







这里以es多节点集群部署来做说明。单节点与之类似。基于es 7.1版本。
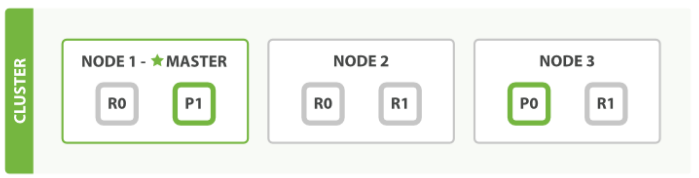
集群模式下,对于document的检索称为 Distribute document search。在简单的三节点集群中,假设一个index有两个primary shard,每个shard有2个replicate。如下图:其中,P0,P1为两个primary shard,NODE1和NODE2上的R0为P0的两个replicate,NODE2和NODE3上的R1为P1的两个replicate。P0+R0+R0为一个replicate group,P1+R1+R1为一个replicate group。按照es的存储原则,一个节点上至多存储同一个replicate group中的一个shard。
我们知道,es的底层是lucene,而lucene是一个全文搜索引擎,显而易见的,es很重要的功能就是全文检索,附带数据存储功能。当集群接收到来自客户端的文档检索请求,es除了要返回符合条件的内容,还要对返回的内容进行打分,按照搜索引擎的工作形式,将打分从高(也既从es看来最符合用户要求的数据)到低的顺序返回给客户端。es将这两项工作分成了两步来完成:query+fetch。
首先,集群中的某个节点,接收到来自客户端的request,request可能包含了某个条件,并且包含了分页参数from和size,假设是这样的:
GET ac_blog/_search?preference=123456789
{
"query": {
"bool": {
"must": [
{"match": {
"title": "entry"
}}
]
}
},
"from":100,
"size":10
}要从ac_blog这个index获取title(text类型)包含entry的文档,获取排序100--109的document。这里留意一下,es里,from的下标是从0开始的。
要完成这个request,在query的步骤里,es将请求分发到各个replicate group中的一个shard里,至于是哪个shard,es是采用round-robin的方式选择shard的(在7.1版本,还会额外考虑allocation awareness 和adaptive replica selection),确保各个shard的负载均衡。shard在自己内部根据条件检索到对应的文档,并按照_score由高到低排序,获取从0到109共110个文档的_id以及_score返回给node3。为哈是110个而不是10个,这个后面解释。如下图所示:

1,request到达node3,此时node3作为coordinator;
2,node3分发请求到node1的P1分片和NODE2的R0分片;
3,P1和R0在分片内部检索数据,并返回id与score给node3.
此时,NODE3拿到了220个文档,然后从这220个文档里,按照score从高到低排序,取100-109排序的文档,其余丢弃。然后根据文档id构造_mget请求,到对应的分片获取document的完整内容,并返回给客户端。这是fetch阶段。如下图所示:

1,node3将选中的文档id发回对应分片;
2,分片返回完整document内容;
3,node3将文档内容返回给客户端.
到此,整个检索过程就结束了。但是其中有一些细节需要详细描述。
首先,query阶段,分片为何返回110个文档,而不是10个文档给coordinator?这是因为分片是在各自的内部进行排序的,这只是局部的顺序,并不是整个index的全局排序,因此需要将前110个文档返回给coordinator,由coordinator进行全局排序,确定最终的结果。这也是整个检索过程中较为耗时的地方。假如请求的是from=100000,size=10呢?假如有10个replicate group呢?资源耗费巨大。
其次就是排序结果的Bouncing result问题,如果两个文档score相同,那么根据es的round-robin方法,第一次请求可能是从shardA获取,第二次可能从shardB获取,两次获取的文档排序顺序可能不同。按照官方文档的描述,可以通过设置preference来使两次请求均从相同shard获取数据来避免Bouncing result问题。那么,通过这个问题,我们可以猜测下,在score相同的情况下,es可能是通过文档的物理存储顺序来决定排序先后的。因为在写入文档时,数据是从primary shard并行写入到各个shard copy,在请求并发的情况下,各个shard copy写入文档的顺序可能不同;也可能在merge segment的时候,改变了文档的物理存储顺序。更进一步,如果在score相同的情况下,使用文档id进行排序,应该能避免这个问题。好,这个是解决分片内排序的问题,个人私想,如果在分片间score相同,应如何解决?根据分片id吗?
注意上面的qsl,在url后面后缀了preference=123456789,这个就是用来确保两次分页查询获得相同的文档顺序。es可能在这个string上进行了hash。在7.1版本上,preference还有其他取值:
_only_local:操作仅仅在本地节点的shard上进行
_local:操作优先在本地节点的shard上进行,如果不可用,则在其他shard上进行
_prefer_nodes:abc,xyz:操作优先在指定的节点id上的shard进行,如果指定的多个节点均满足的话,随机选择节点。
_shards:2,3:操作在指定的分片id上进行,可以与其他参数结合使用,但_shards必须在第一个指定:_shards:2,3|_local
_only_nodes:abc*,x*yz,...:操作仅在指定的节点id上的shard进行,如果指定的多个节点均满足的话,随机选择节点
Custom (string) value:任意string。尽量两次request在相同的的shard上进行,如果满足不了的话,可能在其他shard上进行
以上选项,只有_local能确保仅在本地shard执行,其他选项均为best effort型,不保证一定按照要求进行。
qsl中同样可以设置timeout参数,需要注意的是,这里的timeout仅指单个shard检索数据并返会到coordinator的过程。如果shard处理时间超过timeout指定值,则会返回部分结果或者空列表到coordinator。此时,客户端收到的响应码是成功的,但是在响应结果中可以查看time_out确定是否有shard有超时的情况。timeout是best-effort的,因此可能会有timeout后仍未返回的情况发生,官方文档解释如下:
It’s important to know that the timeout is still a best-effort operation; it’s possible for the query to surpass the allotted timeout. There are two reasons for this behavior:
- Timeout checks are performed on a per-document basis. However, some query types have a significant amount of work that must be performed before documents are evaluated. This "setup" phase does not consult the timeout, and so very long setup times can cause the overall latency to shoot past the timeout.
- Because the time is once per document, a very long query can execute on a single document and it won’t timeout until the next document is evaluated. This also means poorly written scripts (e.g. ones with infinite loops) will be allowed to execute forever.
如果个别shard运行较慢,则会拖慢整个请求响应。
其他可指定的参数包括routing(可参考这里elasticsearch文档_routine字段的使用)、search_type。















 2503
2503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









