
void preOrder(TreeNode root) {
if (root == null)
return;
// 访问优先级:根节点 -> 左子树 -> 右子树
list.add(root.val);
preOrder(root.left);
preOrder(root.right);
}
/* 中序遍历 */
void inOrder(TreeNode root) {
if (root == null)
return;
// 访问优先级:左子树 -> 根节点 -> 右子树
inOrder(root.left);
list.add(root.val);
inOrder(root.right);
}
/* 后序遍历 */
void postOrder(TreeNode root) {
if (root == null)
return;
// 访问优先级:左子树 -> 右子树 -> 根节点
postOrder(root.left);
postOrder(root.right);
list.add(root.val);
}我对于递归方法的理解很简单,以前序遍历为例子,优先级是根节点 -> 左子树 -> 右子树,所以添加中间节点的值,再将左孩子传入递归,这使得左孩子作为中间节点被添加。
解决完递归,接下才是重头戏,利用栈解决二叉树的遍历。
前序
访问优先级:根节点 -> 左子树 -> 右子树
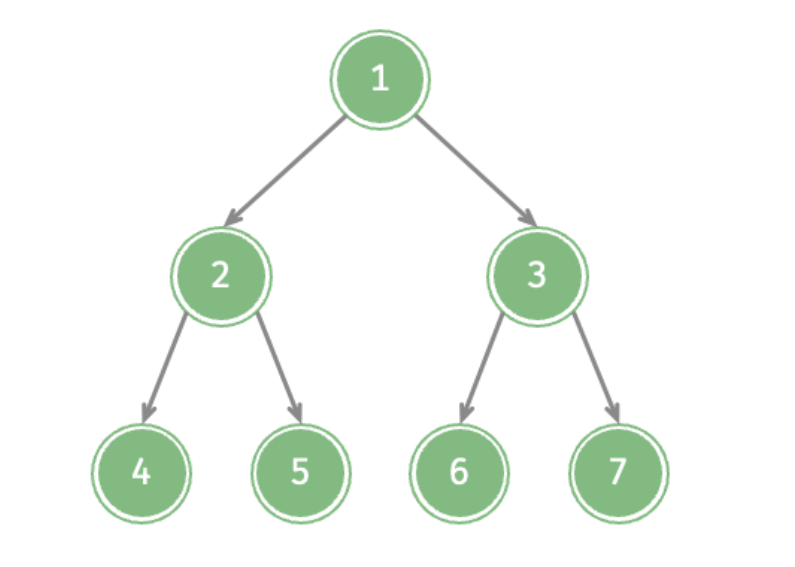
如图,通过前序遍历得到的输出应该是:1,2,4,5,3,6,7
我们对输出的顺序有要求,很自然想到栈这种数据结构,那是直接构造一个这样的栈【7,6,3,5,4,2,1】吗,显然不行,或者说就算实现了花费也很多,需要从root(1)不断遍历。
这就回到前言部分的问题了,大部分人尤其是新手很难利用栈来控制输出顺序,接下来,我们就可以把问题转化为已知输出顺序、输入顺序,写出实现程序。
这里,还要结合树的性质:
- 每一个节点都可以是根节点
- 遍历从左到右
开始分析
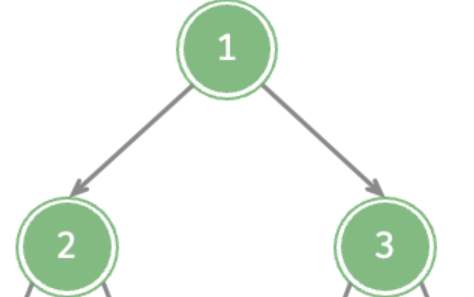
我们从简单入手,对于这颗树,我们会先将1输出到List中,然后是2所在的子树,最后是3所在的子树。
