






本文主要讲解ES如何从文档中提取内容(word、pdf、txt、excel等文件类型),实现快速检索文档内容实现。
特别说明一下,为什么用7.10.0版本,因为在项目中除了精确匹配的要求,也会有模糊查询(关键字是wildcard )的场景。wildcard 这个只有 7.9 版本之后才支持 所以我推荐你使用 7.10.0。
elasticsearch,el, kibana,版本需要一致,比如elasticsearch版本是7.10.0,那么el和kibana的版本也需要是7.10.0,elasticsearch-head-master无所谓,尽量别用太低的版本(后期补充:我发现低版本在get请求查询的时候会查出所有数据,用post没问题,后来百度发现是elasticsearch-head-master低版本有bug,高版本修复了但是我没有测,我这个网盘里的是有问题的,所以大家get请求查询的时候改成post请求)。
本文实现思路
一、ES下载安装运行
网盘包含:ES安装包、ik分词器、elasticsearch-head-master、kibana
网盘链接:https://pan.baidu.com/s/1_Vfcn0scS3vgZ2qSvc0TUw?pwd=j7f1
提取码:j7f1
1.下载安装ES
下载后解压文件夹,目录如图所示
2.修改配置,启动ES
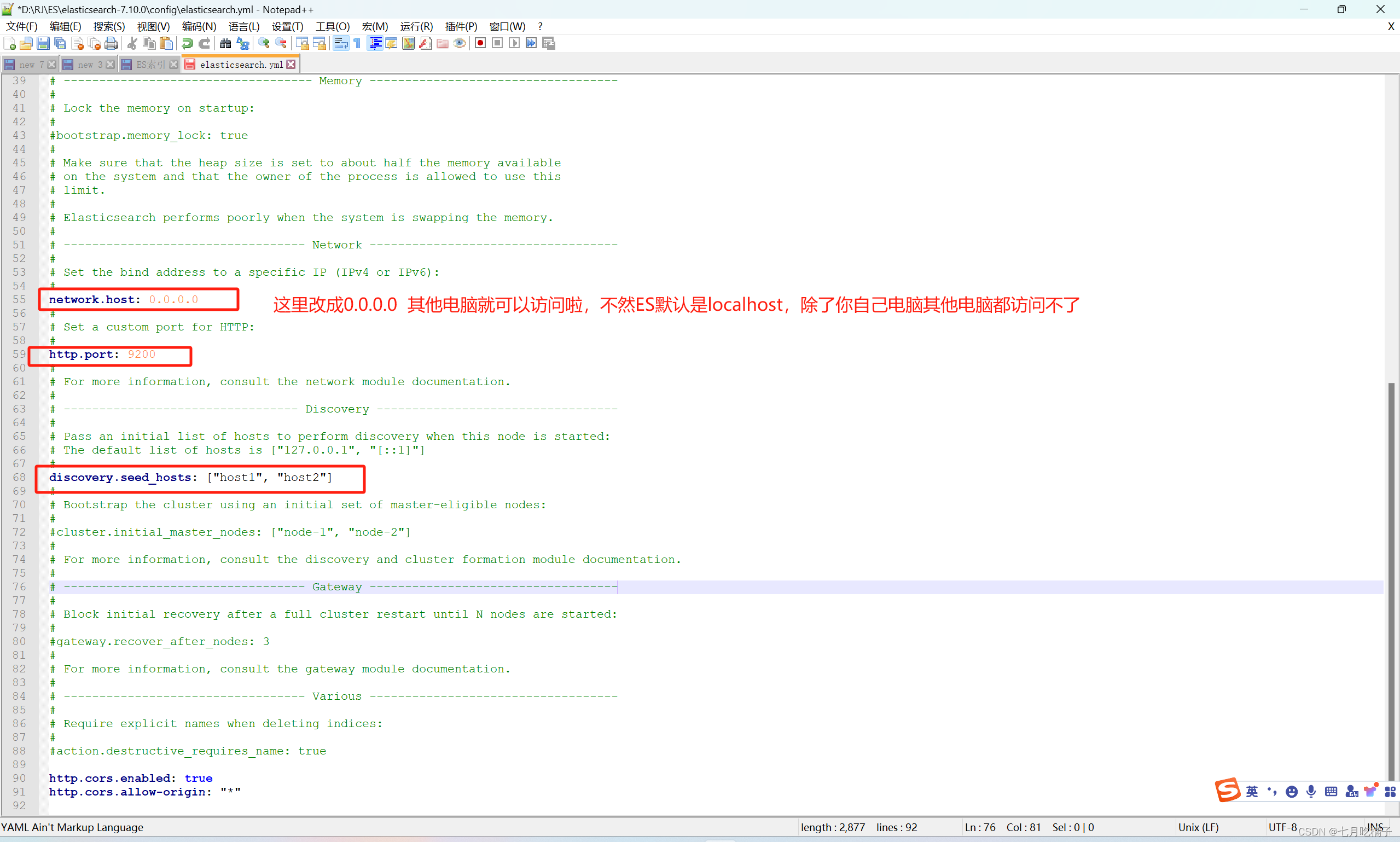
进入到ES的config文件夹下,编辑 elasticsearch.yml 在末尾添加两行配置(该配置是为了不让ES进行签证认证),如果不加这两行配置,也可以去ES官网申请签证但是这个申请的签证是有试用期限的到期了还得重新申请所以我就直接给它过滤掉认证了。
