









🍅大家好,今天给大家分享一个Python项目,感兴趣的可以先收藏起来,点赞、关注不迷路!🍅
大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、Flask框架、MySQL数据库、requests网络爬虫技术、scikit-learn机器学习、snownlp情感分析、词云、舆情分析
1.开发工具
本项目主要采用 PyCharm 开放平台利用 Python 语言来实现的。PyCharm 是一种PythonIDE,带有一整套可以帮助用户在使用 Python 语言开发时提高其效率的工具。
2.数据获取
为了获取微博信息数据做后续的任务分析,需要使用爬虫技术,爬取微博网的微博信息数据,针对微博网的反爬机制,需要使用反爬手段绕过反爬机制,确保获取数据的准确性和完整性。本次爬虫设计的目标是获取微博信息,数据获取模块的实现是通过requests网络爬虫技术采集微博网上微博信息。本次爬虫的运行基本流程如图 1 所示。
2、项目界面
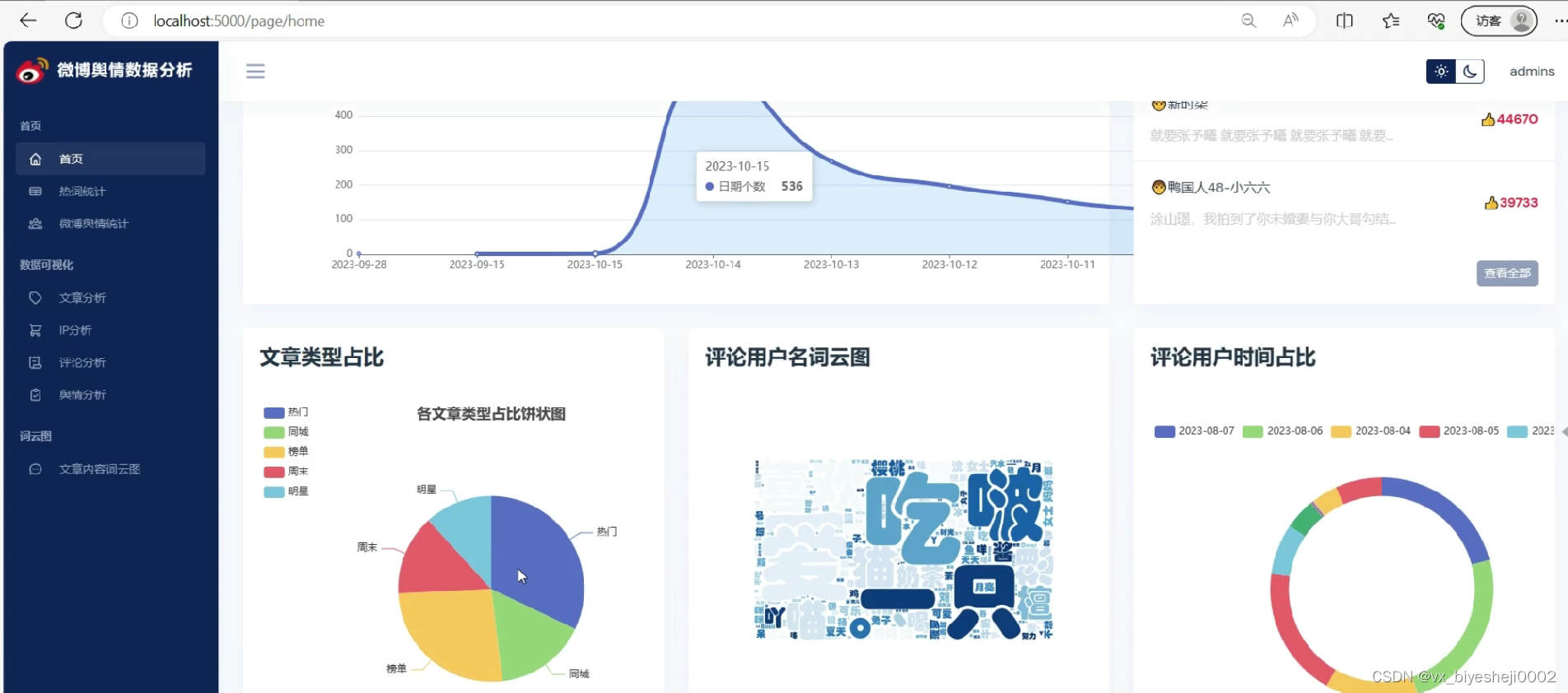
(1)系统首页-数据概况
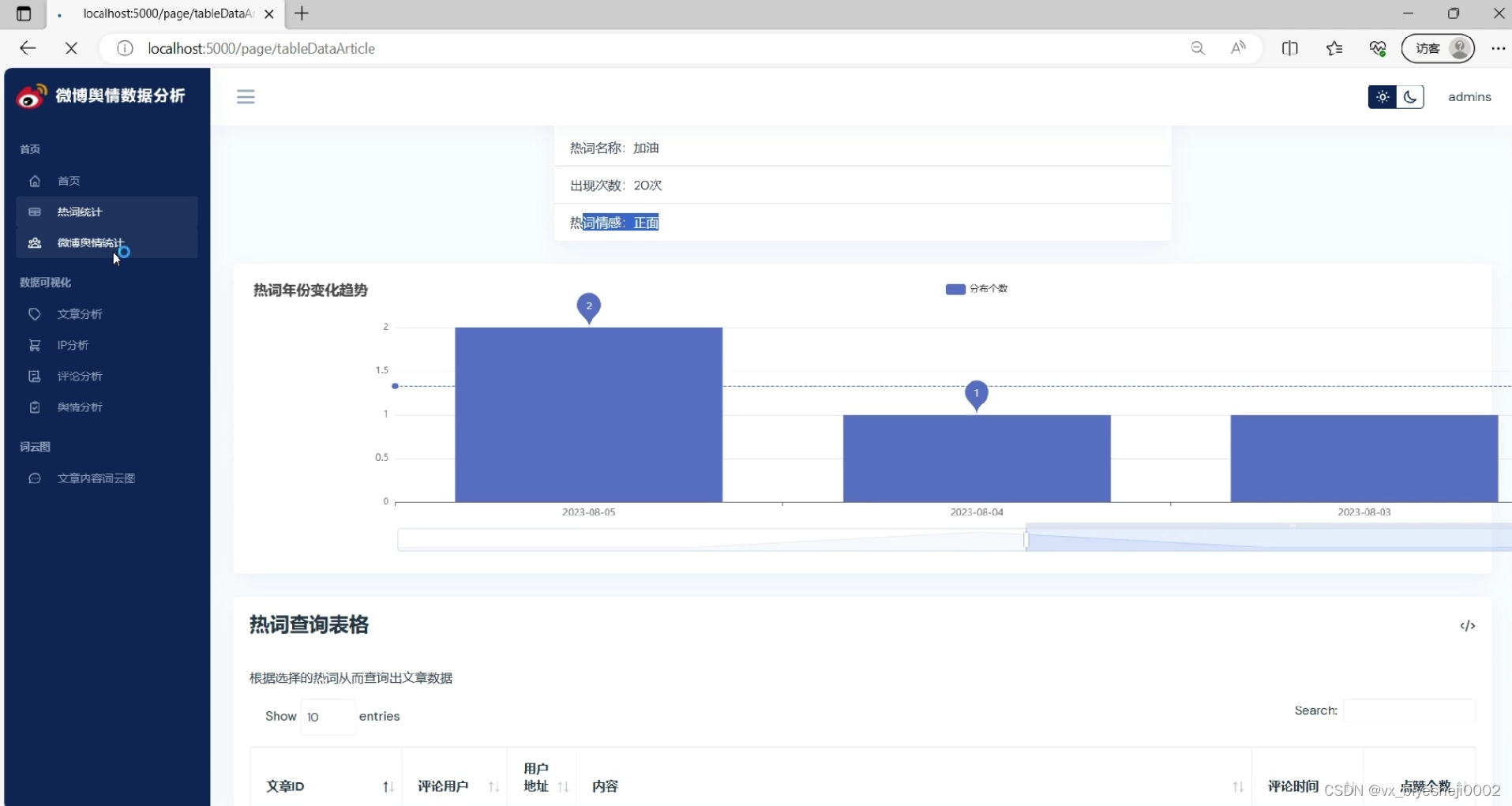
(2)微博舆情统计分析
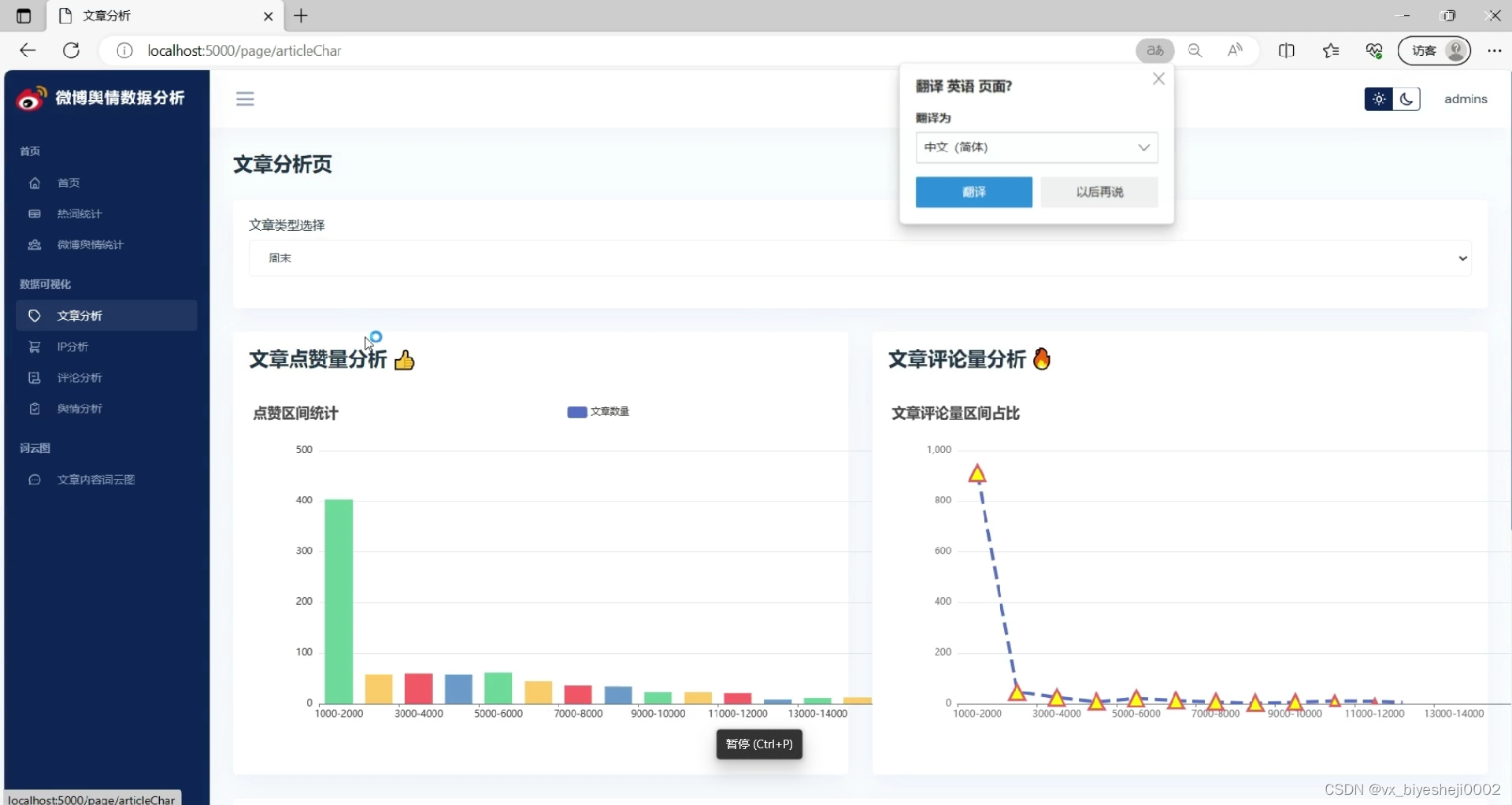
(3)舆情文章分析
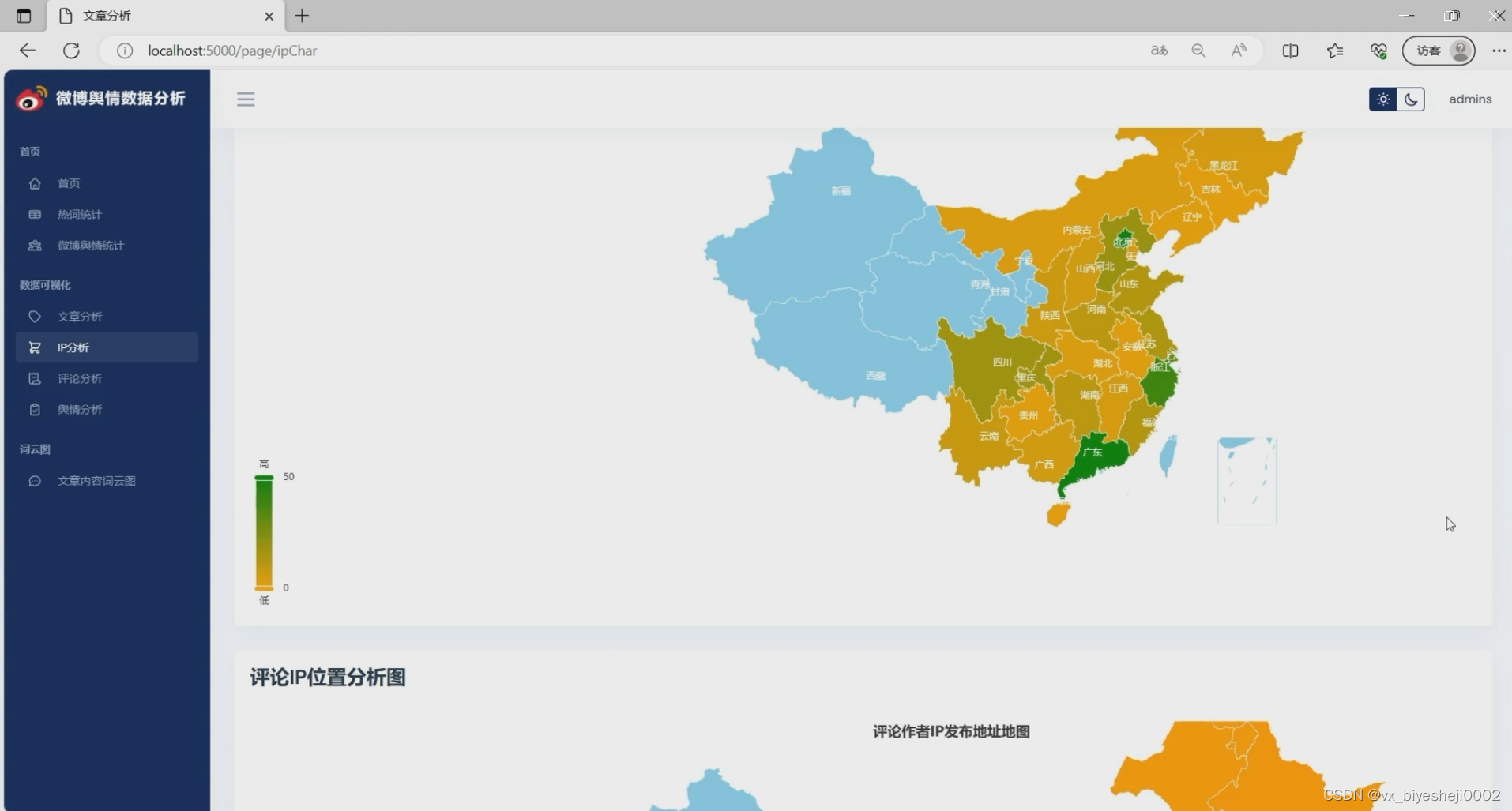
(4)IP地址分析
(5)舆情数据
(6)舆情评论分析
(7)舆情分析
(8)文章内容词云分析
3、项目说明
1.开发工具
本项目主要采用 PyCharm 开放平台利用 Python 语言来实现的。PyCharm 是一种PythonIDE,带有一整套可以帮助用户在使用 Python 语言开发时提高其效率的工具。
2.数据获取
为了获取微博信息数据做后续的任务分析,需要使用爬虫技术,爬取微博网的微博信息数据,针对微博网的反爬机制,需要使用反爬手段绕过反爬机制,确保获取数据的准确性和完整性。本次爬虫设计的目标是获取微博信息,数据获取模块的实现是通过requests网络爬虫技术采集微博网上微博信息。本次爬虫的运行基本流程如图 1 所示。
本地保存数据应对后续数据分析,可以使用MySQL和csv对数据进行持久化保存,对于MySQL可以通过Pymysql结合Sqlalchemy或者Pandas进行数据插入。因此本次实验选用的是 MySQL 数据库对采集的数据进行数据存储。
