










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、requests爬虫技术、Echarts可视化、MySQL数据库、时间序列ARIMA预测算法模型
棉花产业体系经济信息网、棉花经济信息数据库的数据
2、项目界面
1、各国棉花面积产量分布分析
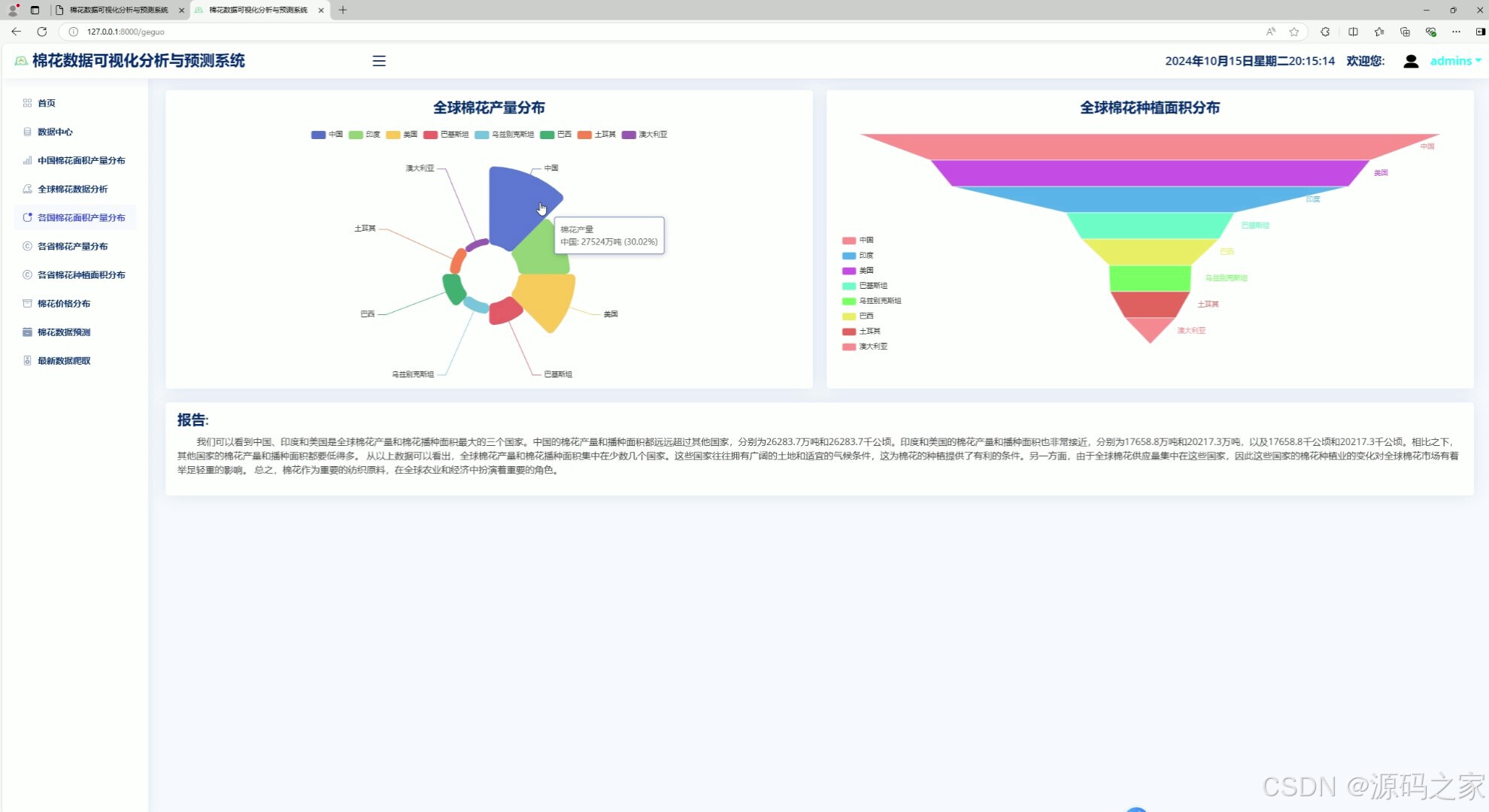
2、面积与产量分布分析

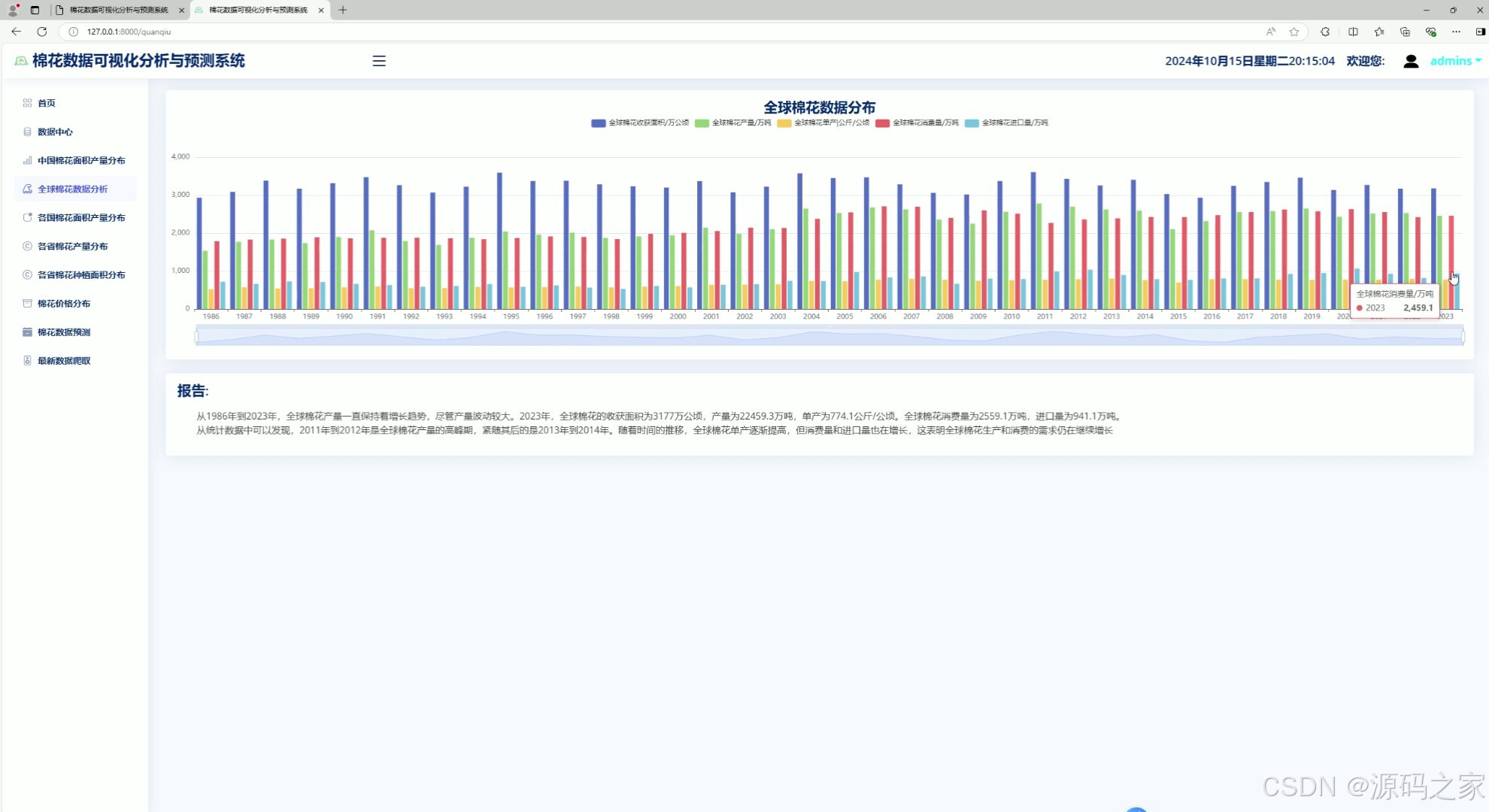
3、各国棉花数据分布分析
4、中国地图—各省份产量分布分析
5、中国地图—各省份种植面积分布分析
6、棉花价格分布分析
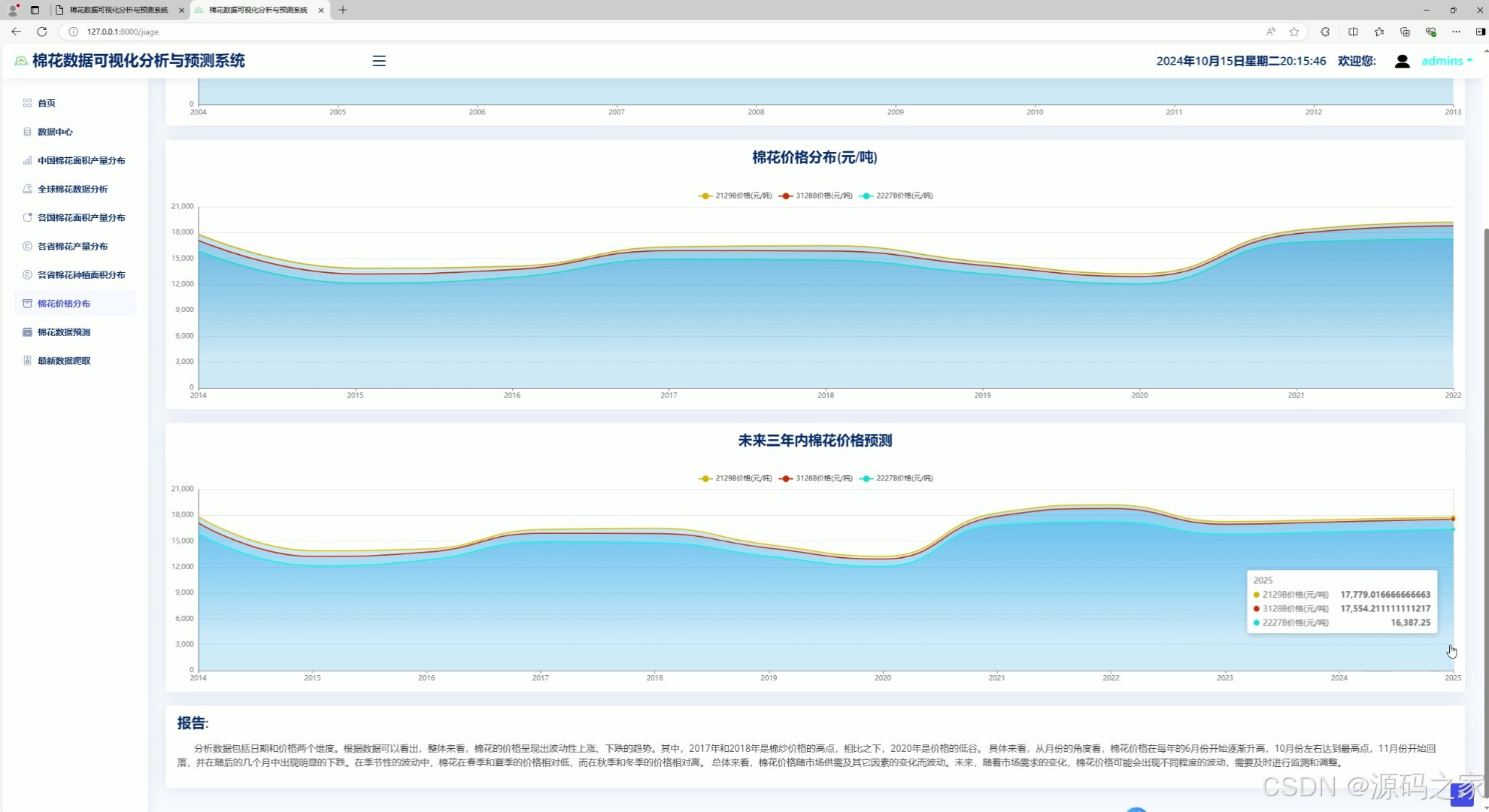
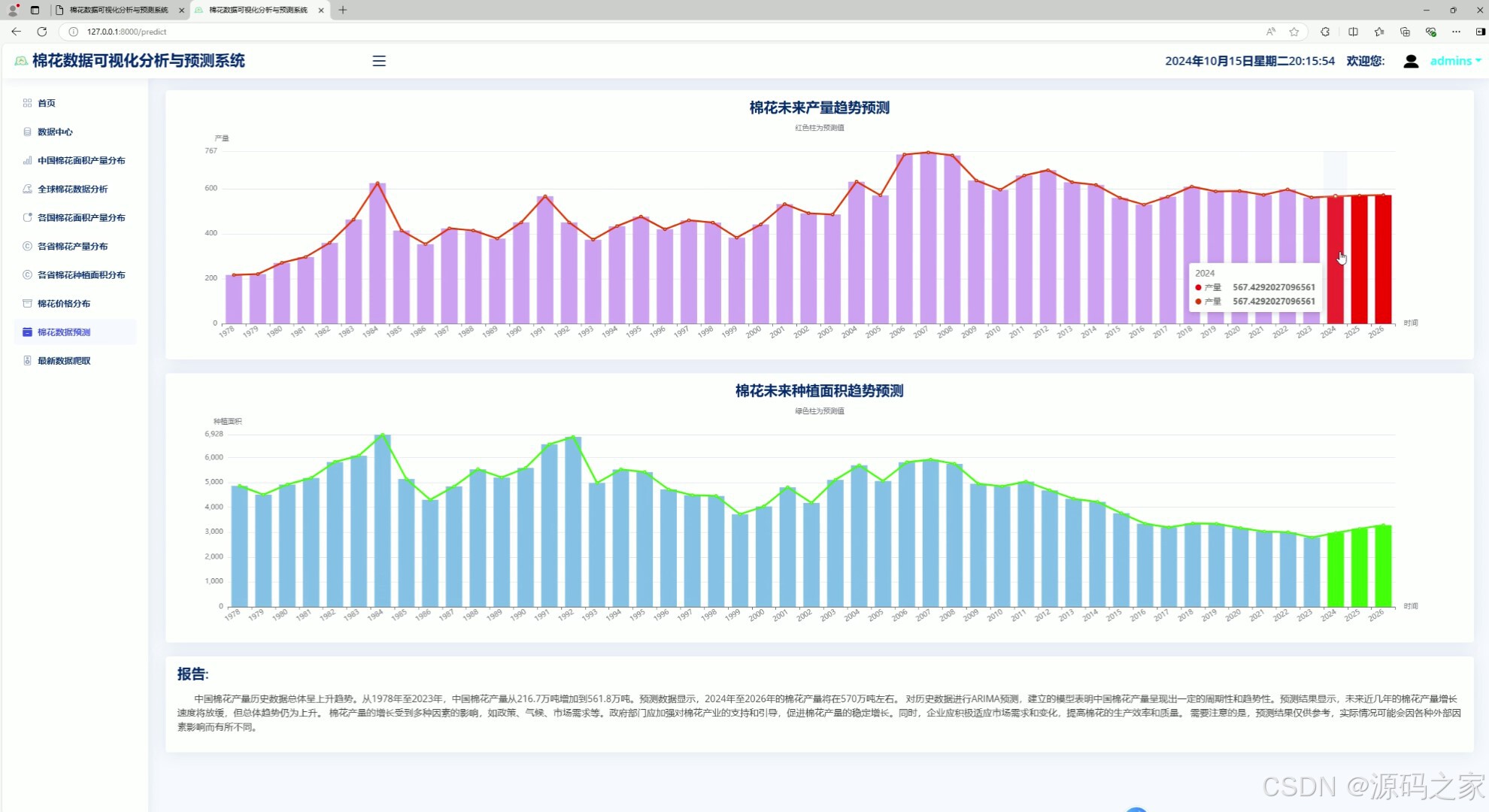
7、棉花预测----产量预测、种植面积预测
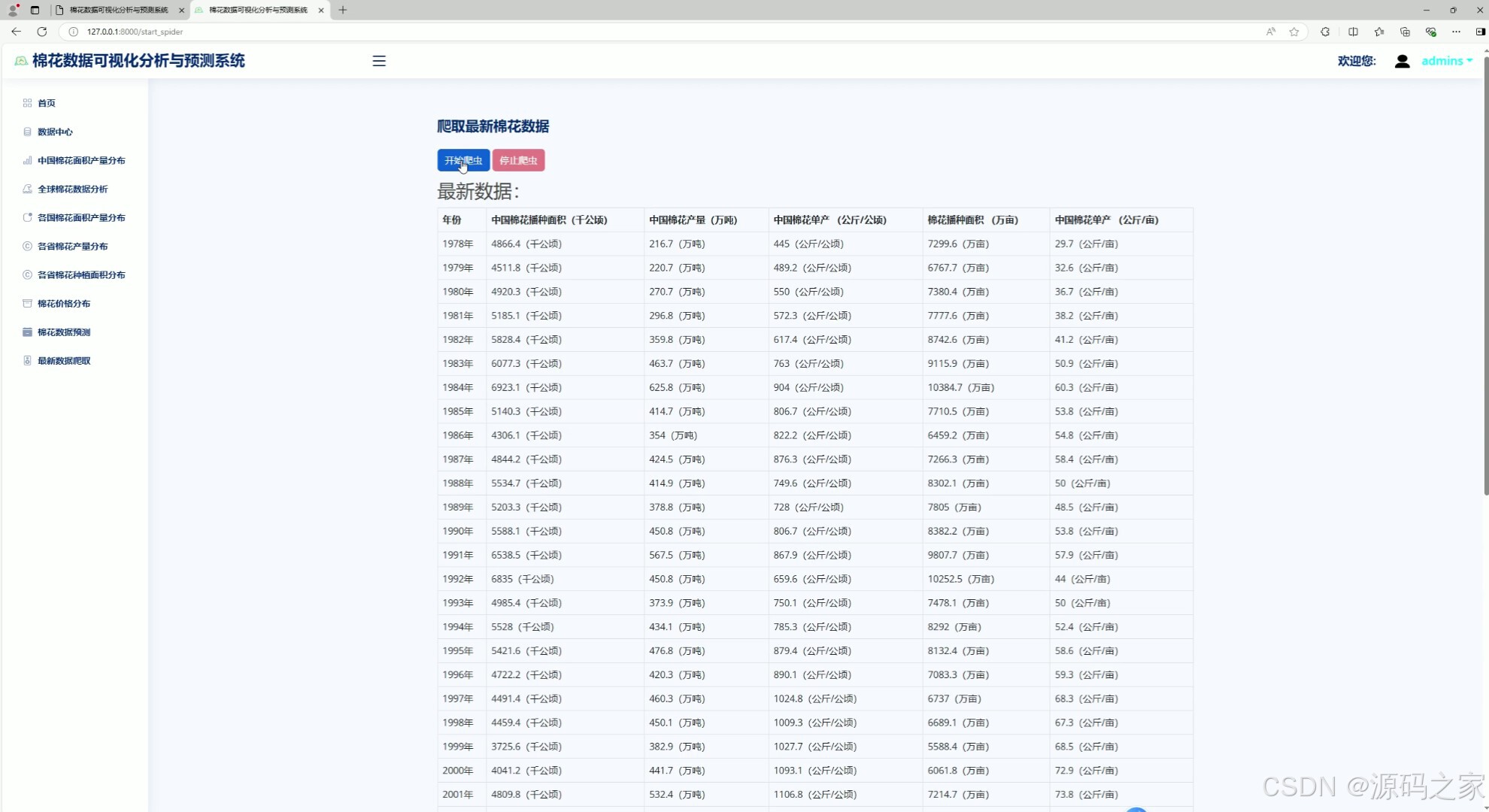
8、数据采集
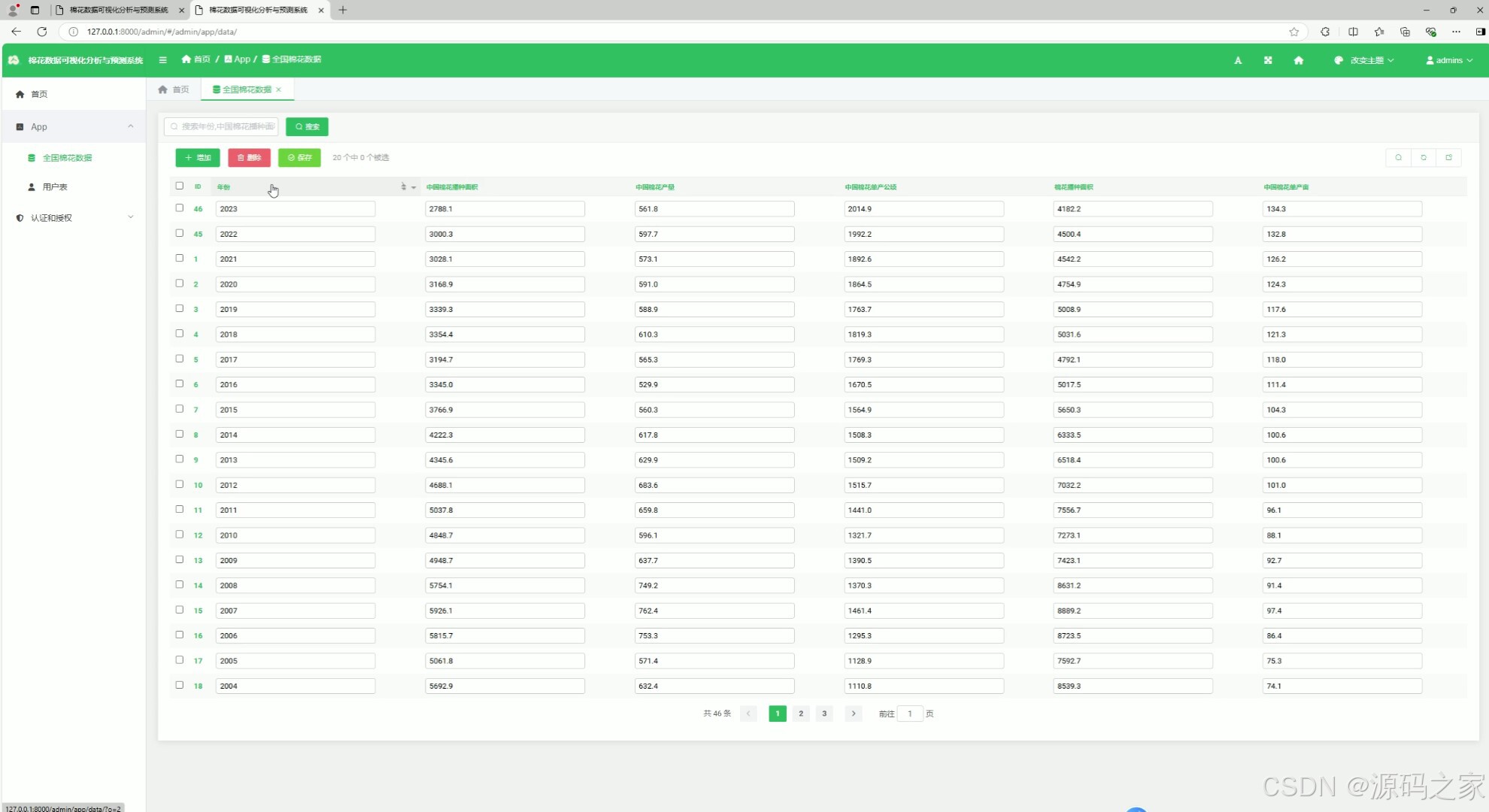
9、后台数据管理
10、注册登录

3、项目说明
摘 要
棉花是我国重要的农作物之一,也是关乎国计民生的重要战略物资,其生产和消费量将直接关系到国家的经济发展和人民的生活水平。作为一个拥有庞大棉花产业的国家,我国棉花生产和消费量的变化将直接影响到数量众多的纺织工人和广大棉农的利益。然而,在棉花产业的相关信息发布方面,我国仍然存在一定的滞后。这不仅对我国棉花产业的及时供求调整构成风险,还影响了棉花市场的稳定运作。因此,及时挖掘棉花种植、生产及市场信息,对于指导棉花产业的有效调整和市场风险的规避具有至关重要的意义。