http.cors.enabled: true
http.cors.allow-origin: “*”
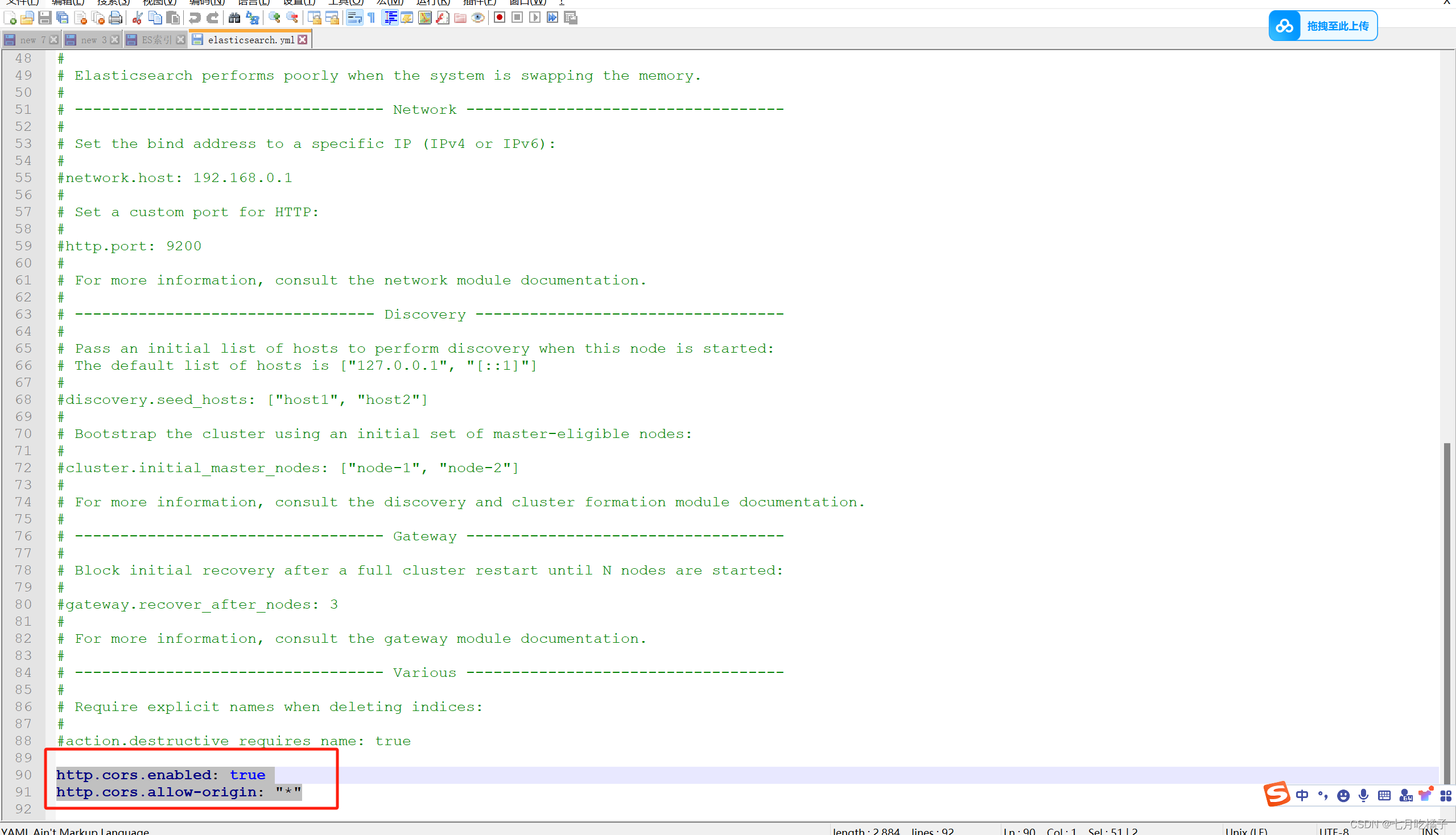
这里再扩充一下后期用到的东西,现在你在自己电脑上访问ES没问题,如果外网其他电脑想连接你的ES,是需要再改一些配置的,还在在该文件里把框红的三个注释解开,不然会访问不到你的ES,因为ES默认是localhost访问,看图配置保存即可。
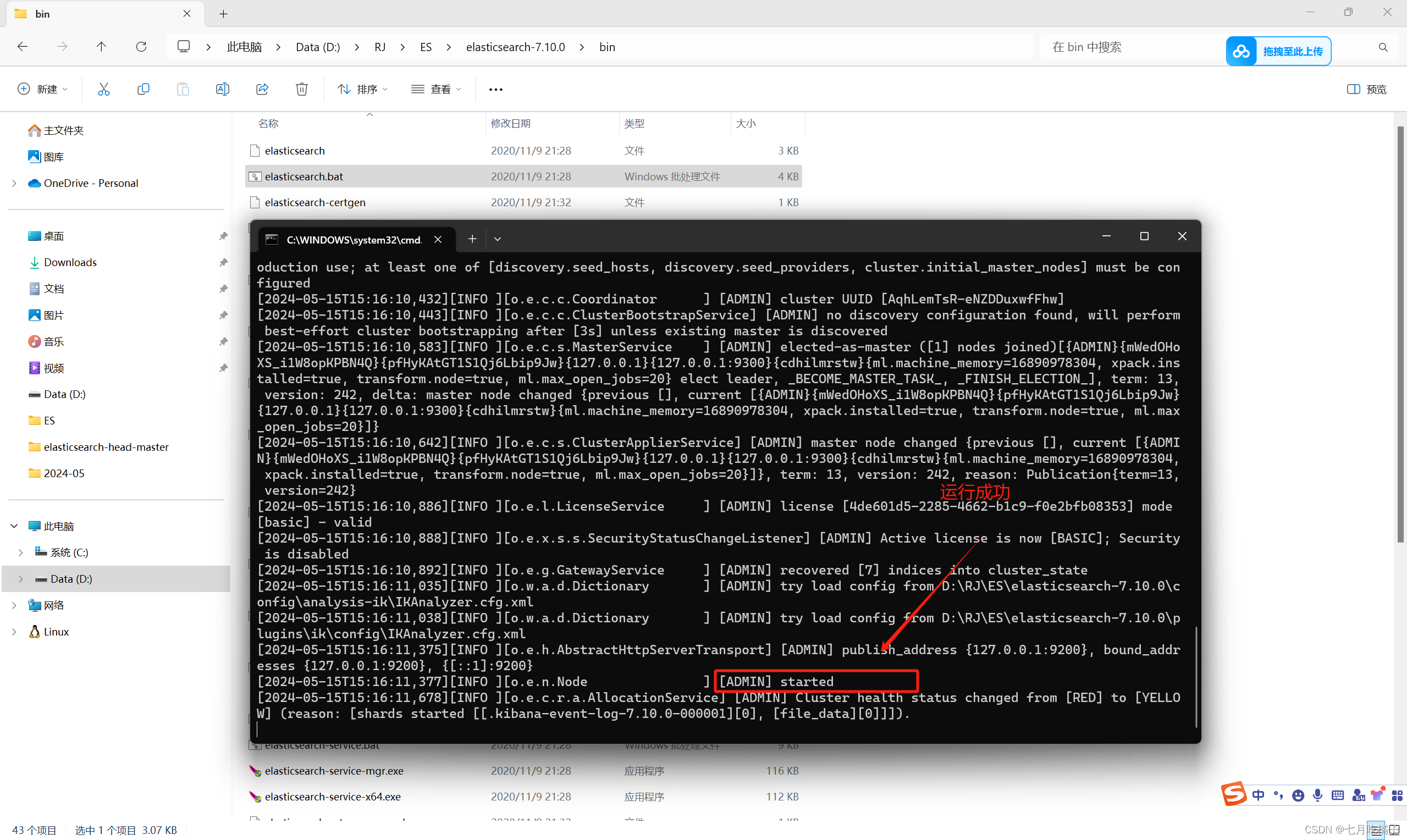
添加完配置后,进入ES的bin目录下,双击elasticsearch.bat,日志中提示started就说明启动成功啦
二、安装ik分词器
1.什么是ik分词器
ps:有人会好奇ik分词器是什么? 主要作用就是用来分词检索,比如 “我爱中国”,会进行粗粒分词和细粒分词,粗粒分词就是 “我爱” “中国”,细粒分词“我” “爱” “中” “国”,大概就是这个意思,想继续深挖的自行百度,我这里就不过多介绍了。后面会主要讲解它的使用方式
2.新建ik文件夹
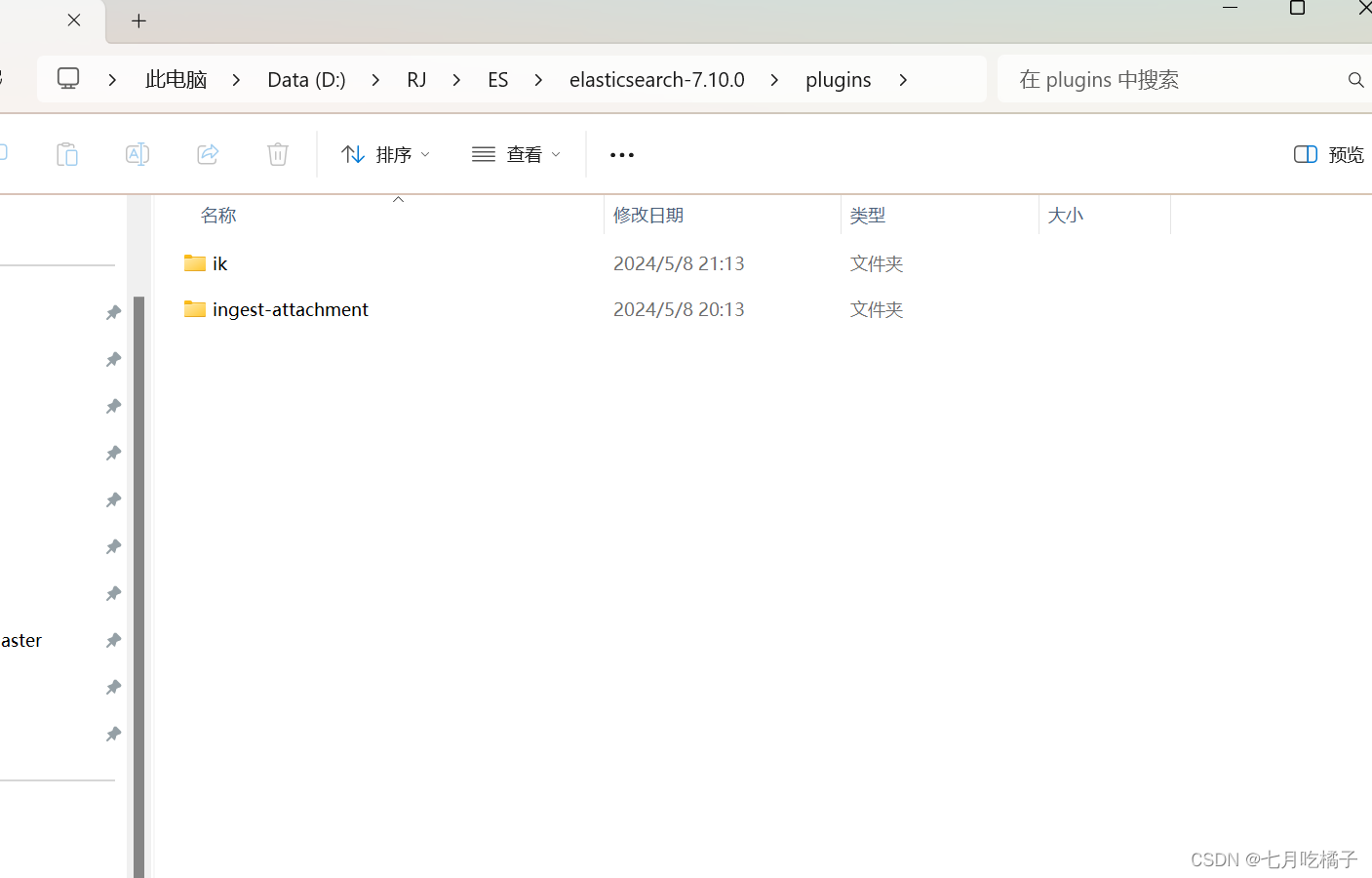
进入到 elasticsearch-7.10.0\plugins 目录下,新建一个文件夹命名为小写 “ik”,这里有一个ingest-attachment文件夹,大家会发现你们没有,对滴!先别急,因为我之前已经装过了!后面我会讲它怎么下载以及作用,目前没有不耽误你们继续跟着文章学习。
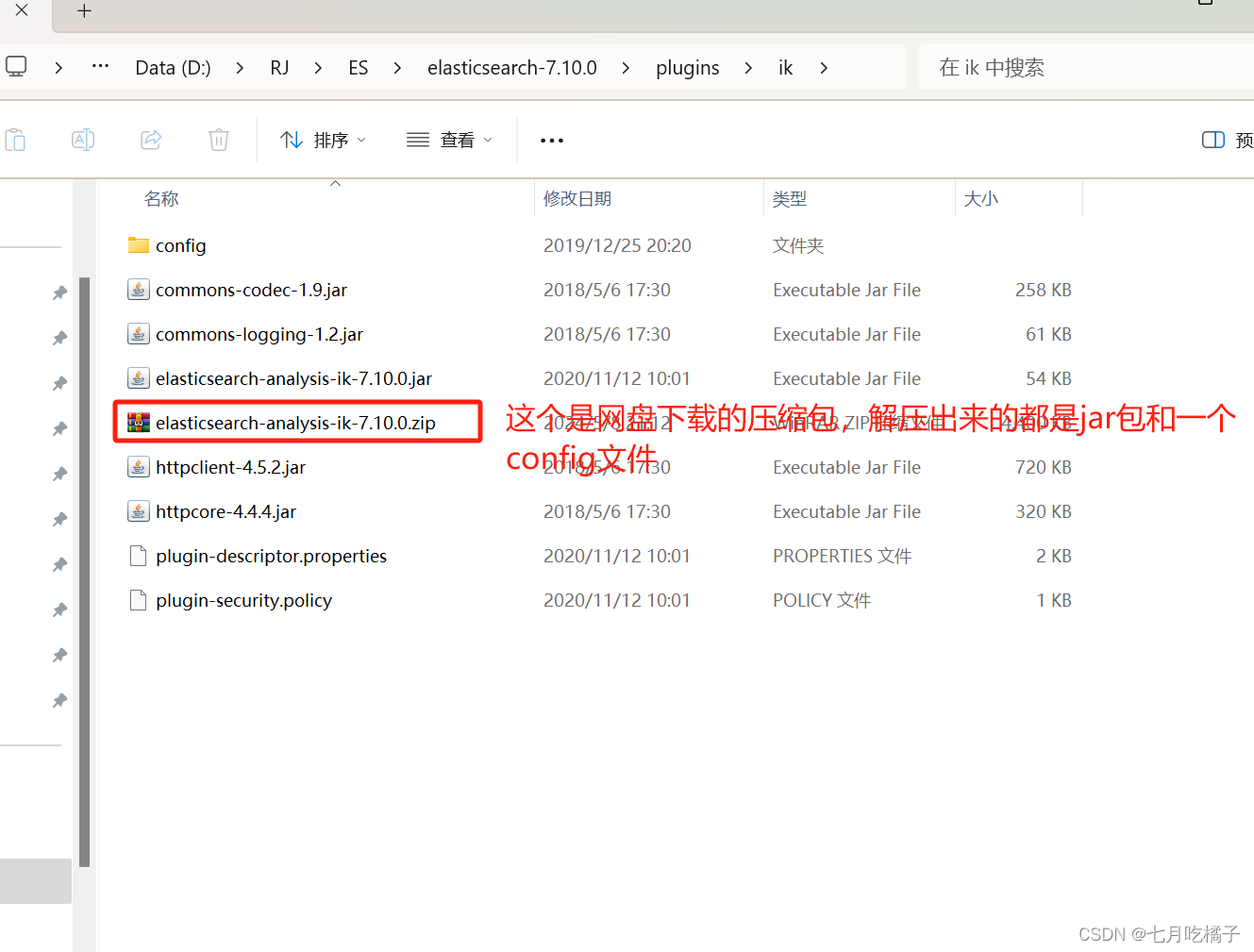