3、微博热词统计:热点年份变化趋势、热词情感分析、热词频率分析
首先,热点年份变化趋势是指在不同年份中,微博上的热点话题发展的趋势和变化。通过统计不同年份中的热词,我们可以了解到社会关注焦点的转移和变化趋势。例如,某个年份的热词可能主要集中在娱乐明星或电视剧上,而另一个年份可能更多关注社会事件或政治话题。
其次,热词情感分析是通过对热词相关微博内容的情感倾向进行分析。通过对微博用户的评论、转发和点赞等行为进行监测和分析,可以了解到用户对热词所表达的情绪态度。例如,某个热词在微博上的情感分析结果可能显示大多数用户对该话题持正面态度,少数用户持负面态度。这样的分析有助于我们了解社会舆论对于热点话题的态度和倾向。
最后,热词频率分析是指对热词在微博上出现的频率进行统计和分析。通过统计不同热词在微博平台上的出现次数,可以了解到不同话题的受关注程度和热度。例如,某个热词在一段时间内频繁出现,说明这个话题在社会上引起了广泛关注。
4、微博文章分析:文章类型占比分析、文章评论量分析、文章转发量分析、文章内容词云分析、文章基本信息统计分析
文章评论量分析:评论量是衡量文章受关注程度的重要指标之一。通过统计文章的评论数量,可以了解用户对文章的关注程度和参与度。这可以帮助我们判断文章的受欢迎程度和影响力。
文章转发量分析:转发量是衡量文章传播范围和影响力的指标之一。通过统计文章的转发数量,可以了解用户对文章内容的认同和推荐程度。这有助于评估文章的传播效果和影响力。
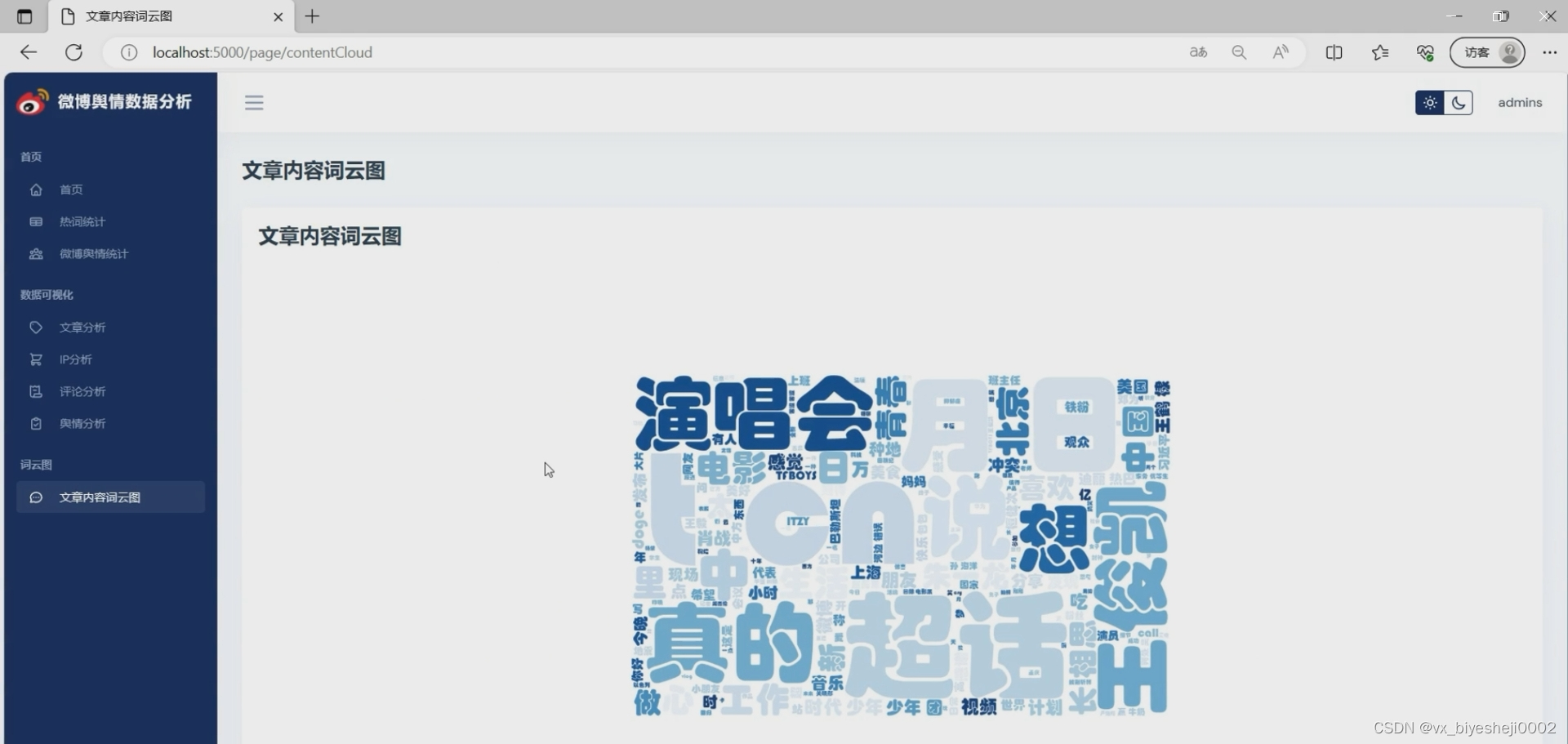
文章内容词云分析:文章内容词云是通过对文章中出现频率较高的词语进行可视化展示,以呈现文章的关键主题和热点话题。通过词云分析,可以直观地了解文章的主要内容和关注点。
文章基本信息统计分析:文章基本信息统计分析包括统计文章的发布时间、作者、阅读量等关键信息。这些统计数据可以帮助我们了解文章的发布趋势、作者影响力以及受众规模等信息。
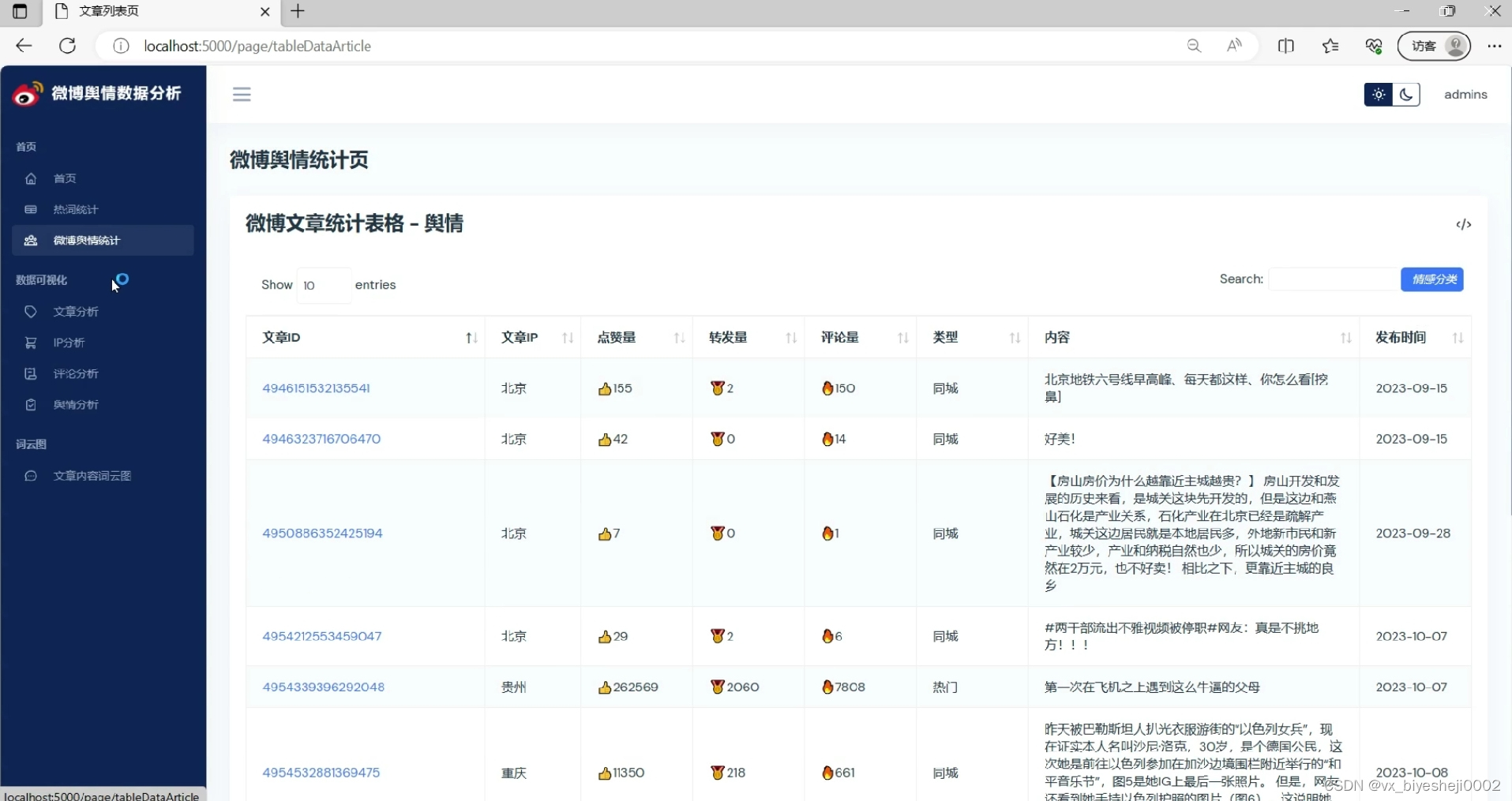
5、微博评论分析:评论用户性别占比分析、用户评论词云图分析、评论点赞分析
首先,对于微博评论的用户性别占比分析,通过统计和分析这些信息,我们可以了解在一定的评论样本中,男性和女性用户的数量占比情况。这可以为我们提供有关该话题或事件下不同性别用户参与讨论的情况,有助于了解不同性别用户的观点和态度。
其次,用户评论词云图分析可以帮助我们了解评论中出现频率较高的关键词。我们可以通过文本处理技术,对评论内容进行分词并统计词频,然后将高频词汇绘制成词云图。这样,我们就能够直观地看到哪些词汇在评论中被提及得较多,从而推测用户对该话题或事件的关注点和情感倾向。
