







前一篇文章简单介绍了推荐系统,并列出了常用的推荐算法,这篇主要就如何实现推荐做说明。本来最开始打算用movielens的电影数据来做推荐,数据集下载地址如下,http://grouplens.org/datasets/movielens/,我下的是1m左右的数据,用户6040个,电影3952个,我在构建用户相似度矩阵的时候居然从下午4:00一直跑到晚上2:30,用户相似度需要构建一个6040*6040的矩阵,并且用户与用户之间需要做3952次循环比较,所以时间很长,明显这个例子不适合在我的电脑上做demo。所以自己构建一个demo数据集,结构类似movielen的电影评分。
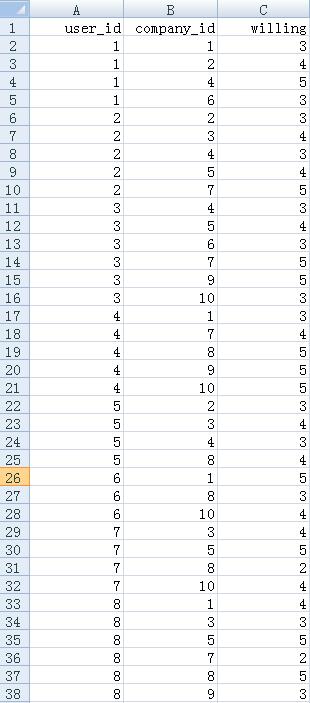
构造的数据集是这样一种场景,有8个用户对10家公司投递简历,并且有用户对公司投递简历的意愿(数值从1到5,5表示强烈的想去该公司上班)。
推荐思路:
首先根据原始数据集对数据进行预处理,构造一个用户-公司的二维矩阵,二维矩阵对应的值是用户对去该公司工作的意愿,本示例程序采用基于用户的推荐(基于item的推荐和基于用户的推荐思路一样)思路,根据用户-公司二维矩阵,计算用户之间的相似度,以上两个矩阵都可以直接保存成文件(在实际应用中会离线计算然后存数据库或其它存储介质),方便直接调用,根据以上两个矩阵,对用户做推荐。
对用户做推荐的逻辑是,首先找出目标用户没有投递简历的公司,再找出和目标用户相似度最高的5其他用户投简历的公司,并且是目标用户没有投过的,来计算目标公司,我们采用两种方式来实现,一种是返回topn,另外一种是根据工作意愿的评分。
如何判断两个用户相似,我们做如下定义:
A用户投了1,2,3,4
B用户投了2,3,4,5
AB相似度= 用户投了A也投了B/((A投的公司数*B投的公司数据)的平方根)
以上计算的结果AB的相似度为3/4=0.75,如果AB投的公司完全样,AB的相似度为1
相似度并不影响推荐结果。
用户-公司矩阵(横轴代表公司,纵轴代表用户)
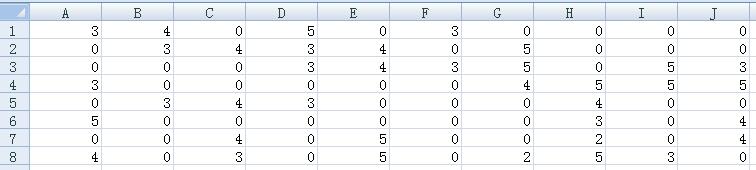
用户相似度矩阵
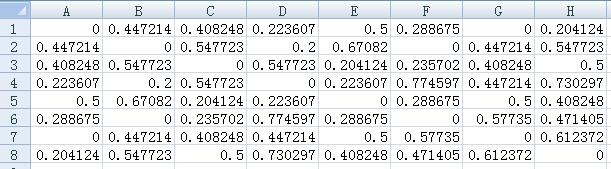
用户相似度矩阵是个8*8的矩阵,行列都代表用户,对角线元素为0,1B表示的意思是第一个用户和第二个用户的相似度
运行结果如下:
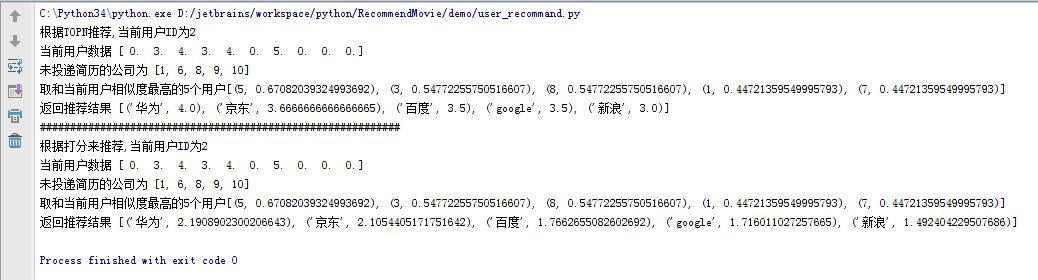
调整用户相似度的数量会影响输出结果,并且采用topn和打分返回的结果也有不同。
相关代码:
#用户公司相关矩阵
def get_user_company_mat():
user_job_data = load_demo.load_demo_data()
user_job_mat = np.zeros((8,10))
#logging.info("生成用户和公司相关矩阵开始")
for idx, row in user_job_data.iterrows():
user_id = row["UserID"]
company_id = row["CompanyID"]
rating = row["Rating"]
user_job_mat[user_id-1,company_id-1] = rating
return user_job_mat
#用户与用户相似性矩阵
def get_user_similarity_mat():
user_company_mat = user_company.get_user_company_mat()
user_length, company_length = user_company_mat.shape
user_sim_mat = np.zeros((user_length, user_length))
#logging.info("构建生成用户相似性矩阵,用户和用户比较")
for m in range(0, user_length):
user_m = user_company_mat[m, :]
user_m_job_number = 0;
for item_index in range(0, company_length):
if user_m[item_index] > 0:
user_m_job_number = user_m_job_number + 1
#logging.info("当前用户" + str(m) + "投递的" + str(user_m_job_number) + "份简历")
for n in range(0, user_length):
#logging.info("第" + str(m) + "个用户和第" + str(n) + "个用户比较")
if m == n:
user_sim_mat[m, n] = 0
else:
similarity_item = 0
user_n_job_number = 0
user_n = user_company_mat[n, :]
for i in range(0, company_length):
if user_n[i] > 0:
user_n_job_number = user_n_job_number + 1