随着互联网的蓬勃发展,越来越多的人依靠网络来获取所需的信息。然而,对于一些用户来说,传统的通用搜索引擎无法满足他们的查询要求。因此,在这种背景下,网络爬虫技术应运而生,它可以根据用户需求快速挖掘出所需的数据信息。本课题旨在设计并实现一个棉花种植与生产信息爬取与分析系统,该系统使用基于Python语言的网络爬虫技术,编写爬虫程序对国内和国际的棉花种植和产量信息进行爬取,并根据地区、时间段等因素进行统计和分析,以预测近期的棉花种植、产量和价格信息。通过这种方式,可以更好地满足用户的需求,并为棉花产业的发展提供有益的参考和指导。
棉花种植与生产信息爬取与分析系统的设计与实现,为广大棉农提供了一个方便快捷的获取棉花相关信息的渠道,对指导棉花种植、储备轮转和棉花贸易具有重大意义。
关键词:网络爬虫;数据分析;棉花;Python
在实现该系统的过程中,首先,需要确定好研究的问题和目标,这就需要对选题表进行认真研究,明白该系统的需求,需求调研和分析对于系统开发过程来说至关重要,必须了解用户的需求以及他们想要什么功能,在这基础上,我明确了我所设计的棉花种植与生产信息爬取与分析系统必须具有数据爬取、数据分析、数据预测和数据可视化这四大核心功能,还要有一些其他的基本功能,比如用户登录注册、用户信息管理功能和查询功能等。
明确了系统功能后,开始进入了系统开发阶段,首先要明确该系统开发所要采用的技术和开发工具,通过自己查找资料后,决定使用Python语言、爬虫技术、前端Bootstrcp框架、后端Django框架等来开发系统,接下来便是系统的学习这些技术,在系统开发的过程中,也遇到了一些问题,比如已经学习了相关技术,但在实际开发中却运用的不是很好,这些问题是由于我对于相关技术了解的还不够深入而产生的,在系统设计中为了解决这些棘手的问题往往会花费大量的时间,我意识到,就算是自己觉得已经学会的技术也要通过实践来检验其掌握程度。
1. 各国棉花面积产量分布分析