最后,评论点赞分析可以帮助我们了解哪些评论在用户中较受欢迎或者认同。通过统计每条评论的点赞数,我们可以排名评论的受欢迎程度,并分析受欢迎的评论内容特点。这有助于我们了解用户对于该话题或事件的主要认同观点,以及哪些评论具有较高的影响力。
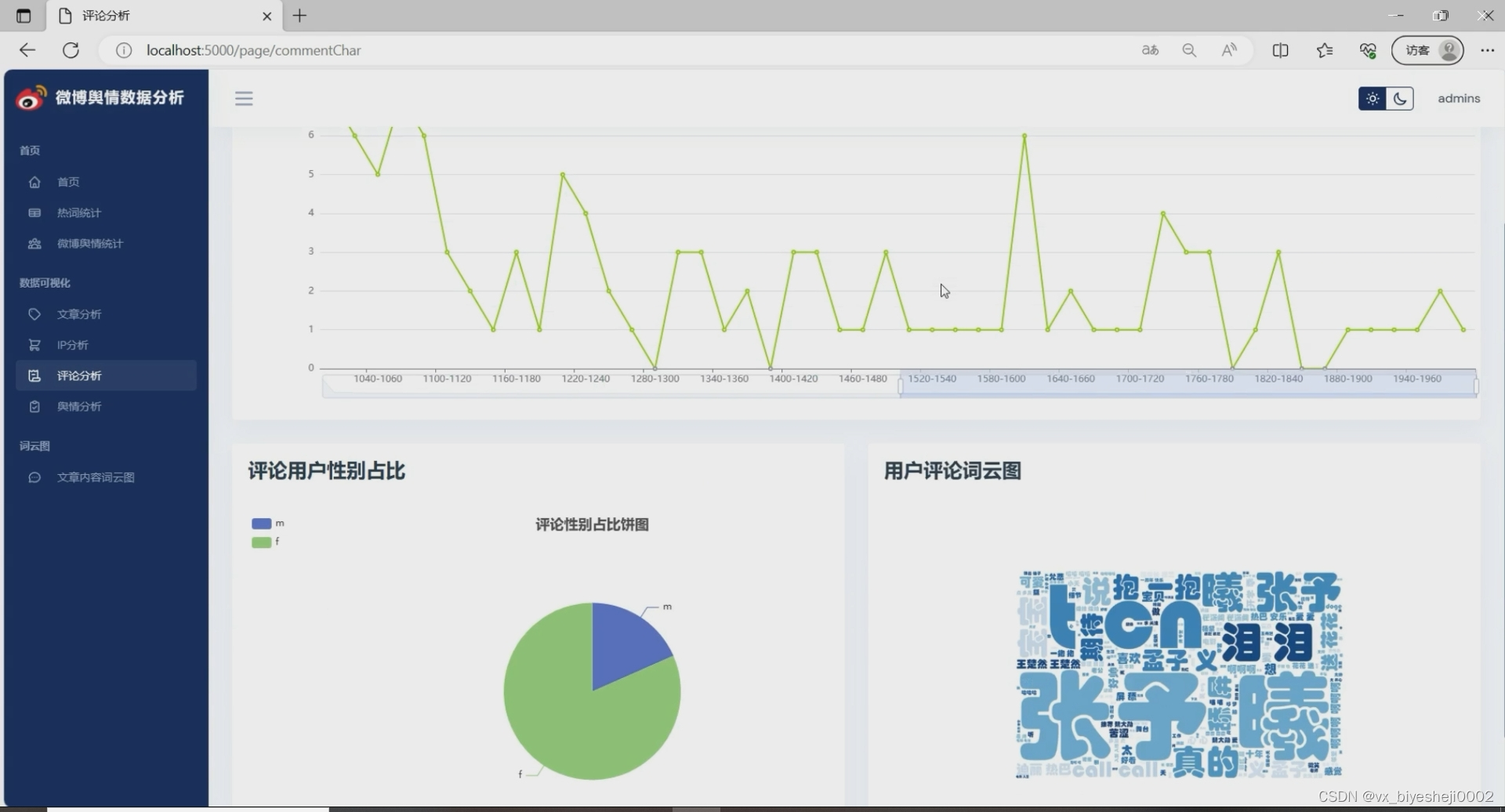
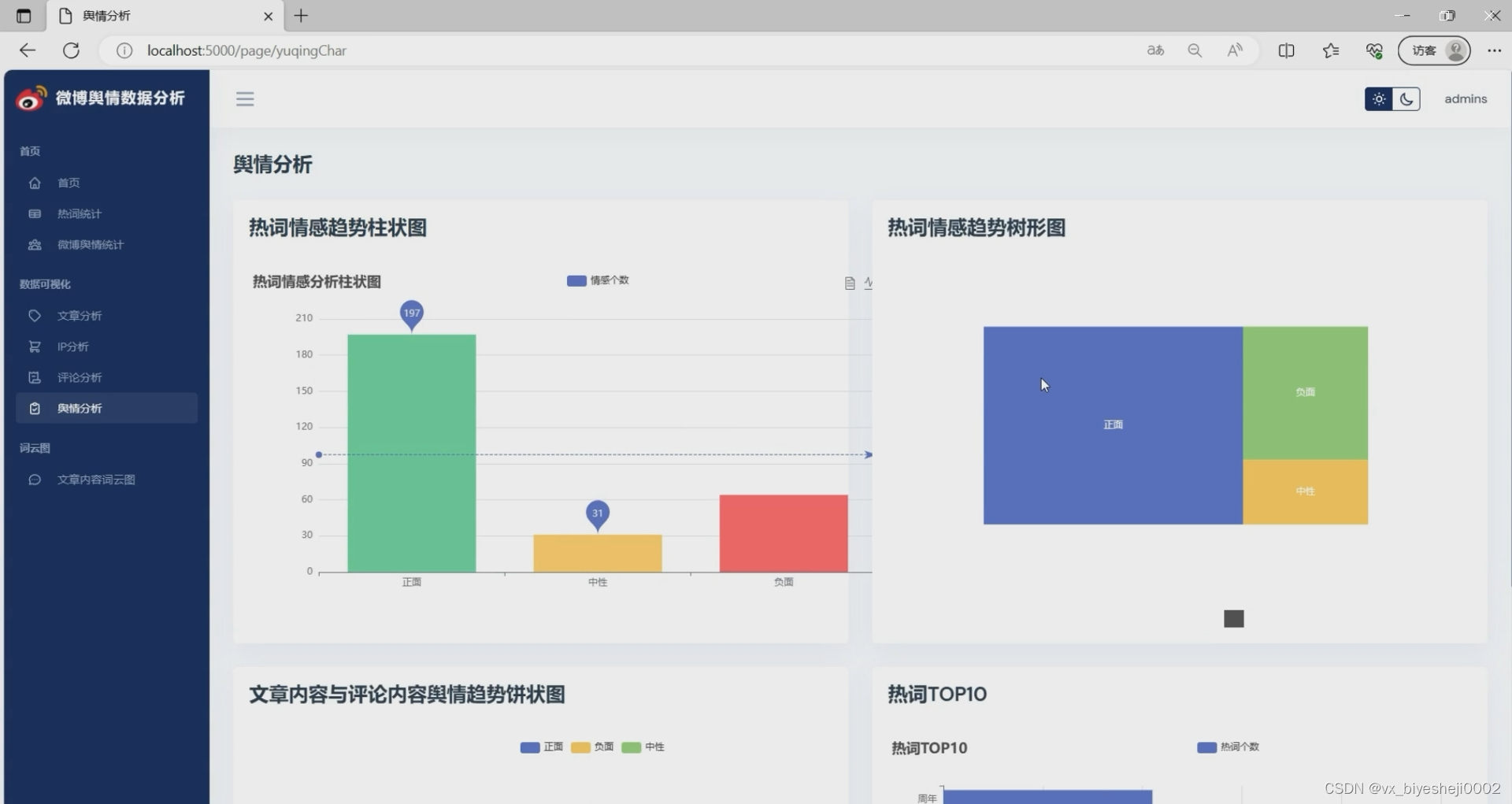
6、微博舆情分析:热词情感趋势、文章内容与评论内容舆情趋势分析
微博热词情感趋势是指根据微博用户在某一段时间内热议的关键词或话题的相关内容进行情感分析,从而了解用户对该热词的情感态度变化趋势。情感趋势分析可以帮助我们更好地了解用户的喜好、态度以及对某一事件或话题的关注程度。
文章内容与评论内容舆情趋势分析是指通过对网络上用户发布的文章内容和评论内容进行分析,了解用户对某一事件、产品或话题的舆情倾向。舆情趋势分析可以帮助我们了解用户对某一事件的态度、关注度以及舆论走向,从而有效地进行舆情管理和营销策划。
4、核心代码
from utils import getPublicData
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image # 图片处理
import numpy as np
from snownlp import SnowNLP
def getTypeList():
typeList = list(set([x[8] for x in getPublicData.getAllData()]))
return typeList
def getArticleCharOneData(defaultType):
articleList = getPublicData.getAllData()
xData = []
rangeNum = 1000
for item in range(1,15):
xData.append(str(rangeNum * item)+ '-' + str(rangeNum*(item+1)))
yData = [0 for x in range(len(xData))]
for article in articleList:
if article[8] != defaultType:
for item in range(14):