3.解压elasticsearch-analysis-ik-7.10.0.zip
新建完 ik 文件夹后,把网盘中下载的 elasticsearch-analysis-ik-7.10.0.zip 解压到 ik文件夹里面,解压后的内容如下(解压完可以把elasticsearch-analysis-ik-7.10.0.zip删了,删不删无所谓),到这里我们的ik分词器就完成安装了。
三、安装Attachment
1.Attachment 介绍
简单理解就是处理文档的插件 ingest-attachment
Attachment 插件是 Elasticsearch 中的一种插件,允许将各种二进制文件(如PDF、Word文档等)以及它们的内容索引到 Elasticsearch 中。插件使用 Apache Tika 库来解析和提取二进制文件的内容。通过使用 Attachment 插件,可以轻松地在 Elasticsearch 中建立全文搜索功能,而无需事先转换二进制文件为文本。此说明来自:https://blog.csdn.net/lijie0213/article/details/134205963?spm=1001.2014.3001.5506
2.安装Attachment
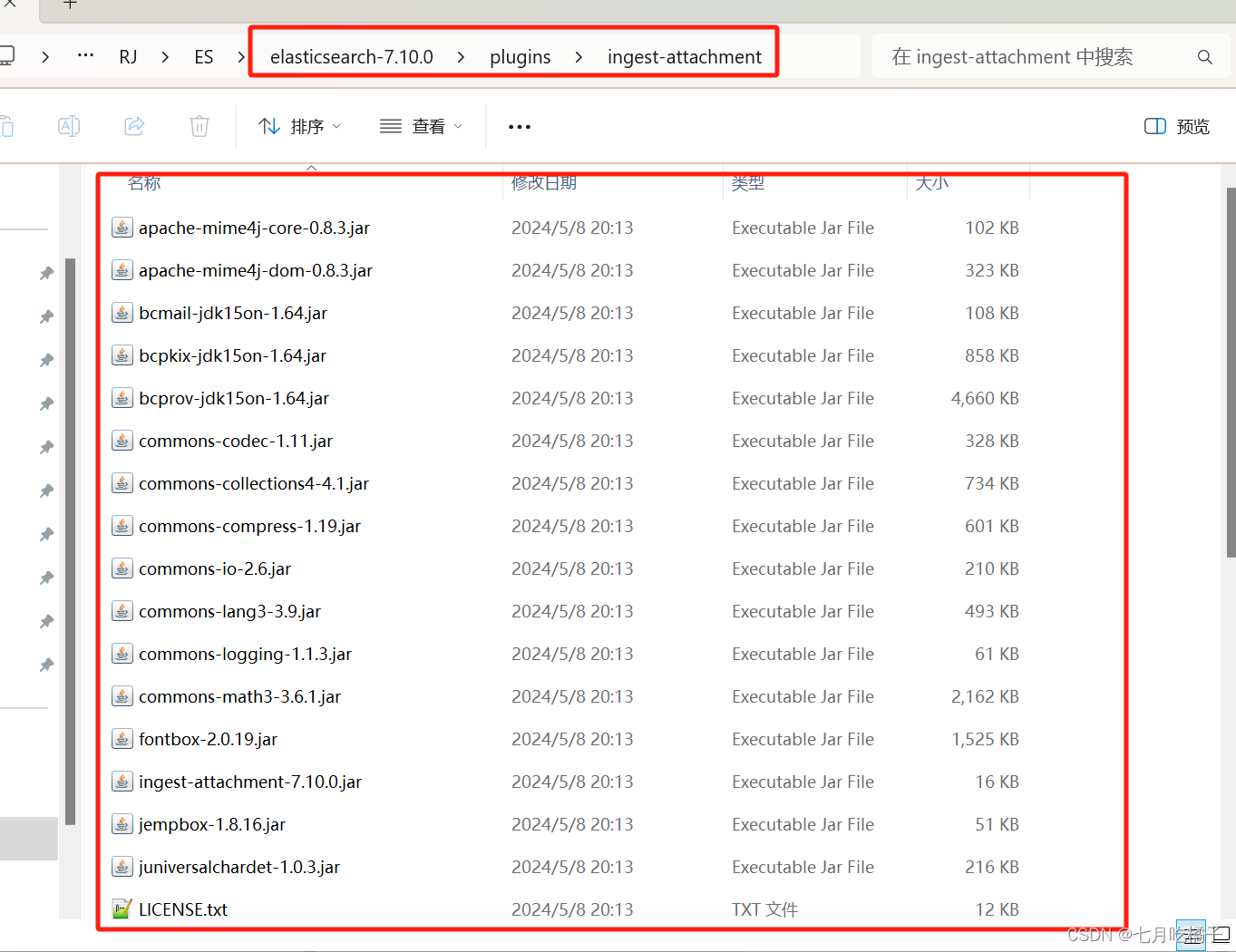
windows安装先在ES的bin目录下执行命令 安装 ngest-attachment插件,刚才不是ik文件夹同级有一个 ingest-attachment,没错!现在我们来安装它!安装完后就是一堆jar包,附图就是安装完成后的样子。
在线安装
在ES的bin目录下执行命令 安装 ngest-attachment插件