很自然想到先把1压入,然后压出,紧接着把3、2压入,然后取出2重复对于1的操作。
这样说可能还是抽象了点,我们画个图:

这样,我们就能输出想要的顺序
代码实现
按照上面画的图:
- 每一次我们将栈顶弹出,对栈顶和其孩子操作
- 栈顶元素输入list
- 其孩子按照右左的顺序入栈(输出就是左右)
可以写出下面的代码:
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
//加个边界条件判断
if (root == null)
return list;
Deque<TreeNode> stack = new LinkedList<>();
stack.push(root);//压栈
while (!stack.isEmpty()) {
TreeNode t1 = stack.pop();//出栈
list.add(t1.val);
if (t1.right != null) {//压入右孩子
stack.push(t1.right);
}
if (t1.left != null) {//压入左孩子
stack.push(t1.left);
}
}
return list;
}
}中序
访问优先级:左子树 -> 根节点 -> 右子树
中序遍历的难度在前序至上,但是按照我们之前的思路一样可以做出来。
开始分析

还是这个图,这时的处理顺序不在是1输入list,然后是2及其子树、3及其子树,要注意的是,也不是先2输入list,虽然先访问的是2,但是2作为中间节点时,应该先访问它的左孩子4。
实际上,我们需要从下到上分析:
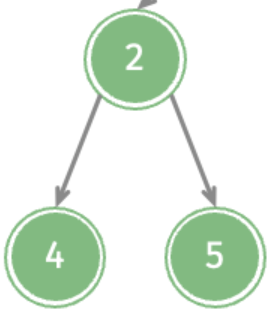
考虑这个子树,输出顺序是4、2、5,还是一样的问题,构建一个【5,2,4】的栈不太行,为了实现我们需要的顺序,我们可以【4】、【5,2】、【5】、【】:

但是这样有个问题,我们的访问是自上而下的访问,也就是所4无法直接得到2,也就无法得到5,所以上面的步骤无法实现。
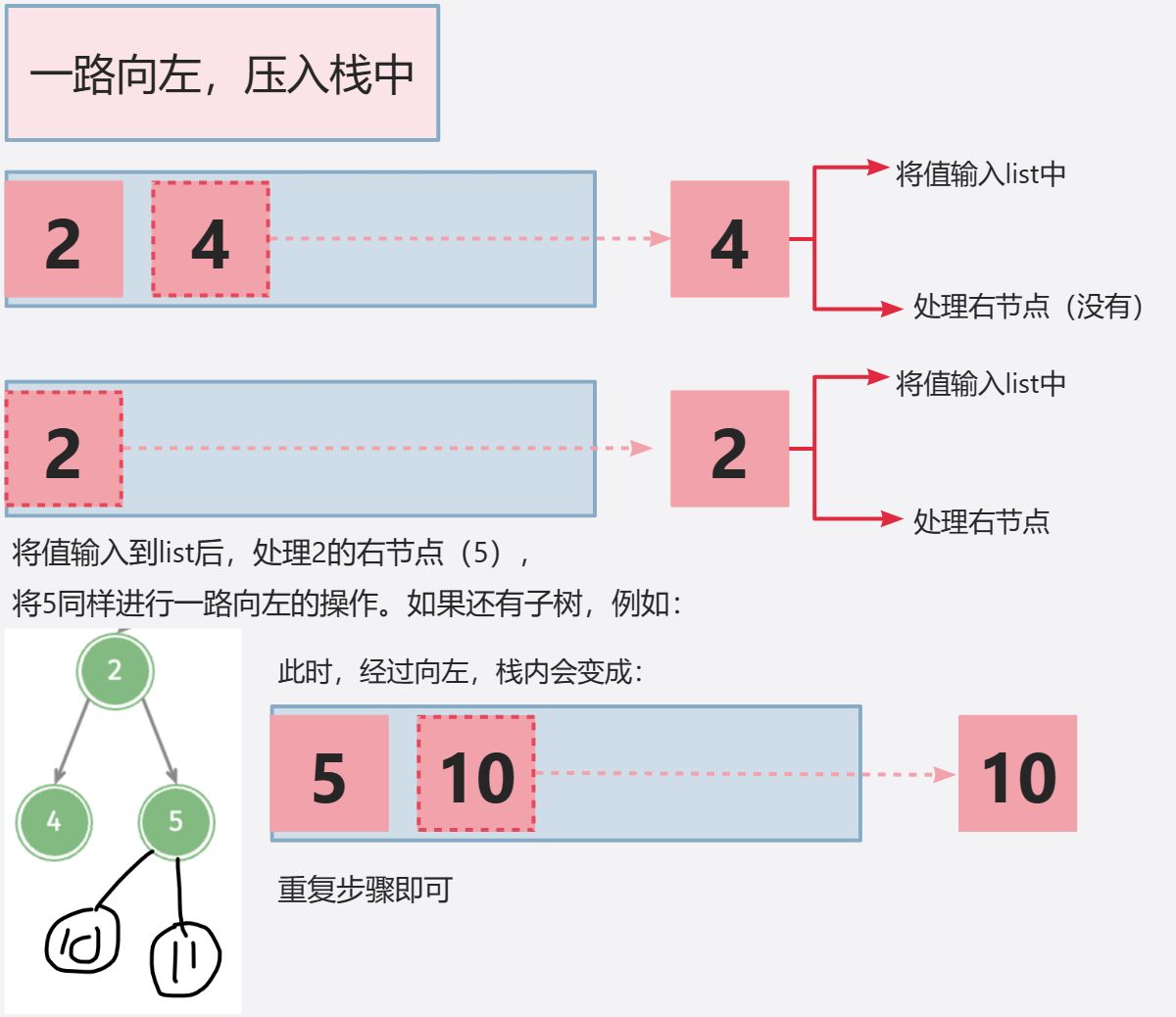
想想,我们在得到4入栈经过了那些步骤?
