







json的介绍
1.个人所理解的json就是一个与xml类似的数据存储文件,
而且也比xml容易写和读,跟python中字典很相似,本篇文章也是直接保存字典。
2.https://baike.baidu.com/item/JSON/2462549?fr=aladdin
此链接详细介绍了json的作用以及书写规范,反正就是很简单,一扫而过即可。
3.json不是重点,重点是爬取数据啊,兄嘚们。
4.送你们一张爬取完数据的json文件截图。
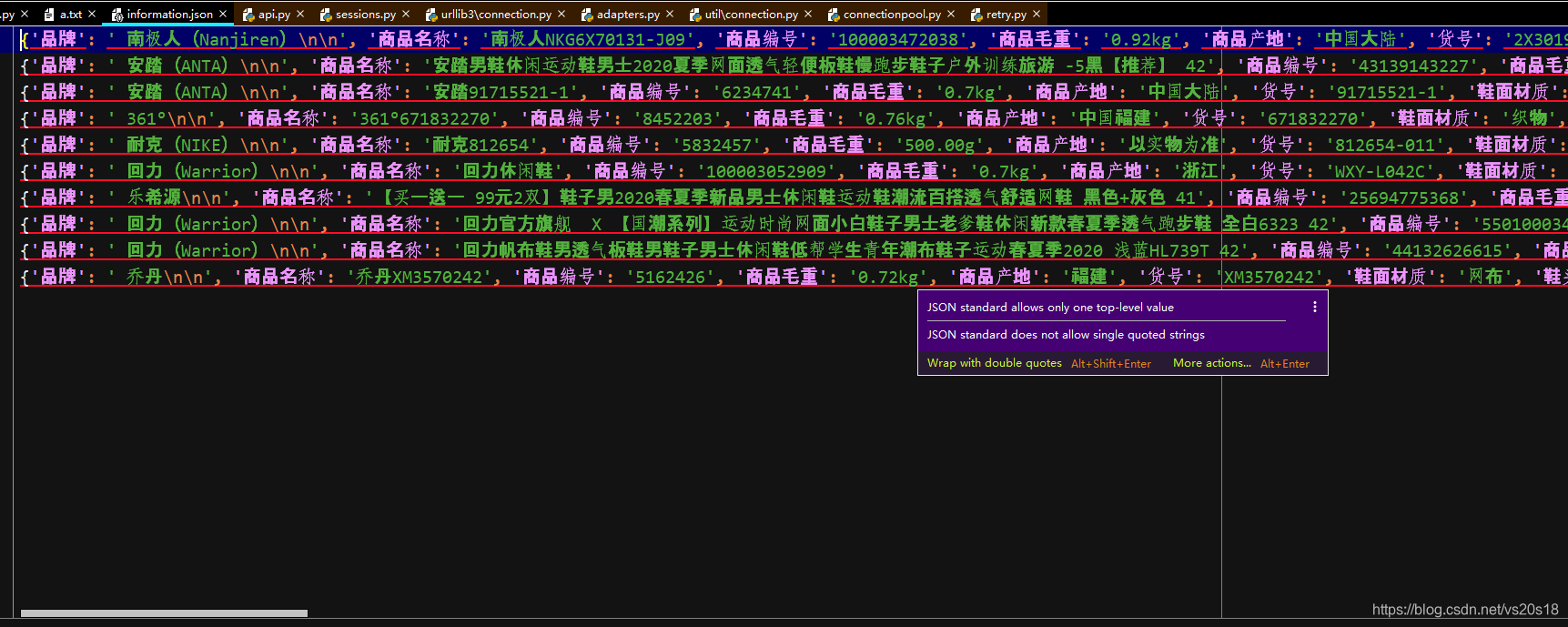
网页数据爬取的思路
1实现搜索url
首先我们应找到我们想要的网站,如:

分析这俩图的url即可得知关系所在,https://search.jd.com/Search?keyword=%E7%89%9B%E5%A5%B6,%E7%89%9B%E5%A5%B6是牛奶的转义字符,所以只需要改这个便可找到自己的搜索内容,当然,我们并不需要手动转移,目前爬虫模块已经做的非常强大了可以自动转译。
def input_in():
url1 = 'https://search.jd.com/Search?keyword='
url2 = input("请输入要搜索的商品")
try:
limit = int(input("请输入需要数据收集的条数(默认为10)"))
if limit=='':
limit=10#默认搜索条数
except:
limit = 10
file = input("请输入搜索商品返回信息的保存路径,(默认为information.json文件")
if file == '':
file = 'information.json'#默认路径
print(file)
url = url1 + url2
s=url_html(url)#合成网页
herfs=read_first(s,limit)#处理第一层网页源代码,并放回需要二次处理的信息
read_end(herfs,file)#提取最终的商品信息,并保存json文件
2.转载网址的二次处理
分析二层url信息,得知发现与li里的data-sku值有关,那么进行提取即可
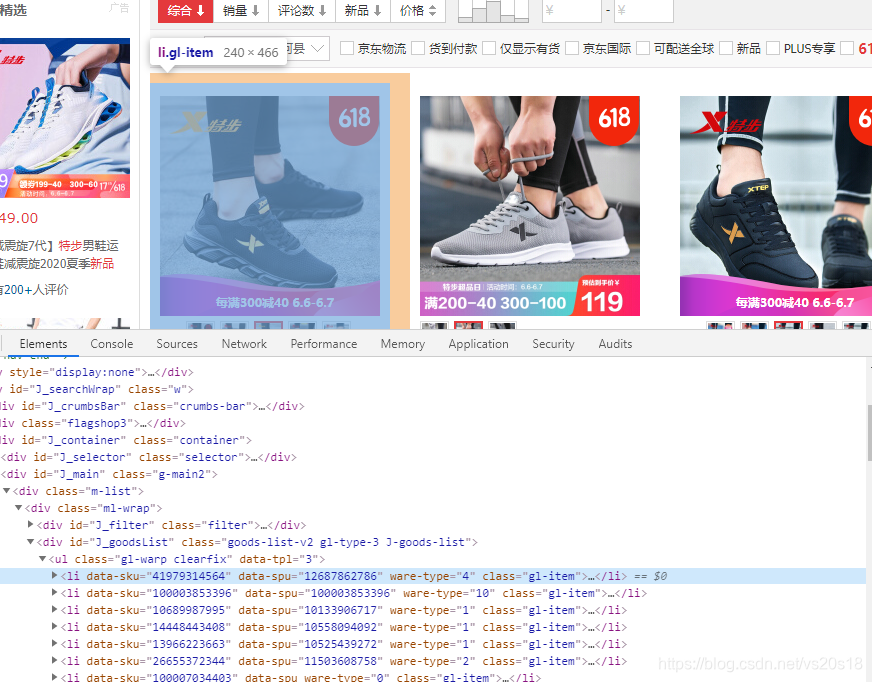
注1: 这里有一个小技巧,chrome可以使用快捷键12分析网页源代码,并且鼠标放在源代码上,改代码实现的某个功能区域会深色选中,能狗更好的帮你分析代码。
提取代码技巧有很多,在这里只示例一种,进行多次筛选依次如下:
先find找到’div’,class_=‘ml-wrap’------------>‘div’, id=“J_goodsList”-------------->‘li’,limit=limit, class_=‘gl-item’
最后再提取li中的 data-sku属性值即可。为了能够直接搜索又拼接了一下字符。‘https://item.jd.com/’ + str(herf.get(‘data-sku’)) + ‘.html’
def read_first(s,limit):
soup = BeautifulSoup(s, 'lxml')
# print(soup)
# item = soup.find('div', id="J_goodsList", class_="goods-list-v2 gl-type-1 J-goods-list")
item1=soup.find('div',class_='ml-wrap')