if int(article[1]) < rangeNum*(item+2):
yData[item] += 1
break
return xData,yData
def getArticleCharTwoData(defaultType):
articleList = getPublicData.getAllData()
xData = []
rangeNum = 1000
for item in range(1,15):
xData.append(str(rangeNum * item)+ '-' + str(rangeNum*(item+1)))
yData = [0 for x in range(len(xData))]
for article in articleList:
if article[8] != defaultType:
for item in range(14):
if int(article[2]) < rangeNum*(item+2):
yData[item] += 1
break
return xData,yData
def getArticleCharThreeData(defaultType):
articleList = getPublicData.getAllData()
xData = []
rangeNum = 50
for item in range(1, 30):
xData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))
yData = [0 for x in range(len(xData))]
for article in articleList:
if article[8] != defaultType:
for item in range(29):
if int(article[2]) < rangeNum * (item + 2):
yData[item] += 1
break
return xData, yData
def getGeoCharDataTwo():
cityList = getPublicData.cityList
commentList = getPublicData.getAllCommentsData()
cityDic = {}
for comment in commentList:
if comment[3] == '无': continue
for j in cityList:
if j['province'].find(comment[3]) != -1:
if cityDic.get(j['province'], -1) == -1:
cityDic[j['province']] = 1
else:
cityDic[j['province']] += 1
cityDicList = []
for key, value in cityDic.items():
cityDicList.append({
'name': key,
'value': value
})
return cityDicList
def getGeoCharDataOne():
cityList = getPublicData.cityList
articleList = getPublicData.getAllData()
cityDic = {}
for article in articleList:
if article[4] == '无':continue
for j in cityList:
if j['province'].find(article[4]) != -1:
if cityDic.get(j['province'],-1) == -1:
cityDic[j['province']] = 1
else:
cityDic[j['province']] += 1
cityDicList = []
for key, value in cityDic.items():
cityDicList.append({
'name': key,
'value': value
})
return cityDicList
def getCommetCharDataOne():
commentList = getPublicData.getAllCommentsData()
xData = []
rangeNum = 20
for item in range(1, 100):
xData.append(str(rangeNum * item) + '-' + str(rangeNum * (item + 1)))
yData = [0 for x in range(len(xData))]
for comment in commentList:
for item in range(99):
if int(comment[2]) < rangeNum * (item + 2):
yData[item] += 1
break
return xData, yData
