







Python+Miner解析PDF
这个事呢,我们直接来吧,参考资料么一篇文档【312】Python提取pdf文本内容,官方参考文档在这里
一、安装
首先我们得明确一点,就是你的电脑上得有Python,版本无所谓
其次,我们得安装PdfMiner,安装方法比较简单,直接安装就行
pip install pdfminer
二、目标
将下方图片中得上方得pdf文件内容读取出来,保存到excel中,保证能够获取到站点名称和站点经纬度,还需要读取到两个站点之间得距离,但是距离这里有点小问题,所以就没有弄。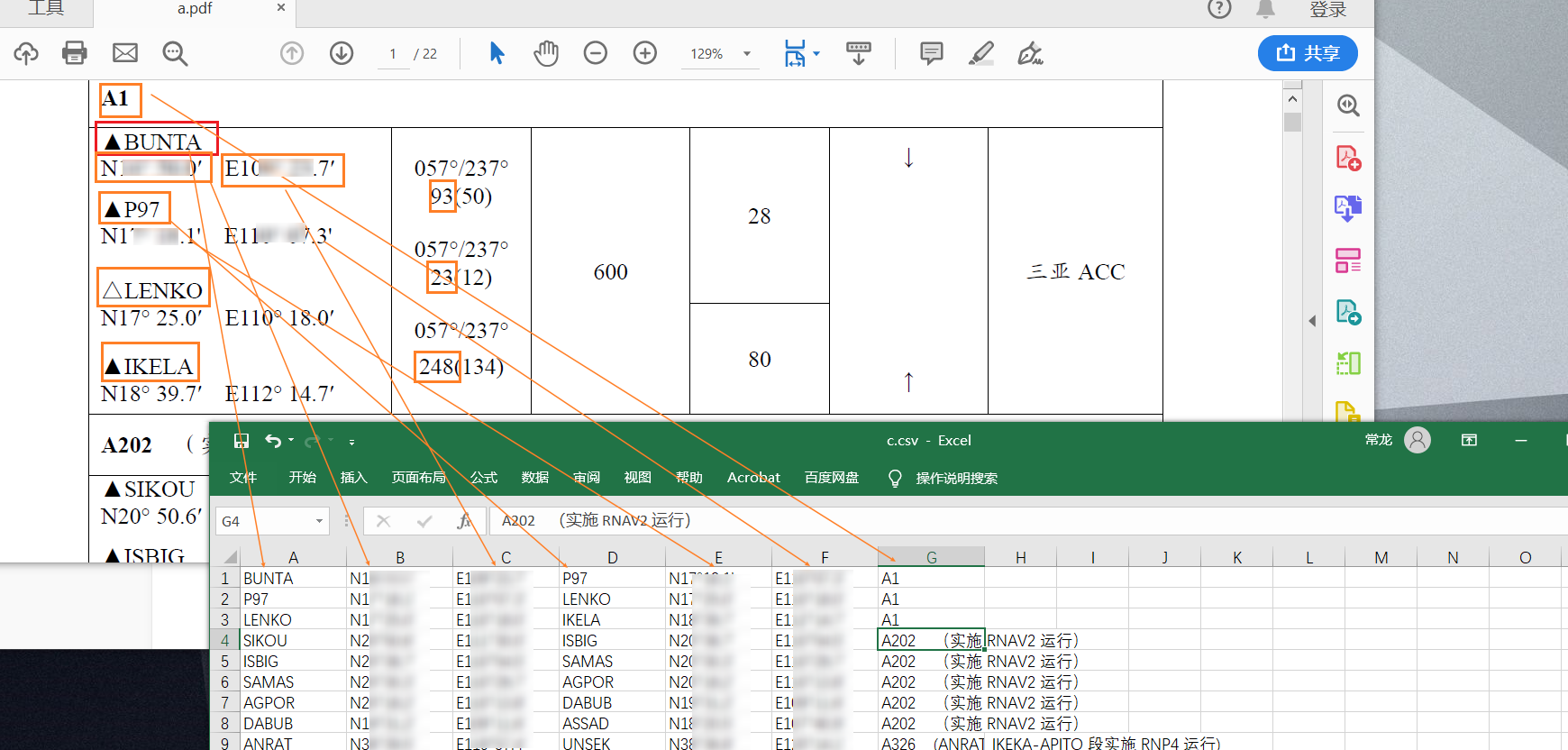
三、代码解析
经过分析pdf文件发现,每个站点都分属某个组(比如A1),所以基本思路就是创建一个数据对象,将每个组得数据都放到对象中,然后实现一个输出方法,重新对数据进行拼接,并保存到文件中。
# 这部分导包是从参考的csdn的博客中直接搞过来的,有一些并没有用到,可以去掉
# 总之,再次感谢博主
# 所以,照着抄吧
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams,LTTextBoxHorizontal
from pdfminer.pdfpage import PDFTextExtractionNotAllowed,PDFPage
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
import os,requests,re, sys
# 创建类每个站点组的类
class StaData():
# 站点组的名称
name = None
# 站点名称,每个组有多个站点,所以用列表保存
sta = []
# 经纬度信息
N = []
E = []
# 距离信息,由于距离信息在pdf解析时,并不能很好的站点信息组织到一起,所以暂时没有用到这个数据
# 后续还需要单独对他进行处理
dis = []
# 保存方法,将每个站点组的数据保存到csv文件中
def toCsv(self, filename="c.csv"):
# 以追加模式进行保存,最终形成一个excel表
with open(filename, "a") as f:
# 拼接字符串,按道理用join方法更好,但是,管他呢
for i in range(len(self.sta) - 1):
s = self.sta[i][1:] \
+ "," \
+ self.N[i] \
+ "," \
+ self.E[i] \
+ "," \
+ self.sta[i+1][1:] \
+ "," \
+ self.N[i+1] \
+ "," \
+ self.E[i+1] \
+ "," \
+ self.name \
+ "\n"
f.write(s)
print(s)
f.close()
# 在这个地方清空列表,保证重新创建下一个站点组时列表是空的
self.sta.clear()
self.N.clear()
self.E.clear()
# 该函数copy自参考博客,其中更改了一下,将该函数改成了生成器
# 这样的话,该函数就会将内容一行一行的返回出来,我们再进行处理
def changePdfToText(filePath):
# 以二进制读模式打开
file = open(filePath, 'rb')
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档对象存储文档结构,提供密码初始化,没有就不用传该参数
doc = PDFDocument(praser, password='')
##检查文件是否允许文本提取