item2= item1.find('div', id="J_goodsList")
herfs=[]
# print(item2)
a_herf = item2.find_all('li',limit=limit, class_='gl-item')
for herf in a_herf:
# print(herf.get('data-sku'))
herfs.append('https://item.jd.com/' + str(herf.get('data-sku')) + '.html')
return herfs
3.提取所需信息,并保存为json格式
跟上面一样,找规律
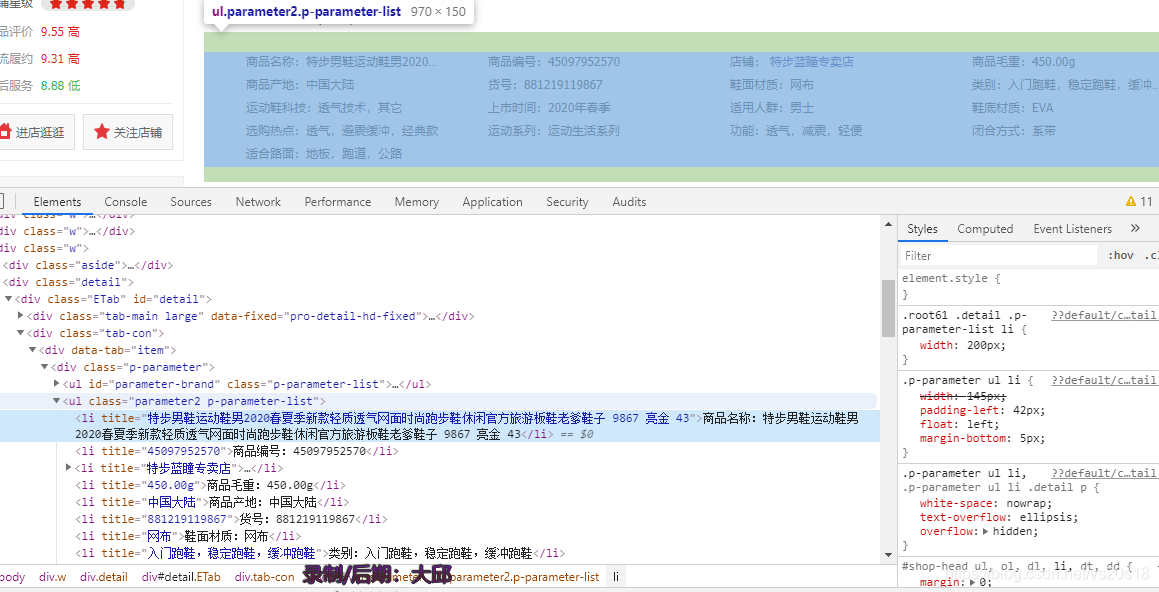
先定位’div’, class_=‘p-parameter’,然后再查找li即可,这个稍微简单一些,所以直接保存json格式文件,上边已经详细介绍了json文件,所以不多说,直接上代码。
def read_end(urls,file):
y = {}
a=""
for url in urls:#循环爬取多个页面信息
print(url)
html = url_html(url)
soup = BeautifulSoup(html, 'lxml')
# ul_tag = soup.find('ul', class_='parameter2 p-parameter-list')
ul_tag = soup.find('div', class_='p-parameter')
# <ul class="parameter2 p-parameter-list">
li_tag = ul_tag.find_all('li')
for li in li_tag:
string = li.text
n = 0
m = ""
for s in string:
if s == ":":
break
else:
n += 1
m = m + s
y[m] = string[n + 1:]
a+=str(y)+"\n"
with open(file, 'w+', encoding='utf-8')as f:
print(a)
f.write(str(a))
全部文件代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/6/7 12:07
# @Author : 沐白
# @Site :
# @File : test1.py
# @Software: PyCharm
import random
import requests
from bs4 import BeautifulSoup
def url_html(url,):
heanders_list = [
{
'authority': 'list.jd.com',
'method': 'GET',
'path': '/list.html?cat=9987,653,655', # 这个参数可变可不变,不影响请求结果