def getCommetCharDataTwo():
commentList = getPublicData.getAllCommentsData()
genderDic = {}
for i in commentList:
if genderDic.get(i[6],-1) == -1:
genderDic[i[6]] = 1
else:
genderDic[i[6]] += 1
resultData = [{
'name':x[0],
'value':x[1]
} for x in genderDic.items()]
return resultData
def stopwordslist():
stopwords = [line.strip() for line in open('./model/stopWords.txt',encoding='UTF-8').readlines()]
return stopwords
def getContentCloud():
text = ''
stopwords = stopwordslist()
articleList = getPublicData.getAllData()
for article in articleList:
text += article[5]
cut = jieba.cut(text)
newCut = []
for word in cut:
if word not in stopwords: newCut.append(word)
string = ' '.join(newCut)
img = Image.open('./static/content.jpg') # 打开遮罩图片
img_arr = np.array(img) # 将图片转化为列表
wc = WordCloud(
width=1000, height=600,
background_color='white',
colormap='Blues',
font_path='STHUPO.TTF',
mask=img_arr,
)
wc.generate_from_text(string)
# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
# 显示生成的词语图片
# plt.show()
# 输入词语图片到文件
plt.savefig('./static/contentCloud.jpg', dpi=500)
def getCommentContentCloud():