elasticsearch-plugin install ingest-attachment
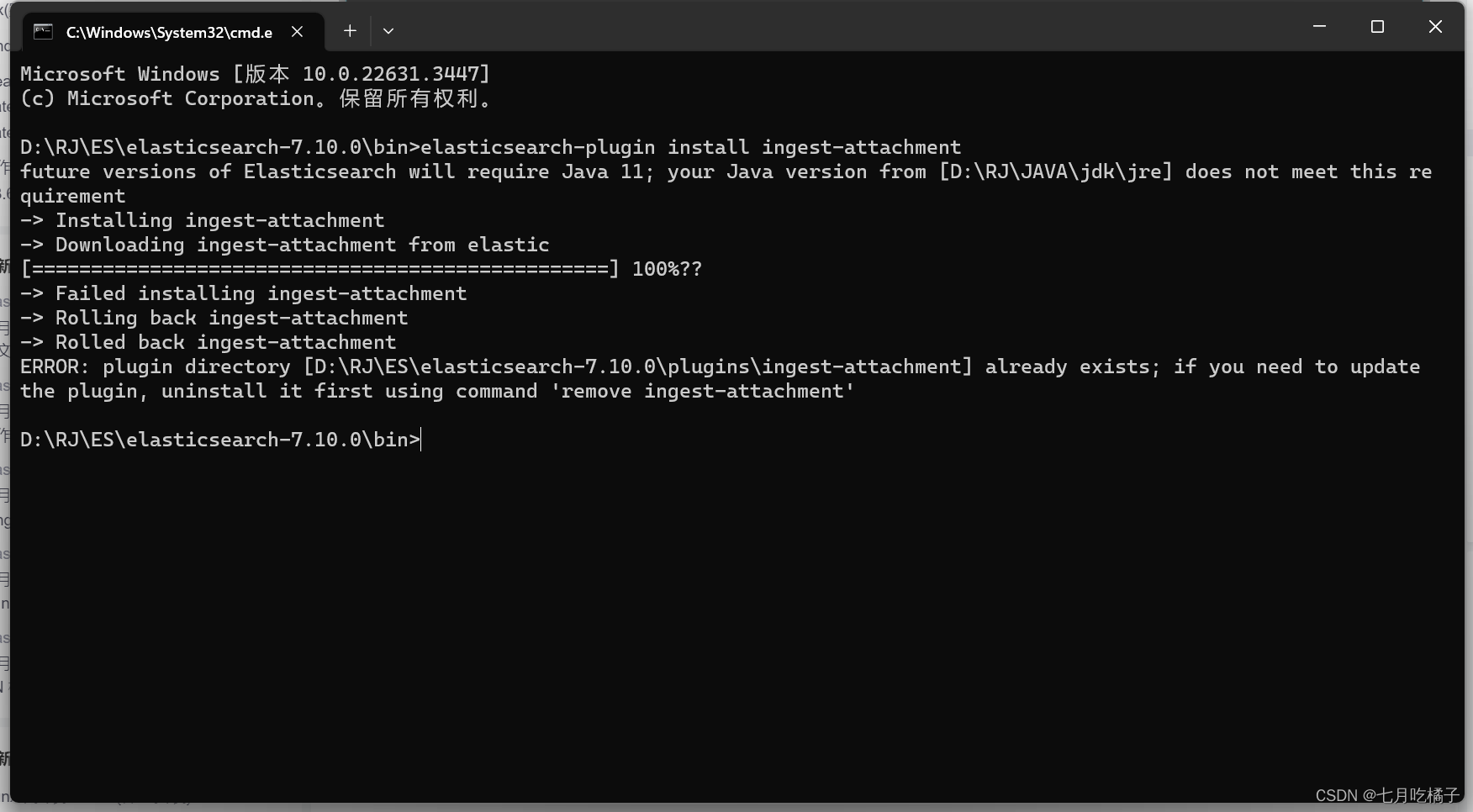
因为我已经下载过了,所以显示的日志会跟你们不一样,正常会有一个让你输入 Y 的提示,安装看不懂的可以看这篇博主的:https://blog.csdn.net/lijie0213/article/details/134205963?spm=1001.2014.3001.5506

离线安装网盘链接:https://pan.baidu.com/s/1RoUrVe_voYSFxnliB6eW3Q?pwd=qkpg
提取码:qkpg
四、安装ES可视化工具elasticsearch-head-master
无话可说,解压进入bin目录下,运行: npm run start
1.启动成功后访问:http://localhost:9100/
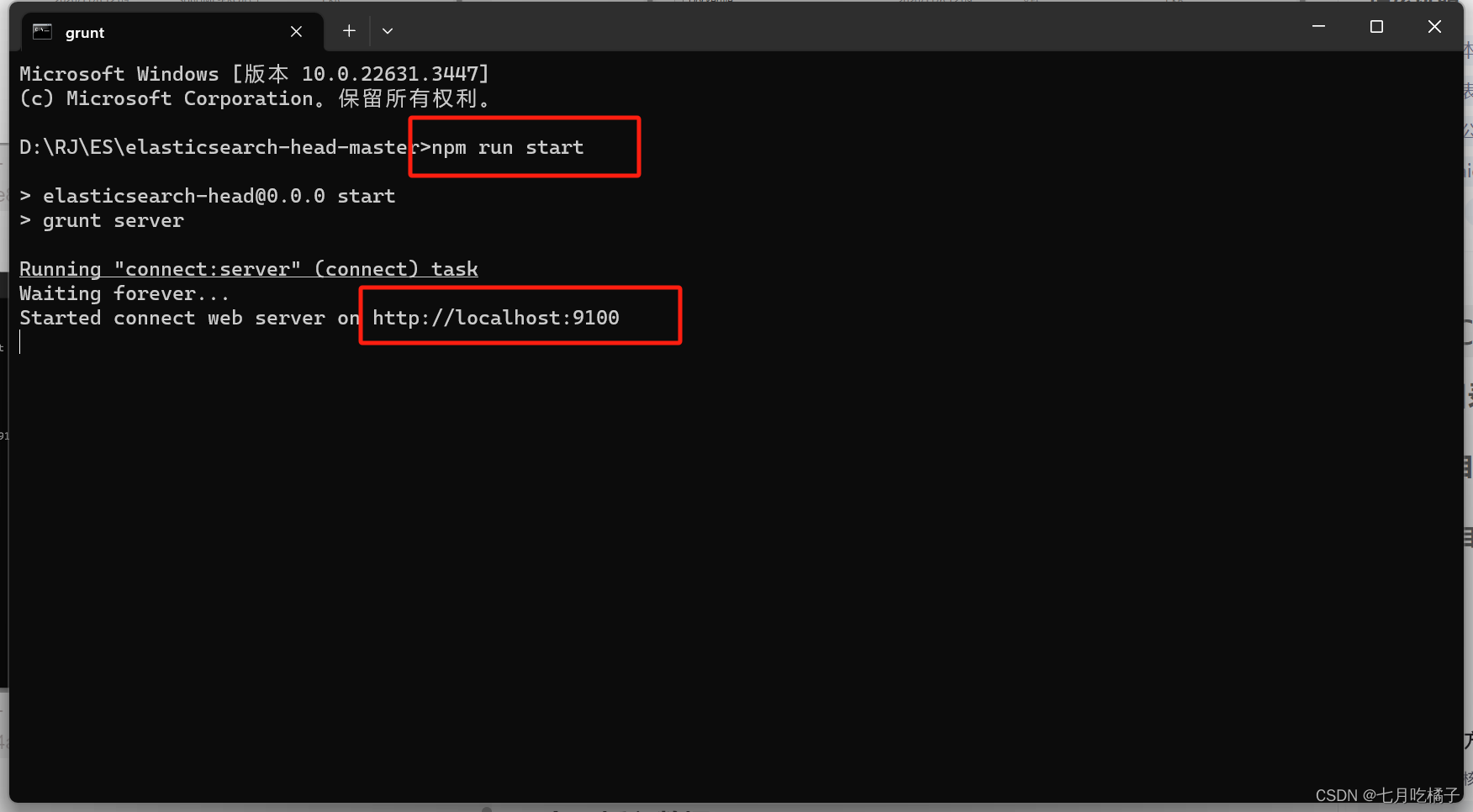
安装启动完成页面
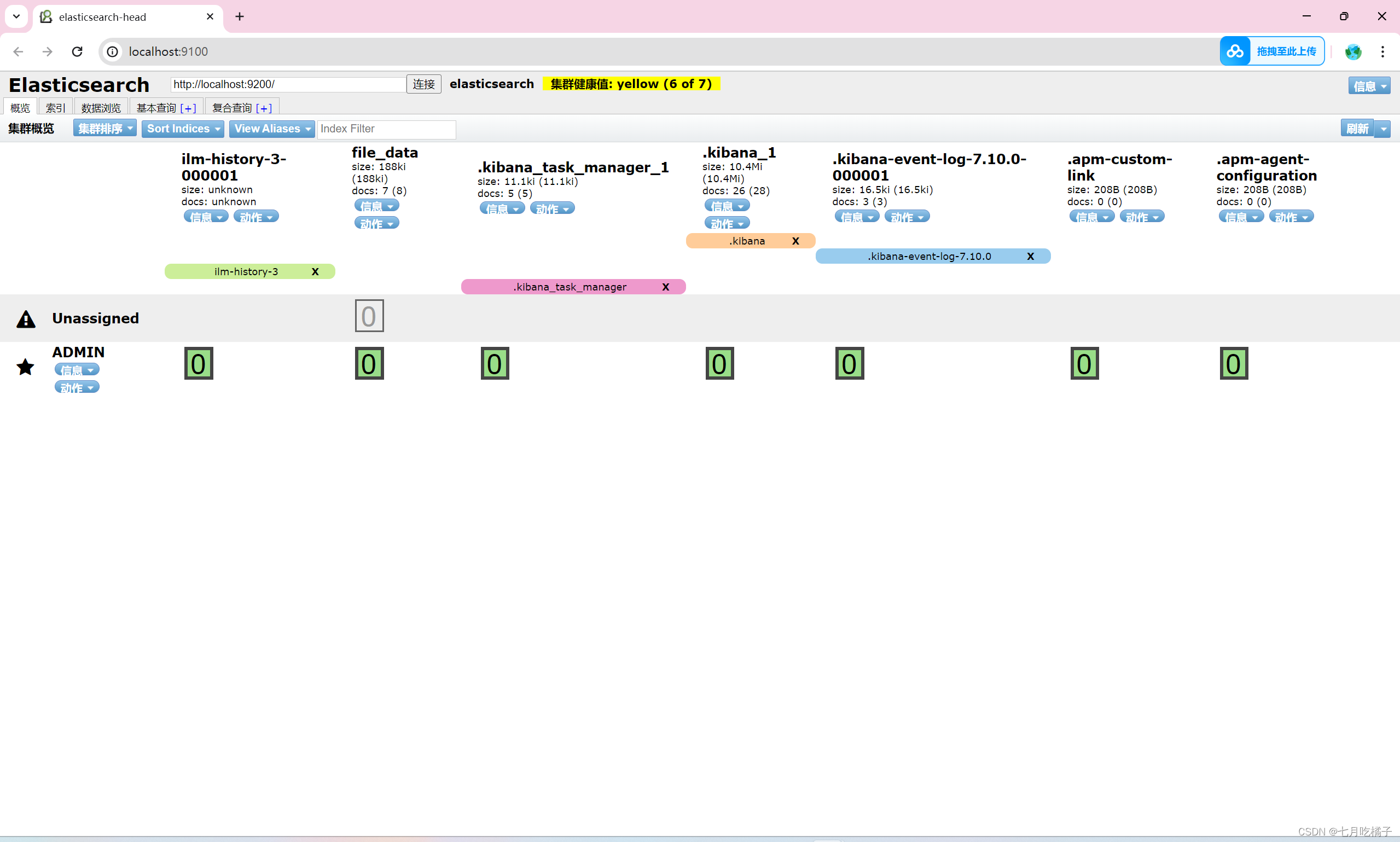
五、定义—文本抽取管道(pipeline)
下列复制粘贴到 elasticsearch-head-master 可视化工具的复合查询选项中
1.请求地址(PUT ):_ingest/pipeline/attachment
{
"description": "Extract attachment information",
"processors": [
{
"attachment": {
"field": "content",
"indexed_chars": 1000000,