答案是一路向左,我们访问很多左节点,如果把它们按照访问顺序压入栈中,此时4不用得到2,2就在栈中,弹出来就好,5可以由2直接得到!换句话说,我们可以向前序遍历那样,针对每一次弹出的节点完成不同的操作从而完成遍历。如图:
代码实现
每一部分都可以直接写出,得到完整的代码
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
Deque<TreeNode> stack=new LinkedList<>();
ArrayList<Integer> list=new ArrayList<>();
TreeNode cur=root;
while(cur!=null||!stack.isEmpty()){
while(cur!=null){//这个嵌套的循环执行“一路向左”
stack.push(cur);
cur=cur.left;
}
cur=stack.pop();//此时栈顶为最左,取出入list
list.add(cur.val);
cur=cur.right;//处理栈顶元素的右孩子,cur会进入下一次循环
}
return list;
}
}后序
访问优先级:左子树 -> 右子树 -> 根节点
后序遍历实际上更难,但如果你完全理解了中序遍历,那后序遍历就是在中序遍历上的该进。
开始分析

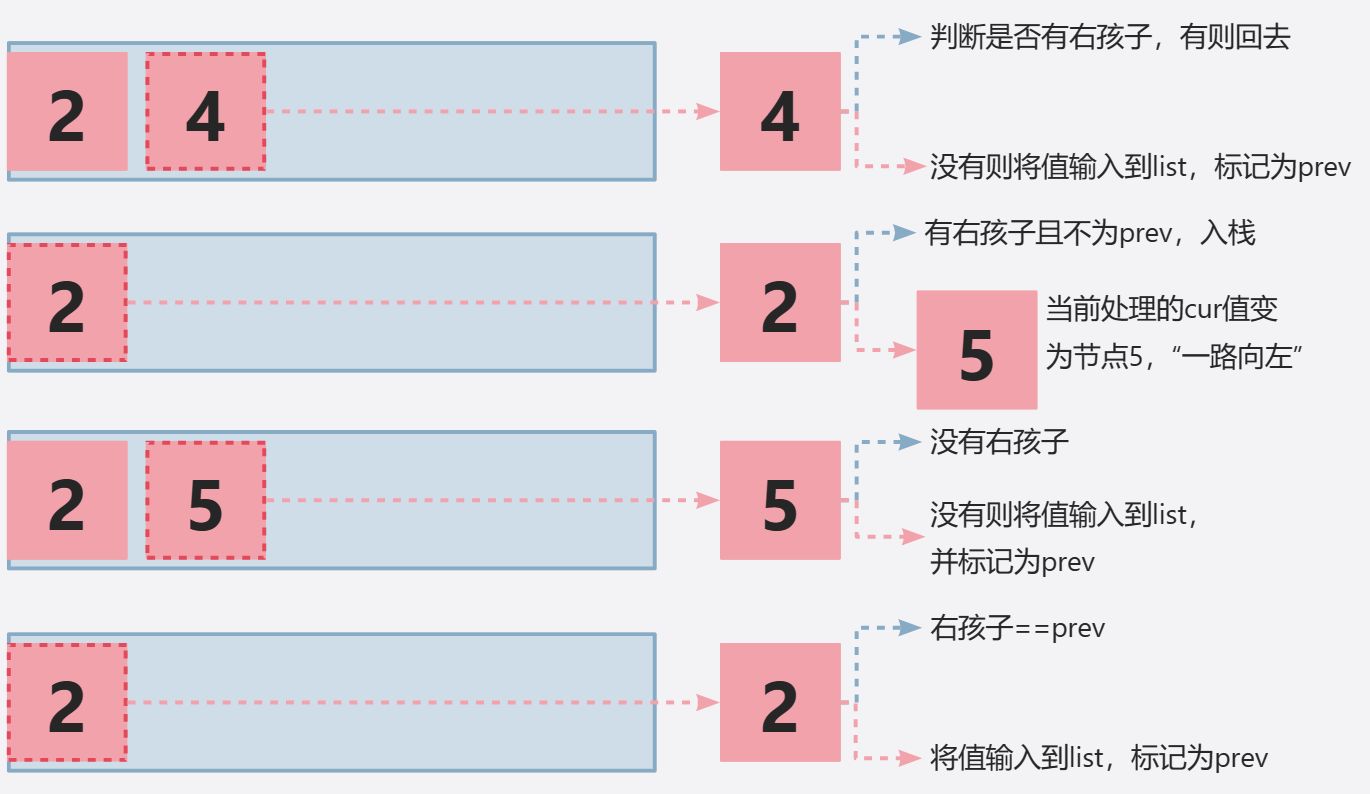
显然,我们还是从下到上分析,对于这个子树,我们会输出【4,5,2】,在理解中序遍历后我们知道,这其中会包含一个一路向左的操作,紧接着【5,2】,诶,要访问2必须先访问5,但是这里先输出5,好像事情开始变得复杂。
看完前两个部分,很多读者会注意到,我一直强调针对栈顶元素进行操作,按照一路向左的操作,我们得到【2,4】,4弹出后输入到list,然后是2弹出,针对2的右孩子进行操作后,我们还要回到2,所以我们可以将2再次压入栈中。
很多人虽然恍然大悟,但却不以为然,笔者认为这时栈的另外一个很重要的思想,输入【A,B,C】,出栈的顺序只有6种,但我们对元素的重复入栈可以使得结果变得更多样。
所以,当我们的栈顶元素有右孩子的时候,下一个被处理的元素(cur)就指向其右孩子,然后将栈顶元素压回去。
但还有个问题,比如这里处理2的右孩子时,下一次取出2我们仍然会判断是否有右孩子,导致死循环,所以我们需要一个标记来标识右孩子是否被遍历过。比较常见的就是当节点值被添加到list中,就标记为prev,判断当前栈顶元素cur.right和prev是否相等即可。
代码实现
上面每一步都可以直接实现。
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<Integer>();
if (root == null) {
return res;
}
Deque<TreeNode> stack = new LinkedList<TreeNode>();
