







英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。
分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。
在基于字典、词库匹配的分词方法中,又分为正向最大匹配、逆向最大匹配、最大切分、双向匹配。
最大正向匹配法
(MaximumMatchingMethod)通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理…… 如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def load_dict(filename):
word_dict = set()
max_len = 1
f = open(filename)
for line in f:
word = unicode(line.strip(), 'utf-8')
word_dict.add(word)
if len(word) > max_len:
max_len = len(word)
return max_len, word_dict
def fmm_word_seg(sent, max_len, word_dict):
begin = 0
words = []
sent = unicode(sent, 'gbk')
while begin < len(sent):
for end in xrange(begin + max_len, begin, -1):
if sent[begin:end] in word_dict:
words.append(sent[begin:end])
break
begin = end
return words
max_len, word_dict = load_dict('lexicon.dic')
sent = raw_input('Input one sentence')
words = fmm_word_seg(sent, max_len, word_dict)
for word in words:
print word

逆向最大分词
def fmm_word_seg_re(sent, max_len, word_dict):
words = []
sent = unicode(sent, 'gbk')
end = len(sent)
while end > 0:
for begin in xrange(end - max_len, end, 1):
if begin >= 0:
if sent[begin:end] in word_dict:
words.append(sent[begin:end])
break
end = begin
return words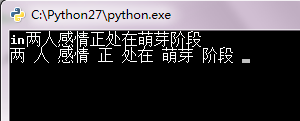















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