text = ''
stopwords = stopwordslist()
commentsList = getPublicData.getAllCommentsData()
for comment in commentsList:
text += comment[4]
cut = jieba.cut(text)
newCut = []
for word in cut:
if word not in stopwords:newCut.append(word)
string = ' '.join(newCut)
img = Image.open('./static/comment.jpg') # 打开遮罩图片
img_arr = np.array(img) # 将图片转化为列表
wc = WordCloud(
width=1000, height=600,
background_color='white',
colormap='Blues',
font_path='STHUPO.TTF',
mask=img_arr,
)
wc.generate_from_text(string)
# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
# 显示生成的词语图片
# plt.show()
# 输入词语图片到文件
plt.savefig('./static/commentCloud.jpg', dpi=500)
def getYuQingCharDataOne():
hotWordList = getPublicData.getAllCiPingTotal()
xData = ['正面', '中性', '负面']
yData = [0,0,0]
for hotWord in hotWordList:
emotionValue = SnowNLP(hotWord[0]).sentiments
if emotionValue > 0.5:
yData[0] +=1
elif emotionValue == 0.5:
yData[1] += 1
elif emotionValue < 0.5:
yData[2] += 1
bieData = [{
'name': '正面',
'value': yData[0]
}, {
'name': '中性',
'value': yData[1]
}, {
'name': '负面',
'value': yData[2]
}]
return xData,yData,bieData
def getYuQingCharDataTwo():
bieData1 = [{
'name':'正面',
'value':0
},{
'name':'中性',
'value':0
},{
'name':'负面',
'value':0
}]
bieData2 = [{
'name': '正面',
'value': 0
}, {
'name': '中性',
'value': 0
}, {
'name': '负面',
'value': 0
}]
commentList = getPublicData.getAllCommentsData()
articleList = getPublicData.getAllData()
for comment in commentList:
emotionValue = SnowNLP(comment[4]).sentiments
if emotionValue > 0.5:
bieData1[0]['value'] += 1
elif emotionValue == 0.5:
bieData1[1]['value'] += 1
elif emotionValue < 0.5:
bieData1[2]['value'] += 1
for article in articleList:
emotionValue = SnowNLP(article[5]).sentiments
if emotionValue > 0.5:
bieData2[0]['value'] += 1
elif emotionValue == 0.5:
bieData2[1]['value'] += 1
elif emotionValue < 0.5:
bieData2[2]['value'] += 1
return bieData1,bieData2
def getYuQingCharDataThree():
hotWordList = getPublicData.getAllCiPingTotal()
return [x[0] for x in hotWordList],[int(x[1]) for x in hotWordList]
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻















 1256
1256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









