






先引出一个问题: 内存和磁盘的 IO 交互效率
1ms = 1000000 nm
交互倍率 CPU -> (10(nm))Cache -> (100nm)RAM -> 机械硬盘(10ms)/固态硬盘(0.1ms -> 1ms)
IO操作和内存操作: 几百万倍 ~ 千万倍差距
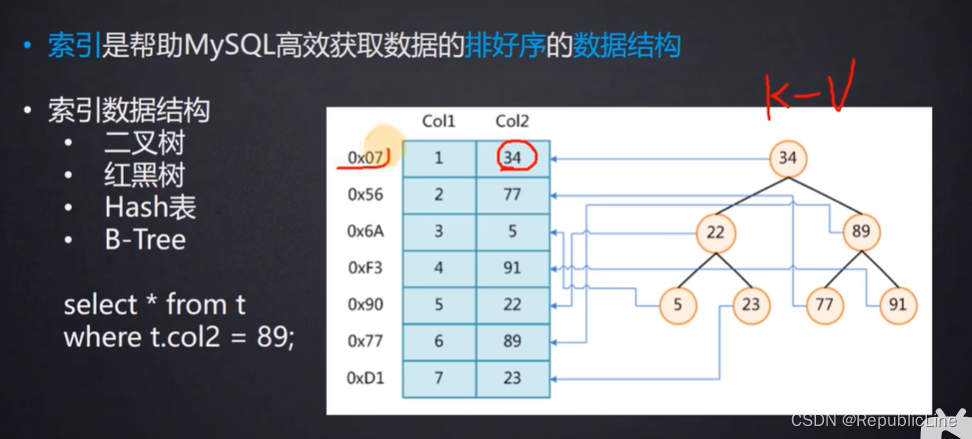
索引:一种高效的排好序的数据结构.
索引定义:
索引:是一种高效的排好序的数据结构. 注意:添加索引字段,索引本身也会作为数据存入磁盘中.
不加索引: 相当于链表结构.需要逐条遍历,查找,数据是存储在磁盘当中的. 也就是遍历的每条数据都需要进行一次I/O交互,效率就低了
二叉树:
这里讨论的问题是添加索引,并使用二叉树作为存储索引的数据结构?
添加索引: K:V K:存储索引字段 V:存储磁盘地址(物理地址)
以二叉树为例: 二叉树左叶子节点数大于父节点,右叶子节点数大于父节点
如果不使用索引: 这里查找到对应的where字句需要进行6次IO交互, 添加索引,并使用二叉树存储索引情况只需要进行两次IO交互.
为什么不使用二叉树存储索引?
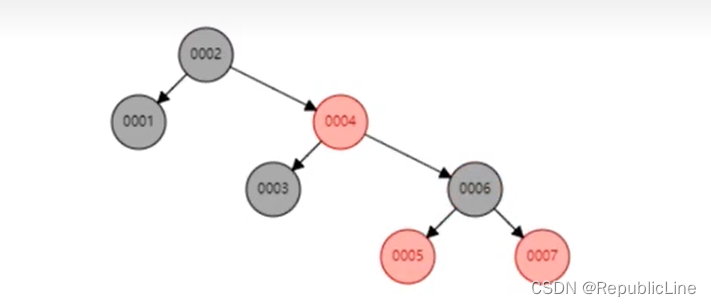
假设字段为自增, 每次插入新的数据之后,对应的更新索引树,都会在右叶子节点添加.该树状结构就会变为链表.等于没加索引 o -> o -> o -> o -> o
二叉树在自增列的场景下没有意义
红黑树:
以上次相似场景举例: 红黑树本质还是二叉树, 自平衡二叉树
自增举例,每次当新增元素时,都会添加到右叶子节点. 然后左旋操作 实现树平衡
红黑树存储索引: 树的高度太高了. 没法控制,数据量越大查询效率越低.