- 功能描述:分析全球主要棉花生产国的种植面积和产量分布情况。
- 特点:
- 使用柱状图或折线图展示各国的棉花种植面积和产量对比。
- 支持按年份筛选数据,以观察不同年份的变化趋势。
- 提供数据导出功能,方便用户进行进一步分析。
2. 面积与产量分布分析
- 功能描述:综合分析棉花种植面积与产量之间的关系。
- 特点:
- 使用散点图或气泡图展示面积与产量的分布关系。
- 提供回归分析功能,帮助用户理解面积与产量的线性关系。
- 支持按国家或地区筛选数据,以聚焦特定区域的分析。
3. 各国棉花数据分布分析
- 功能描述:提供各国棉花产业的综合数据分布分析。
- 特点:
- 展示各国的棉花种植面积、产量、价格等多维度数据。
- 使用地图热力图展示全球棉花产业的地理分布。
- 支持按年份、国家等条件筛选数据。
4. 中国地图——各省份产量分布分析
- 功能描述:分析中国各省份的棉花产量分布情况。
- 特点:
- 使用地图热力图直观展示各省份的产量分布。
- 支持按年份筛选数据,以观察不同年份的变化趋势。
- 提供数据导出功能,方便用户进行进一步分析。
5. 中国地图——各省份种植面积分布分析
- 功能描述:分析中国各省份的棉花种植面积分布情况。
- 特点:
- 使用地图热力图直观展示各省份的种植面积分布。
- 支持按年份筛选数据,以观察不同年份的变化趋势。
- 提供数据导出功能,方便用户进行进一步分析。
6. 棉花价格分布分析
- 功能描述:分析棉花价格的分布情况。
- 特点:
- 使用柱状图或折线图展示棉花价格随时间的变化趋势。
- 支持按国家、地区或时间段筛选数据。
- 提供价格波动分析,帮助用户了解市场价格动态。
7. 棉花预测——产量预测、种植面积预测
- 功能描述:使用时间序列ARIMA模型预测棉花的产量和种植面积。
- 特点:
