







 本文详细介绍了如何配置Hadoop环境,包括worker文件的管理,hadoop-env.sh和core-site.xml、hdfs-site.xml文件的配置,以及JAVA_HOME和HADOOP_HOME的设置。重点讲解了fs.defaultFS和dfs.namenode.*配置项的作用,以及如何安全地更改文件权限和格式化namenode。
本文详细介绍了如何配置Hadoop环境,包括worker文件的管理,hadoop-env.sh和core-site.xml、hdfs-site.xml文件的配置,以及JAVA_HOME和HADOOP_HOME的设置。重点讲解了fs.defaultFS和dfs.namenode.*配置项的作用,以及如何安全地更改文件权限和格式化namenode。
配置work文件
worker文件记录了集群中所有的从节点(DataNode)
进入hadoop安装文件目录中的etc文件中,进入hadoop,本机路径如下
cd /root/hadoop-3.3.1/etc/hadoop/
ll 
vim workers
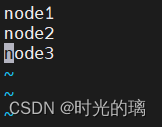
添加集群所有从节点
配置hadoop-env.sh文件
添加如下配置
export JAVA_HOME=/root/jdk-17.0.8
export HADOOP_HOME=/root/hadoop-3.3.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
JAVA_HOME指明JDK环境位置
HADOOP_HOME指明Hadoop安装位置
HADOOP_CONF_DIR指明Hadoop配置文件目录位置
HADOOP_LOG_DIR指明Hadoop运行日志目录位置
配置core-site.xml文件
添加如下配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
fs.defaultFS指明HDFS文件系统的网络通讯路径,协议为hdfs://,namenode为node1,namenode的通讯端口为8020(按照惯例用8020端口)。
总体而言,fs.defaultfs配置指定了Hadoop集群中的命名节点(NameNode)的地址,也就是HDFS(Hadoop分布式文件系统)的主机名和端口号。这个配置项告诉Hadoop客户端应该连接到哪个HDFS集群。通过设置fs.defaultfs配置,Hadoop客户端可以直接使用文件系统API(如HDFS shell、Hadoop streaming等)来进行文件操作,而无需显式地指定HDFS集群的地址。如果没有配置fs.defaultfs,那么在使用文件系统API时,需要手动指定HDFS集群的地址,这会增加使用的复杂性和代码的冗余性。
io.file.buffer.size中io配置了操作文件缓冲区大小。
配置hdfs-site.xml文件
使用vim指令进入hdfs-site.xml文件
配置如下两部分:
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/date/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
dfs.namenode.name.dir含义::NameNode元数据的储存位置,即在node1节点的/data/nn目录下(注意该目录如果原来不存在则需要提前创建)
dfs.namenode.hosts含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/date/dn</value>
</property>
blocksize:默认块大小(256M)
dfs.namenode.handler.count:namenode处理的并发线程数,即100个并线处理线程
dfs.datanode.data.dir:所有从节点DataNode数据储存目录
环境变量配置
配置JAVA和HADOOP的环境变量
vim /etc/profile如图
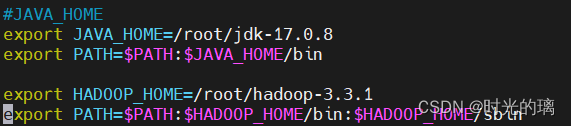
配置环境变量是将其安装目录配置子PATH中,确保系统能正确找到安装目录。系统会在输入命令时自动查找路径中所包含的目录,从而找到对应的命令文件并执行。
如Hadoop可以使用hadoop命令启动Hadoop集群、使用hdfs命令操作分布式文件系统、使用yarn命令管理集群资源等。
Java也有对应的命令
文件修改权限变更命令
因为root权限过大,一般为了安全起见,大数据集群不会以root用户启动,会以创建的一般权限用户用户启动,而在权限变更之前一般用户没有启动权限,这就需要到了权限变更命令
chown -R 用户名:用户名 文件路径
#以root身份执行,例 chown -R hadoop:hadoop /server/data格式化namenode
hadoop namenode -format

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