"ignore_missing": true
}
},
{
"remove": {
"field": "content"
}
}
]
}

创建管道成功提示:
{
"acknowledged": true
}
六、创建索引
这个时候就可以创建我们自定义的索引了,索引这个东西你要研究的话还是有很多东西需要学的,我这里大概就说一下怎么去用,其他方面的自行百度。
关键词:mappings
mapping是映射,对比MySQL而言,他相当于MySQL的表结构定义。
包括:设置元数据、定义存储字段的类型、分区、副本等设置
关键词:properties 就是用来指定属性,比如下列索引内容中的 file_id,file_name 对应的就是你数据库表的字段,type是类型,keyword和text是ES中的字符串类型,
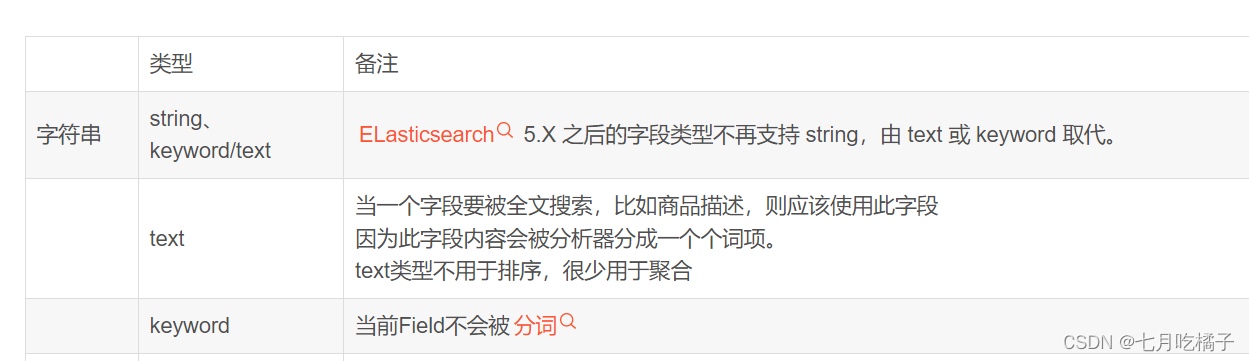
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
1.创建索引
//创建索引
请求类型:PUT
索引名称:file_data(自定义)
{
"mappings": {
"properties": {
"file_id":{
"type": "keyword"
},
"file_name":{
"type": "text",
"analyzer": "ik_max_word"
},
"file_type":{
"type": "keyword"
},
"file_url":{
"type": "keyword"
},
"group_file_id":{
"type": "keyword"
},
"file_suffix":{