TreeNode prev = null;
while (root != null || !stack.isEmpty()) {
while (root != null) {//“一路向左”
stack.push(root);
root = root.left;
}
root = stack.pop();//取出栈顶,记住我们的原则是对栈顶进行处理
if (root.right == null || root.right == prev) {//没有右孩子或者已经访问过
res.add(root.val);
prev = root;
root = null;
} else {//右孩子没被访问过
stack.push(root);
root = root.right;
}
}
return res;
}
}
关于后序遍历的其他问题
我们已经学会了如何利用栈解决后序遍历,但还有些有趣的问题想和大家分享。
我们注意到,我们实现的后序遍历和中序遍历很相似,只是在其基础至上添加了一点东西而已,从优先级也可以看出:
中序:左子树 -> 根节点 -> 右子树
后序:左子树 -> 右子树 -> 根节点,都是左节点访问最高,有了统一的”一路向左“
前序:根节点 -> 左子树 -> 右子树,这时候,很多人会注意到,前序和后序极其相似,只有根节点的位置不同,于是我们有了其他解决后序遍历的方法。
由前序得到后序
我们发现当前序遍历优先级改为:根节点 -> 右子树 -> 左子树,然后最后的list结果反转一下,我们就得到了后序遍历的结果!
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
//加个边界条件判断
if (root == null)
return list;
Deque<TreeNode> stack = new LinkedList<>();
stack.push(root);//压栈
while (!stack.isEmpty()) {
TreeNode t1 = stack.pop();//出栈
list.add(t1.val);
//if语句的顺序改一下
if (t1.left != null) {//压入左孩子
stack.push(t1.left);
}
if (t1.right != null) {//压入右孩子
stack.push(t1.right);
}
}
//最后利用Collections工具类实现反转
Collections.reverse(list);
return list;
}
}但是不建议使用,实测下来,这种方法时间复杂度相对较高,最关键的是,他没有真正地实现后序遍历,只是返回的一个和后序遍历一样的结果,如果我们要对搜索过程进行某些操作,这将无法正确执行。















 1999
1999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