- 数据采集:通过爬虫技术从棉花产业经济信息网获取历史数据。
- 模型训练:使用ARIMA模型对历史数据进行拟合和训练。
- 预测功能:预测未来几年的棉花产量和种植面积。
- 可视化展示:以折线图形式展示预测结果与历史数据的对比。
8. 数据采集
- 功能描述:通过爬虫技术从棉花产业经济信息网采集数据。
- 特点:
- 使用
requests库进行网页数据爬取。 - 提供数据清洗和预处理功能,确保数据质量。
- 支持定时任务,自动更新数据。
- 使用
9. 后台数据管理
- 功能描述:提供数据的管理功能,包括数据的增删改查。
- 特点:
- 支持管理员对棉花数据进行管理。
- 提供数据导入和导出功能,方便数据备份和更新。
- 支持用户权限管理,确保数据安全。
10. 注册登录
- 功能描述:提供用户注册和登录功能。
- 特点:
- 支持用户通过用户名和密码进行登录。
- 注册时需要填写必要的用户信息,如用户名、密码、邮箱等。
- 提供用户信息管理功能,方便用户修改个人信息。
4、核心代码
def pred(df, col):
# 差分操作
diff_data = df.diff().dropna()
# 建立ARIMA模型并拟合
model = ARIMA(df[col], order=(1, 1, 1))
result = model.fit()
# 预测结果
pred = result.predict(start='2024', end='2026', typ='levels')
# pred = result.predict(start='2022', end='2024', typ='levels')
# 将“年份”转换为一列
df = df[[col]].reset_index()
# 修改列名为“年份”
df.rename(columns={'index': '年份'}, inplace=True)