"type": "keyword"
},
"file_size":{
"type": "keyword"
},
"file_dir_name":{
"type": "keyword"
},
"attachment": {
"properties": {
"content":{
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
}
七、插入数据
1.插入数据
POST file_data/_doc?pipeline=attachment
{
"file_id":"1",
"file_name":"性能分析排查思路",
"file_type":"pdf",
"file_url":"http://文件存储地址:8080/xxx/docs/raw/master/性能分析与内存问题排查思考.pdf",
"group_file_id":"123456",
"file_suffix":".pdf",
"file_size":"33",
"file_dir_name":"yryy",
"content":"很长很长的base64内容粘贴到这了"
}
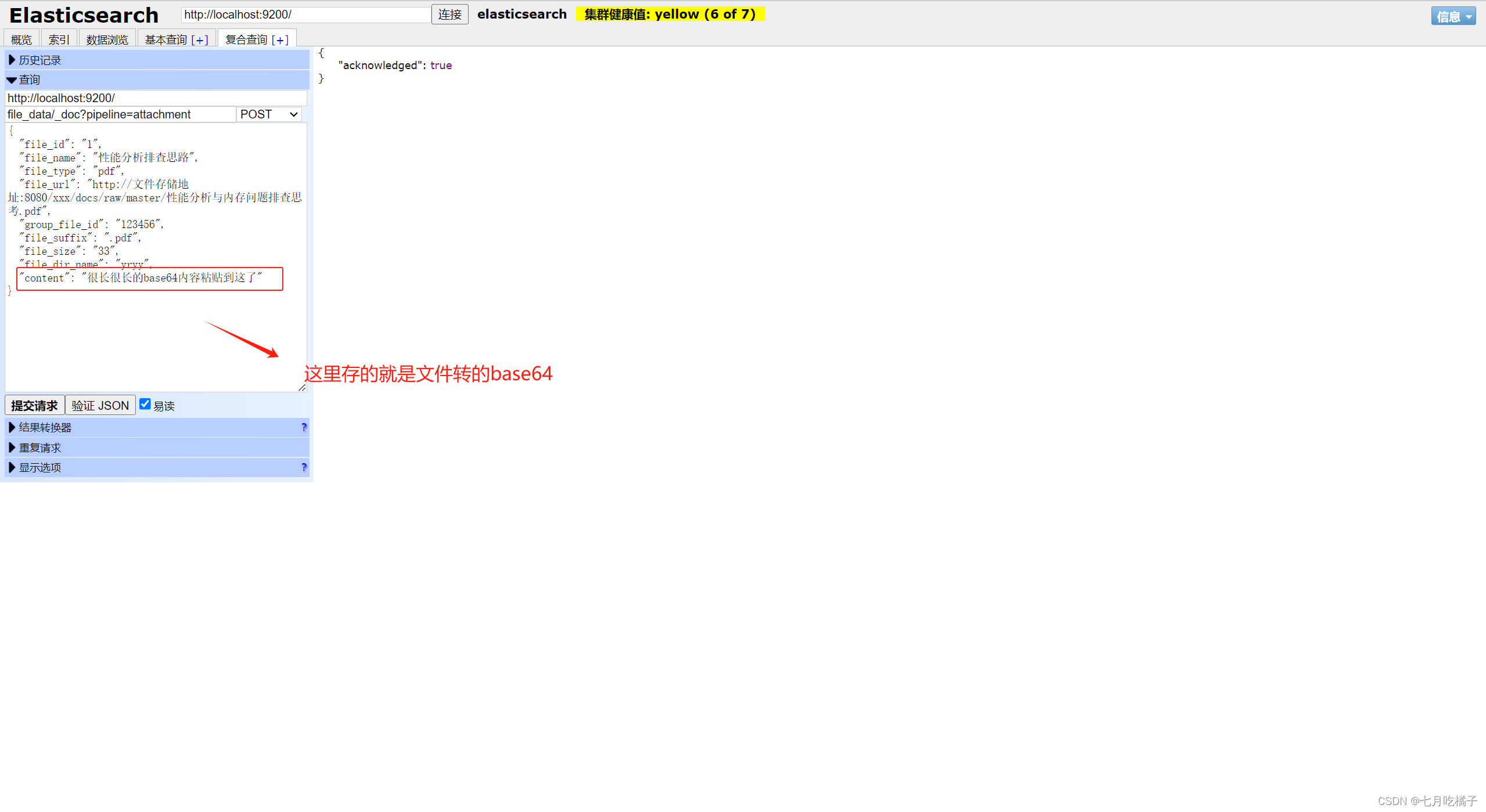
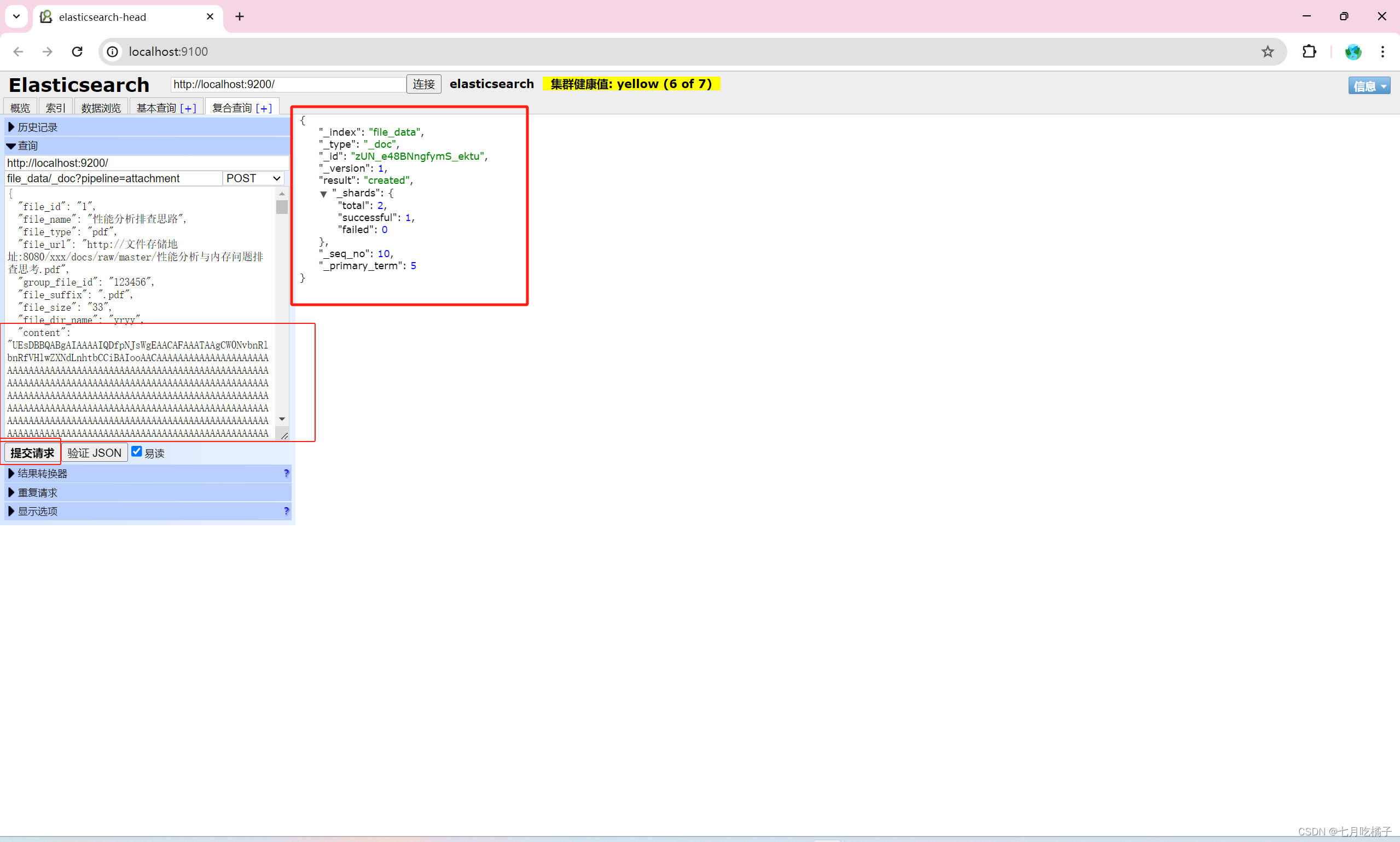
base64就是这玩意,一大长串,你给他扔content里就行了,管道会自动把base64里面的内容提取出来放到ES中,不用你再去做这些处理了。
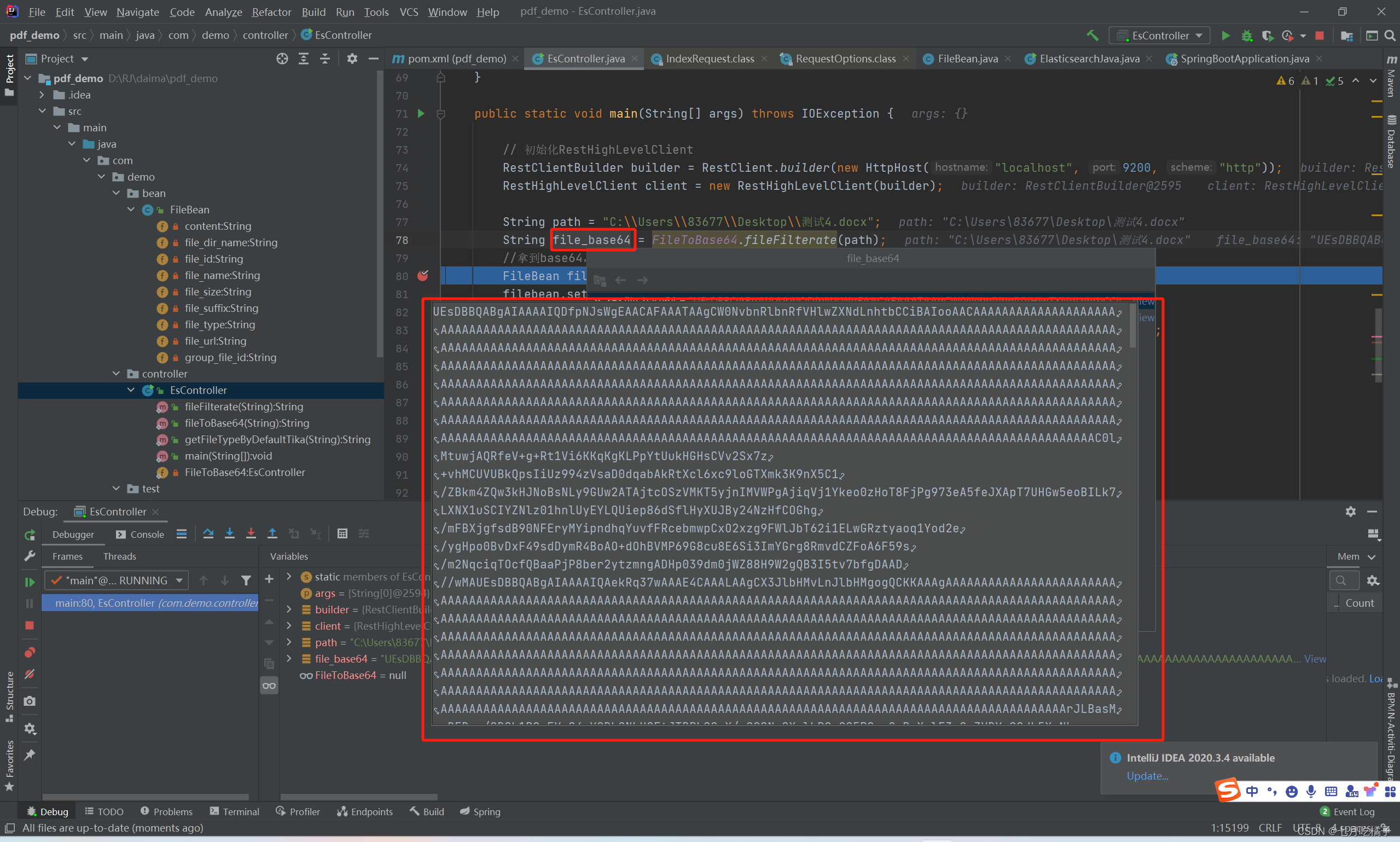
八、查询数据
1.查询数据
POST file_data/_search