存储500万条数据:
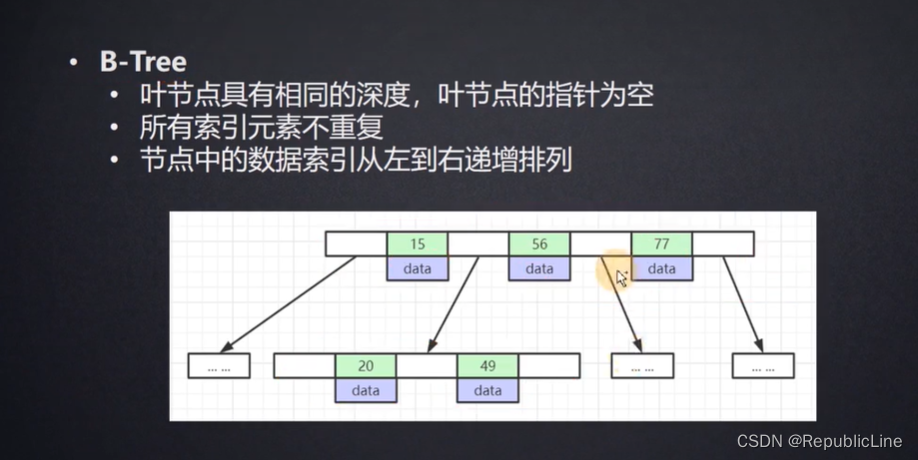
极端情况,数据落在叶子节点,效率会大幅降低 -> 减少树的高度.将树高控制在 3层的样子(多路树),预留索引空间.怎么理解? -> 比如MySql在分配索引时候 0002这条数据. 给索引预留多的空间, 让0003,0004.都可以添加到同一层树的高度上. 并且让每个索引可以分叉-> 即在树的横向上放更多的索引元素
B树: 为了控制树高, 多路树
上述场景下的实现效果:
每段中的空白,存放的是下一层索引元素存储的磁盘地址
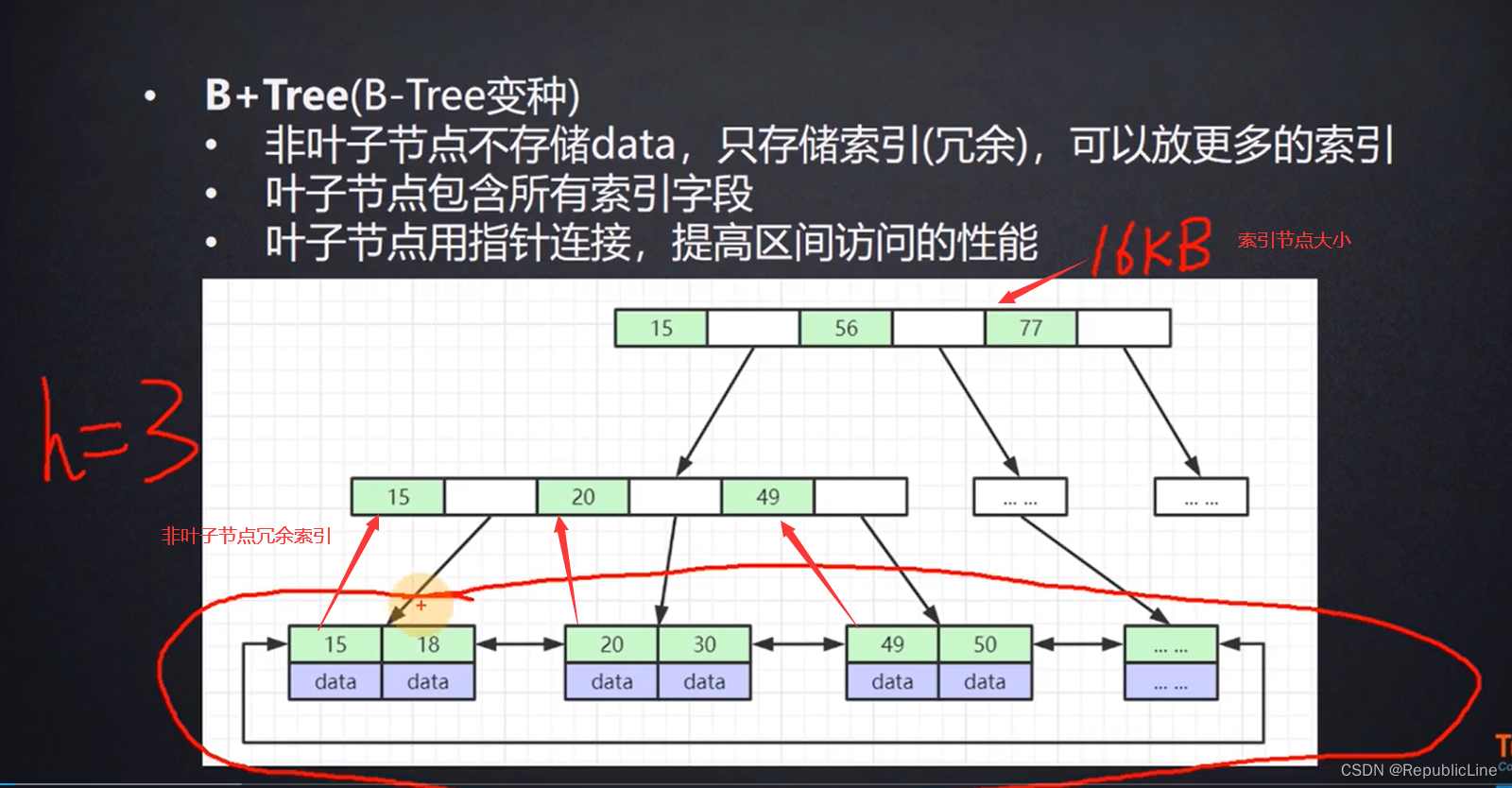
B+树
B树的优化版本. 每段中的空白,存放的是下一层索引元素存储的磁盘地址
页大小: 16KB 1170个叶子节点 非叶子节点: 8字节(索引) + 6字节(下一层叶子节点地址,指针)
- 页除了可以存放
数据(叶子节点),还可以存放健值和指针(非叶子节点),当然他们是有序的。这样的数据组织形式,我们称为索引组织表。
3层树到叶子节点能存多少索引? B+树的存储总记录数 = 根节点指针数 * 单个叶子节点记录条数
能存多少索引 1170(非叶子节点) x 1170 x 16(索引+行数据)
这里给个面子按16算 > InnoDB引擎索引和数据存放在一个文件中
这里提到的“16”可能是指InnoDB设计时的填充因子或者其他优化参数,使得一个页可以实际存放的键值对数量远大于简单的页大小除以单个键值对大小的计算结果。但实际情况中,每一页的具体数据结构还包括其他元信息,如页头、行溢出空间等,所以实际可存放的数据记录数会小于理论上的最大值。