if (user_m[i] > 0 and user_n[i] > 0):
similarity_item = similarity_item + 1
#logging.info("当前用户" + str(n) + "投递的" + str(user_n_job_number) + "份简历")
if (user_m_job_number == 0 or user_n_job_number == 0):
user_sim_mat[m, n] = 0
user_sim_mat[n, m] = 0
else:
user_sim_mat[m, n] = similarity_item/math.sqrt(user_m_job_number*user_n_job_number)
user_sim_mat[n, m] = similarity_item/math.sqrt(user_m_job_number*user_n_job_number)
#data_frame = pd.DataFrame(user_sim_mat)
#data_frame.to_csv('user_similarity_mat.csv', index=False, header=False)
#logging.info("构建生成用户相似性矩阵结束")
return user_sim_mat
#返回的topN的结果(打分的代码类似)
def user_recommand_by_topn(user_id):
print("根据TOPN推荐,当前用户ID为"+str(user_id))
user_job_mat = user_company.get_user_company_mat()
current_user_job_record = user_job_mat[user_id - 1, :]
print("当前用户数据",current_user_job_record)
un_rating_company = []
for company_id, company_rating in enumerate(current_user_job_record):
if company_rating == 0:
un_rating_company.append(company_id + 1)
print("未投递简历的公司为",un_rating_company)
user_sim_mat = user_similarity.get_user_similarity_mat()
current_user_sim = user_sim_mat[user_id - 1, :]
user_sim_dic = {}
for user_id, user_sim_value in enumerate(current_user_sim):
user_sim_dic[user_id+1] = user_sim_value
user_sim_dic = sorted(user_sim_dic.items(), key=lambda a: a[1], reverse=True)
print("取和当前用户相似度最高的5个用户"+str(user_sim_dic[0:5]))
#print(user_sim_dic)
result_dic = {}
for un_rating_company_id in un_rating_company:
sim_company_similarity = 0
sim_company_rating_total = 0
sim_company_rating_item_num = 0
for item in user_sim_dic[0:5]:
sim_usr_id = item[0]
sim_usr_val = item[1]
sim_company_rating = user_job_mat[sim_usr_id - 1, un_rating_company_id - 1]
if sim_company_rating > 0:
sim_company_rating_total = sim_company_rating_total + sim_company_rating
sim_company_rating_item_num = sim_company_rating_item_num + 1
if sim_company_rating_item_num > 0:
average_sim = sim_company_rating_total / sim_company_rating_item_num
result_dic[demo_util.get_company_des(un_rating_company_id)] = average_sim
result_dic = sorted(result_dic.items(), key=lambda a: a[1], reverse=True)
print("返回推荐结果",result_dic)















 2985
2985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