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'shshshfpa=5c6cc71b-f7c9-c599-4cf2-b2c77ee0ff76-1568857061; __jdu=1342884474; shshshfpb=z7w%20Zoy0K6j7B5LKkhdAtYw%3D%3D; pinId=rRxdLVRyxcB4XFEJGa59I7V9-x-f3wj7; TrackID=1liVQSk1qNZWq_Ga8sbgqj-cYmyMpu5UDkT_Ygy0C5PgOITxNMb2QT0kd0tJGMUuCHDOoL1cHAxkNW5WKWj9vqX7huGlNhOFUXy737p4NXeUIvIzbXXY-qTBCqmq7VwKv; areaId=1; ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbUsDRRwhAEZXfh5cUWIFG1USAkFFdQ4VUXIaWVdnABEPclRCFX0URlRnGVwUZwIZXkBcQhdFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHsbWQZuChdYRFJzJXI4dmRyGlUCYQEiXHJWc1chVEFdeRpaBioDEFhBXkoQcA5DZHopXw%3d%3d; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_8e78e912461e4789ad3a17b4824c122c|1573438988187; __jda=122270672.1342884474.1568857058.1573271812.1573438988.18; __jdc=122270672; 3AB9D23F7A4B3C9B=4PFOE7YRYMBCJARAACFDMACWRPBQLCMUZI2KCG5LYJZPHDLZJ6RP2UTRQJECD2VOPDWR4QDPHG27LGM54A2YU5RREA; shshshfp=05bd1f8771fac98bc434e4f64273ce8b; listck=7fecc6cf9704f1375fe8495d6f662ffd; _gcl_au=1.1.285951031.1573439265; __jdb=122270672.6.1342884474|18.1573438988; shshshsID=2ed194eabc3c4f9c0c06c4b18e4ff17e_5_1573439385602',
'if-modified-since': 'Mon, 11 Nov 2019 02:27:40 GMT',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
},
{
'Accept': 'text/html,application/xhtml+xml,application/x',
'Accept-encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Referer': 'https://extract_items.taobao.com/extract_items.htm',
'Upgrade-insecure-requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Connection': 'keep-alive',
'content-type': 'utf-8',
}
]
headers = random.choice(heanders_list)#使用两套headers,能有有效解决大部分的反爬机制
res = requests.get(url, headers=headers)#请求网页,并返回网页源代码
return res.text
def input_in():