{
"query": {
"match": {
"attachment.content": {
"query": "内存泄漏",
"analyzer": "ik_smart"
}
}
}
}
这里提交的时候,注意一下请求方式,ES官方和很多博主说的都是GET请求,但是我得GET请求会查出所有数据,相当于我的查询参数设置没有生效,然后我用POST请求就成功了。这个好像是elasticsearch-head-master可视化工具的BUG,好像高版本已经修复了。
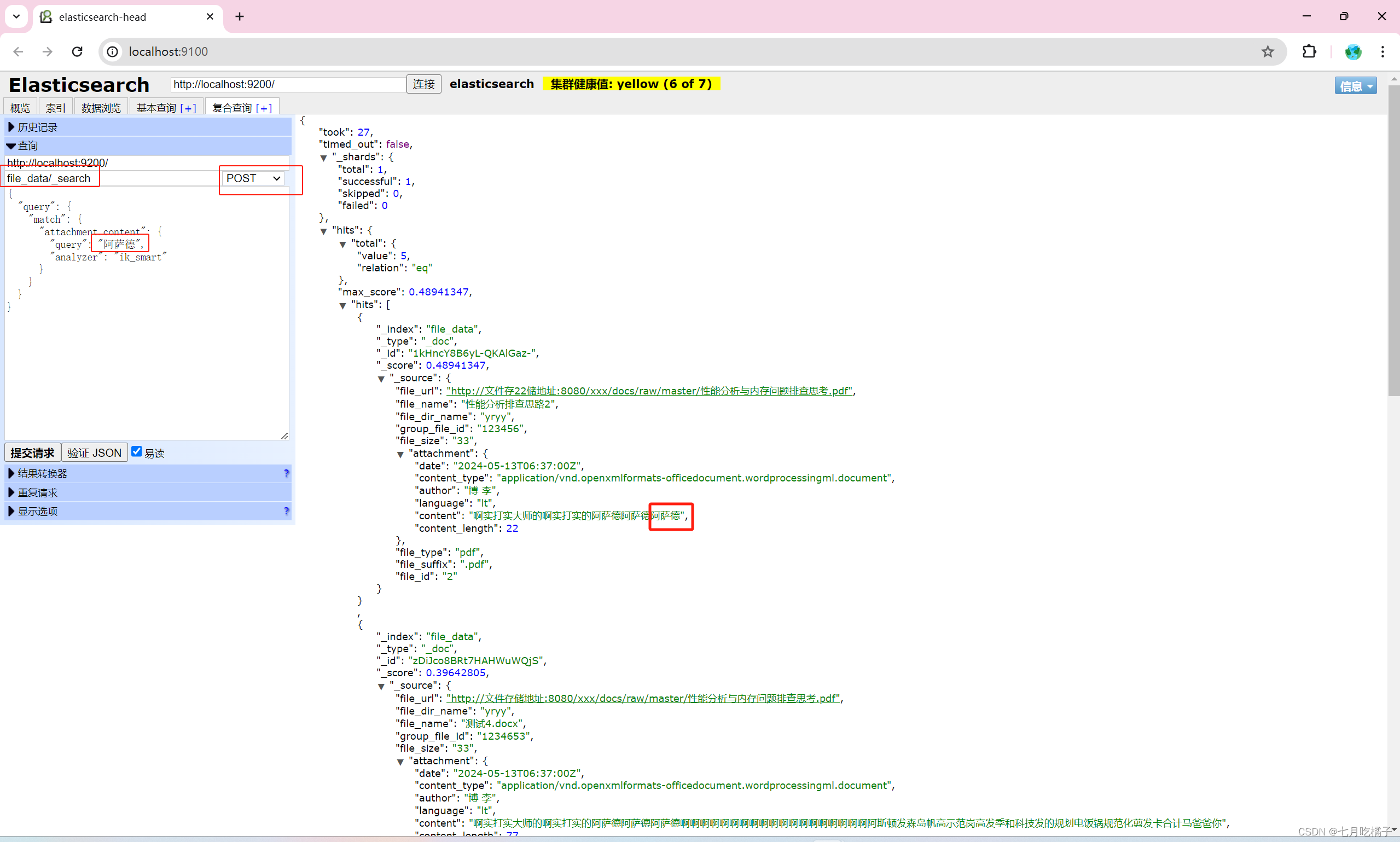
2.多条件查询
上面是我根据文件内容进行的查询,比如我想根据多条件查询怎么办呢?类似于mysql中的 and 条件 where id=1 and name=“文件名称”
{
"query": {
"bool": {
"must": [
{
"match": {
"attachment.content": {
"query": "啊啊啊啊啊",
"analyzer": "ik_smart"
}
}
},
{
"match": {
"file_name": "性能分析排查思路"
}
}
]
}
}
}
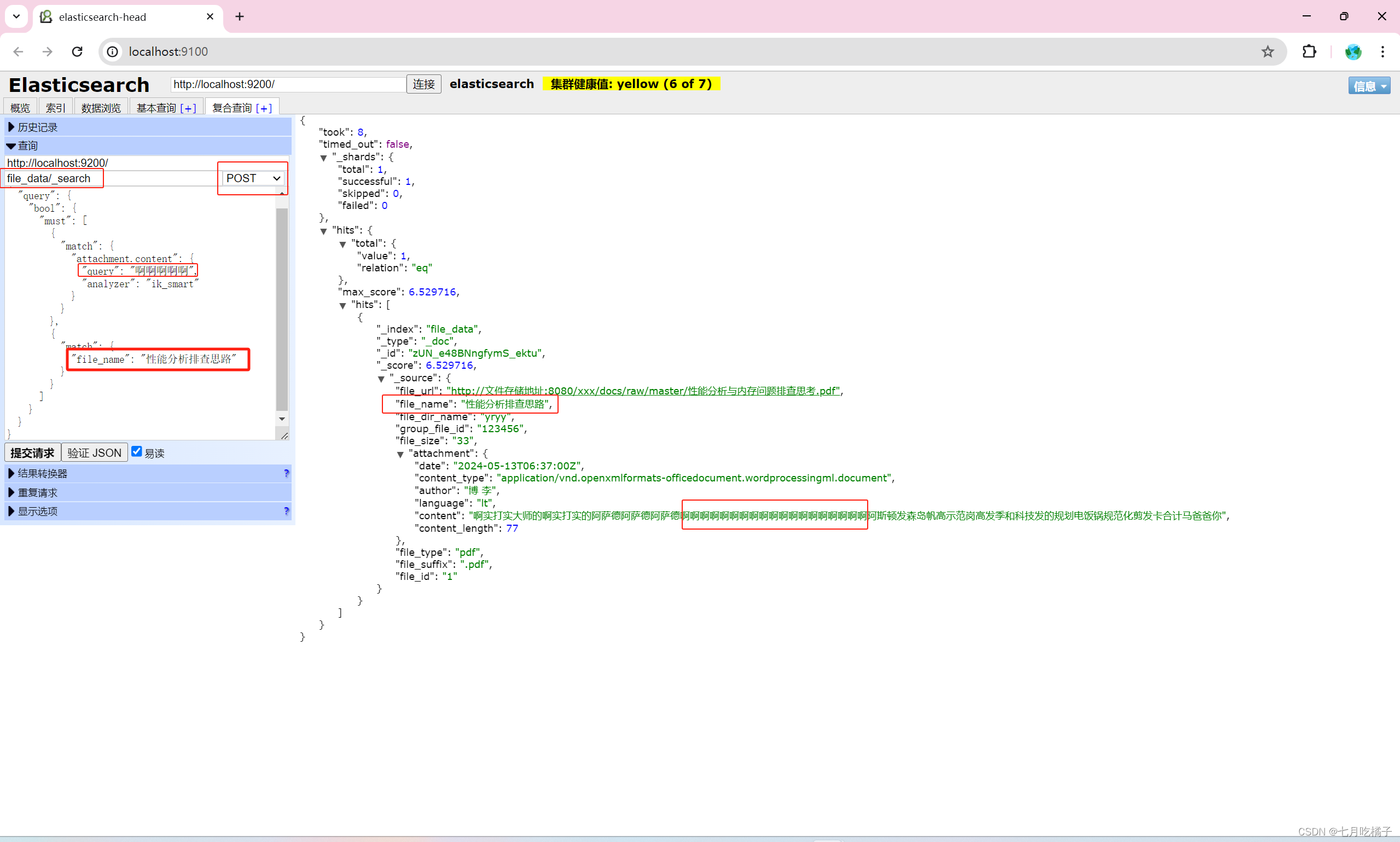
3.精确查询
场景:查询 “我爱中国”,比如我们创建了2个文档,其中一个内容里含有“我爱中国”,另一个文档里只有“中国”,但是查询的时候你会发现ES把两条数据都返回了。
因为我们对内容进行了分词,所以如果想精确查询需要用 match_phrase
强调:es中,match还是精确查询,wildcard 才是模糊查询,因为分词了内容,所以用match_phrase来进行精确查询
match_phrase是什么?它与match的区别?
match_phrase查询是一种用于匹配短语的查询方式,可以用于精确匹配多个单词组成的短语。它会将查询字符串分解成单词,然后按照顺序匹配文档中的单词,只有当文档中的单词顺序与查询字符串中的单词顺序完全一致时才会匹配成功。
与match查询不同,match查询只需要匹配查询中的一个或多个单词,而不需要考虑单词的顺序。例如,如果查询是“abc”,match查询将匹配包含“a”、“b”或“c”的文档,而不管它们的顺序如何。相比之下,match_phrase查询只会匹配包含完全短语“abc”的文档。
因此,match_phrase查询更适合需要精确匹配短语的情况,而match查询更适合需要模糊匹配单词的情况。
POST /file_data/_search
{
"query": {
"match_phrase": {
"attachment.content": {
"query": "我爱中国",
"analyzer": "ik_smart"
}
}
}
}
学习两位博主的文章:
https://blog.csdn.net/yuand7/article/details/136436712?spm=1001.2014.3001.5506
https://blog.csdn.net/lijie0213/article/details/134205963?spm=1001.2014.3001.5506
















 2640
2640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