# 输出结果
print(df)
# 将时间索引转换为一列
s = pred.reset_index()
# 修改列名
s = s.rename(columns={'index': '年份'})
s = s.rename(columns={'predicted_mean': col})
print(s)
# 合并DataFrame和Series
res_df = pd.concat([df, s], axis=0, ignore_index=True, sort=False)
res_df['年份'] = res_df['年份'].dt.strftime('%Y')
return res_df
@login_required
def jiage(request):
query1 = 'select * from 棉花价格04到13'
query2 = 'select * from 棉花价格14到23'
df = query_database(query1)
df = df.sort_values(by='年份', ascending=True)
date = df['年份'].tolist()
col_list = df.columns.tolist()
df1_list = [df[col].values.tolist() for col in col_list]
print(df1_list[1:])
df2 = query_database(query2)
df2 = df2.sort_values(by='年份', ascending=True)
date2 = df2['年份'].tolist()
col_list2 = df2.columns.tolist()
df2_list = [df2[col].values.tolist() for col in col_list2]
print(df2_list[1:])
df2 = df2.sort_values(by='年份', ascending=True)
print(df2)
X_train, y_train = df2[['年份']], df2[['2129B价格(元/吨)', '3128B价格(元/吨)', '2227B价格(元/吨)']]
X_test = pd.DataFrame({'年份': [2023, 2024, 2025]})
models = {}
for col in y_train.columns:
model = LinearRegression().fit(X_train, y_train[col])
models[col] = model
predictions = {}
for col, model in models.items():
predictions[col] = model.predict(X_test)
print(pd.DataFrame(predictions, index=[2023, 2024, 2025]))
pre_df = pd.DataFrame(predictions, index=[2023, 2024, 2025]).reset_index().rename(columns={'index': '年份'})
res_df = pd.concat([df2, pre_df])
print(res_df)
res_date = res_df['年份'].tolist()
res_col = res_df.columns.tolist()
res_list = [res_df[col].values.tolist() for col in res_col]