url1 = 'https://search.jd.com/Search?keyword='
url2 = input("请输入要搜索的商品")
try:
limit = int(input("请输入需要数据收集的条数(默认为10)"))
if limit=='':
limit=10#默认搜索条数
except:
limit = 10
file = input("请输入搜索商品返回信息的保存路径,(默认为information.json文件")
if file == '':
file = 'information.json'#默认路径
print(file)
url = url1 + url2
s=url_html(url)#合成网页
herfs=read_first(s,limit)#处理第一层网页源代码,并放回需要二次处理的信息
read_end(herfs,file)#提取最终的商品信息,并保存json文件
def read_first(s,limit):
soup = BeautifulSoup(s, 'lxml')
# print(soup)
# item = soup.find('div', id="J_goodsList", class_="goods-list-v2 gl-type-1 J-goods-list")
item1=soup.find('div',class_='ml-wrap')
item2= item1.find('div', id="J_goodsList")
herfs=[]
# print(item2)
a_herf = item2.find_all('li',limit=limit, class_='gl-item')
for herf in a_herf:
# print(herf.get('data-sku'))
herfs.append('https://item.jd.com/' + str(herf.get('data-sku')) + '.html')
return herfs
def read_end(urls,file):
y = {}
a=""
for url in urls:#循环爬取多个页面信息
print(url)
html = url_html(url)
soup = BeautifulSoup(html, 'lxml')
# ul_tag = soup.find('ul', class_='parameter2 p-parameter-list')
ul_tag = soup.find('div', class_='p-parameter')
# <ul class="parameter2 p-parameter-list">
li_tag = ul_tag.find_all('li')
for li in li_tag:
string = li.text
n = 0
m = ""
for s in string:
if s == ":":
break
else:
n += 1
m = m + s
y[m] = string[n + 1:]
a+=str(y)+"\n"
with open(file, 'w+', encoding='utf-8')as f:
print(a)
f.write(str(a))
if __name__ == '__main__':
input_in()














 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