比如定位索引 30 -> 所有的索引元素都是排好序的递增.
将第一层索引加载到内存中, 二分查找 -> 进入下一层索引树,二分查找 -> 进入最后一层精准定位.
对于高版本的MySql来说,冗余索引会提前加载到内存中.
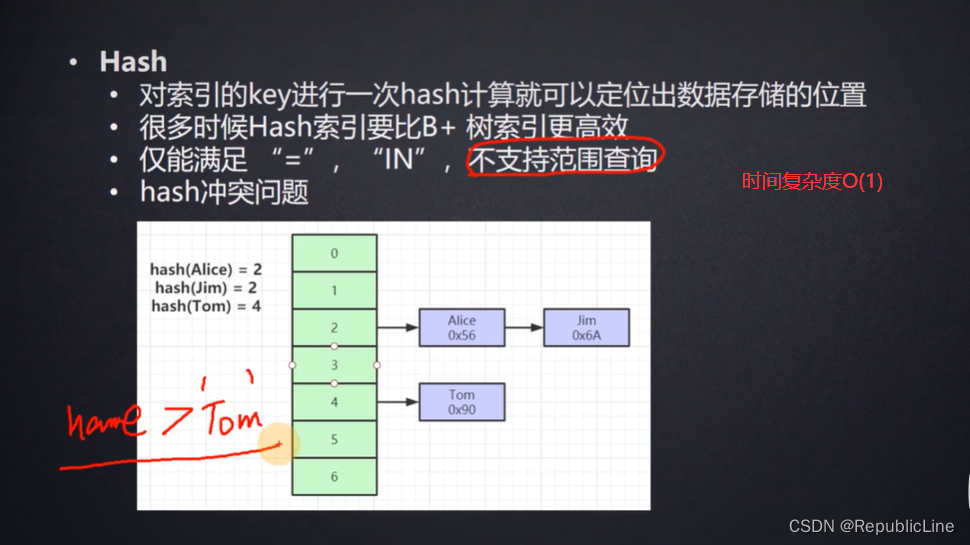
Hash:
对于范围查找 比如 name > ‘Tom’ . Hash 这种数据结构无法做到,就要进行全表扫描.所以不采用这种方案
B+树支持因为 : 非叶子节点 之间 是双向链表的存储结构.并且排序好的.更好的支持范围查找
B树和B+树区别:
B树对于范围查找: 效率低, 没有双向指针.
B树没有冗余索引:
B+树存在很多冗余索引.
插入和删除效率
B+ 树有大量的冗余节点,比如删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点。这样删除非常快。B 树则不同,B 树没有冗余节点,删除节点的时候非常复杂。比如删除根节点 中的数据,可能涉及复杂的树的变形。
B+ 树的插入也是一样,有冗余节点,插入可能存在节点的拆分(如果节点饱和),但是最多只涉及树的一条路径。 B+ 树会自动平衡。
因此,B+ 树的插入和删除效率更高。















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