return render(request, 'jiage.html', locals())
@login_required
def predict(request):
# 读取数据并设置DateTimeIndex
query1 = 'select * from 全国棉花数据'
df = query_database(query1)
df = df.sort_values(by='年份', ascending=True)
df = df.set_index('年份')
df.index = pd.to_datetime(df.index, format='%Y')
res_df = pred(df, '中国棉花产量')
res_df2 = pred(df, '中国棉花播种面积')
# 输出结果
print(res_df)
years = res_df['年份'].tolist()
data = res_df['中国棉花产量'].tolist()
data2 = res_df2['中国棉花播种面积'].tolist()
return render(request, 'predict.html', locals())
@login_required
def spider(request):
return render(request, 'spider.html')
def start_spider(request):
if request.method == 'POST':
response = requests.get('http://www.chinacotton.org/db/DB_010.aspx')
df = pd.read_html(response.text)
df = pd.read_html(response.text)
df = df[1]
df = df.iloc[2:-2] # 删除前两行
df.columns = df.iloc[0]
df = df[1:] # 删除第一行
response = requests.get('http://www.chinacotton.org/db/DB_010.aspx')
df = pd.read_html(response.text)
df = df[1]
df = df.iloc[2:-2] # 删除前两行
df.columns = df.iloc[0]
df = df[1:] # 删除第一行
df = df.sort_values(by='年份', ascending=True)
data = df.values.tolist()
for d in data:
time.sleep(0.1)
print({
'年份': d[0],
'中国棉花播种面积(千公顷)': d[1],
'中国棉花产量 (万吨)': d[2],
'中国棉花单产 (公斤/公顷)': d[3],
'棉花播种面积 (万亩)': d[4],
'中国棉花单产 (公斤/亩)': d[5],
})
return render(request, 'spider.html', locals())
def stop_spider(request):
if request.method == 'POST':
return JsonResponse({'status': 'success'})
else:
# 返回错误响应
return HttpResponseBadRequest('Invalid request method')
5、项目获取
biyesheji0005 或 biyesheji0001 (绿色聊天软件)
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