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源,#caching = False不缓存
rsrcmgr = PDFResourceManager(caching = False)
# 创建一个PDF设备对象
laparams = LAParams()
# 创建一个PDF页面聚合对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解析器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
print(PDFPage.get_pages(doc))
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(doc):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
for x in layout:
if hasattr(x, "get_text"):
# 获取文本内容
results = x.get_text()
# 如果文本内容中有换行符,则可以确定是多行内容的文本块
# 那么就需要将内容进行分割,并按行输出
if '\n' in results:
# 且跟文本
results = results.split("\n")
# 遍历并返回文本
for r in results:
yield r
else:
# 如果没有换行,则直接返回
yield results
# 这个函数是新加的,作用呢就是通过上边的类创建对象,并设置对应的值
def createObject():
创建生成器
pdfparse = changePdfToText(filePath="./a.pdf")
# 创建对象
o = StaData()
# 死循环,直到数据处理完成自动退出
while True:
d = None
try:
# 使用next方法依次访问生成器,并获取生成器的数据
d = next(pdfparse)
except:
# 如果获取不到数据了,则直接退出
sys.exit()
# 根据每个数据的特征,进行正则匹配
# 如果A开头的后边有数字的,则是站点组名称
if re.match("A\d{1,4}", d):
# 如果是站点组名,则说明需要处理的数据是下一个组的数据了
# 那么这时就需要将上一个组的数据输出到csv文件中,并清空对应列表
o.toCsv()
# 更改对象中的name名称
o.name = d
# 如果是▲|△开头,则对应的是站点名,将名称添加到站点名称
elif re.match("[▲|△].+",d):
o.sta.append(d)
# 如果是N开头,则是经纬度,这里处理的有点问题,可以直接通过空格对数据进行切分的
# 我先将空格去掉了,然后通过E字母进行切分,后来又加上了E,搞麻烦了
elif d.startswith("N"):
d = d.replace(" ", "")
jw = d.split("E")
jw[1] = "E" + jw[1]
o.N.append(jw[0])
o.E.append(jw[1])
# 如果数据满足数字数字(数字数字)这种形式,则将前边的数字数字取出来
elif re.match("\d{1-4}\(\d{1-4}\)", d):
dis = d.split("(")
o.dis.append(dis[0])
print(o.toCsv)
if __name__ == '__main__':
createObject()
print('ok,解析pdf结束!')

















 4488
4488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









